
Navigazione di strutture articolate: cosa significa? Con le lezioni precedenti abbiamo imparato a ricercare elementi per tag, classe ed id ed abbiamo scoperto che il risultato di tali interrogazioni è sempre un oggetto WebElement - se vogliamo recuperare un singolo elemento - o una lista di WebElement se l'interrogazione mira (anche se non riesce) a recuperare più elementi come, ad esempio, tutti quelli che coincidono con una certa classe.
Quello che invece dobbiamo imparare a fare in questa lezione consiste nel navigare all'interno di elementi sfruttando una sorta di ricerca ricorsiva che la stessa classe WebElement mette a disposizione.
Navigare all'interno di elementi
Ad esempio, quante volte ci capiterà di leggere i dati presenti in una struttura come quella mostrata in figura?
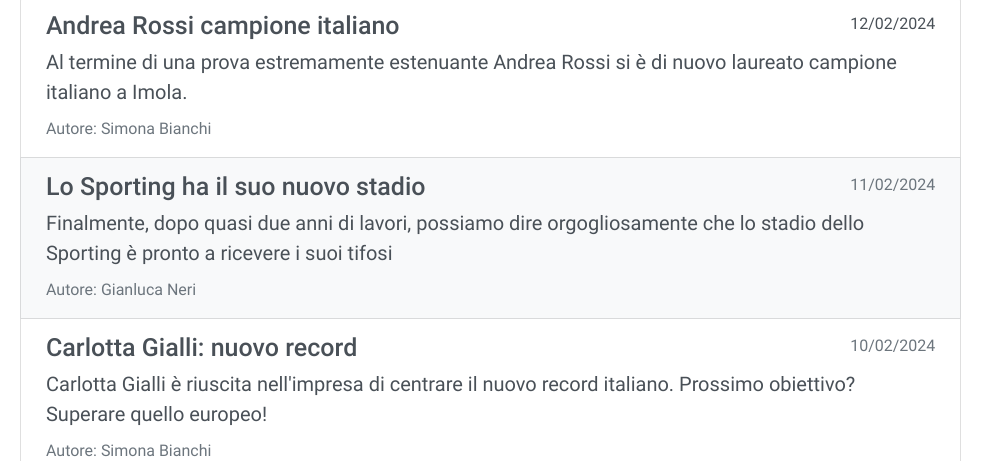
Figura 1. La struttura da analizzare
Molto spesso! Si tratta infatti di un ipotetico portale di notizie. Dovremo saper ispezionare una singola riga senza perdere l'associazione tra i suoi elementi. Se osserviamo infatti il codice HTML che l'ha generato (powered by Bootstrap, framework CSS comunissimo da trovare in pagine web) notiamo che, con quello che sappiamo sinora, potremmo recuperare gli elementi h5 per raccogliere tutti i titoli ma perderemmo il legame che ognuno di essi ha con l'autore del testo, la data di pubblicazione o la relativa descrizione:
<div class="list-group col-md-6 col-md-offset-1" style="margin: auto">
<a href="#" class="list-group-item list-group-item-action flex-column align-items-start">
<div class="d-flex w-100 justify-content-between">
<h5 class="mb-1">Andrea Rossi campione italiano</h5>
<small>12/02/2024</small>
</div>
<p class="mb-1">Al termine di una prova estremamente estenuante Andrea Rossi si è di nuovo laureato campione italiano a Imola.</p>
<small class="text-muted">Autore: Simona Bianchi</small>
</a>
<a href="#" class="list-group-item list-group-item-action flex-column align-items-start">
<div class="d-flex w-100 justify-content-between">
<h5 class="mb-1">Lo Sporting ha il suo nuovo stadio</h5>
<small class="text-muted">11/02/2024</small>
</div>
<p class="mb-1">Finalmente, dopo quasi due anni di lavori, possiamo dire orgogliosamente che lo stadio dello Sporting è pronto a ricevere i suoi tifosi</p>
<small class="text-muted">Autore: Gianluca Neri</small>
</a>
<a href="#" class="list-group-item list-group-item-action flex-column align-items-start">
<div class="d-flex w-100 justify-content-between">
<h5 class="mb-1">Carlotta Gialli: nuovo record</h5>
<small class="text-muted">10/02/2024</small>
</div>
<p class="mb-1">Carlotta Gialli è riuscita nell'impresa di centrare il nuovo record italiano. Prossimo obiettivo? Superare quello europeo!</p>
<small class="text-muted">Autore: Simona Bianchi</small>
</a>
</div>Il codice mostrato può essere provato inserendolo nel body di un comune template Bootstrap.
Raccogliere tutti i dati di una notizia
L'esercizio che ci proponiamo di svolgere consiste nel creare una struttura dati, ad esempio un dizionario Python che raccolga tutti gli elementi relativi alla seconda notizia. Un'attività di questo tipo può essere il preambolo ad un immagazzinamento del testo in un database o in un oggetto JSON per la successiva trasmissione a API remote, tanto per ipotizzare due casi.
Prendiamo il WebElement che rappresenta la seconda notizia. Notiamo che ogni "blocco" che rappresenta una notizia appartiene, tra le altre, alla classe list-group-item e, trattandosi di più elementi, con find_elements possiamo ottenere i relativi oggetti WebElement in una lista. A quel punto basterà il comune indexing tra parentesi quadre per recuperare il secondo elemento, in posizione 1 contata a partire da 0.
tutta_la_lista = driver.find_elements(By.CLASS_NAME, "list-group-item")
seconda_notizia=tutta_la_lista[1]Per fare una prova, prendiamo il titolo (primo elemento in tag h5) dall'oggetto seconda_notizia:
print(seconda_notizia.find_element(By.TAG_NAME, "h5").text)Otteniamo in output il testo "Lo Sporting ha il suo nuovo stadio" pertanto direi che ci siamo! Procediamo con l'esempio completo in cui incameriamo in un dizionario tutta la notizia:
tutta_la_lista = driver.find_elements(By.CLASS_NAME, "list-group-item")
seconda_notizia=tutta_la_lista[1]
notizia={}
notizia['titolo']=seconda_notizia.find_element(By.TAG_NAME, "h5").text
elementi_small=seconda_notizia.find_elements(By.TAG_NAME, "small")
notizia['data']=elementi_small[0].text
notizia['autore']=elementi_small[1].text.replace('Autore:','').strip()
notizia['descrizione']=seconda_notizia.find_element(By.TAG_NAME,"p").text
print(notizia)ed in output abbiamo:
{
'titolo': 'Lo Sporting ha il suo nuovo stadio',
'data': '11/02/2024',
'autore': 'Gianluca Neri',
'descrizione': 'Finalmente, dopo quasi due anni di lavori, possiamo dire orgogliosamente che lo stadio dello Sporting è pronto a ricevere i suoi tifosi'
}Conclusioni: navigazione di strutture articolate e WebElement
Come si vede, non abbiamo fatto altro che navigare all'interno di un WebElement, come siamo abituati a fare all'interno della pagina. Una volta estratto il testo abbiamo a che fare con comuni stringhe Python e a quel punto diventa un normalissimo lavoro di pulizia testo, l'interfacciamento con Selenium è finito.
Unico aspetto un po' particolare che abbiamo avuto da gestire consisteva nei due testi piccoli entrambi etichettati come small ma l'abbiamo semplicemente risolto distinguendoli a livello posizionale. Il primo la data, il secondo l'autore. Abbiamo confidato poi nella stretta formattazione del testo che riportava il nome dell'autore rimuovendo il prefisso Autore: per ripulirlo.
