
Per fare web testing con Selenium dovremo essere dei buoni esploratori di pagine web.
I nostri script Python/Selenium dovranno individuare elementi da contattare nelle pagine web ed interagire con essi leggendone il contenuto o attivando azioni (ad esempio, facendo "click" su un pulsante). Quindi la nostra prima abilità dovrà consistere nel saper indicare inequivocabilmente a quali e quanti elementi stiamo rivolgendo l'azione. Dovremo saper dire, ad esempio, se vogliamo riferirci ad uno specifico pulsante o a una serie di pulsanti. Alla prima riga di una tabella o a tutte le righe della tabella. Su questo non potremo sbagliare!
Struttura degli elementi web
Le pagine web che appaiono in un browser sono sempre formattate in HTML sebbene a volte siano generate da linguaggi di programmazione, framework o tool automatici. Tanto che la loro vera struttura HTML, in alcuni casi, non è mai apparsa nemmeno ai loro autori. Noi però possiamo sapere qual è il codice HTML che ha generato il contenuto che stiamo osservando nel browser e quali sono gli aspetti che caratterizzano ogni elemento che troviamo nella pagina.
Per conoscerli ci basterà usare due comandi, esistenti in ogni browser sebbene chiamati a volte in modo diverso. Essi sono invocabili cliccando con il tasto destro del mouse in qualsiasi punto della pagina. Il comando per visualizzare il sorgente della pagina e quello per ispezionarne gli elementi. La figura seguente li evidenzia nella grafica del browser Chrome ma per gli altri software troveremo più o meno indicazioni simili:
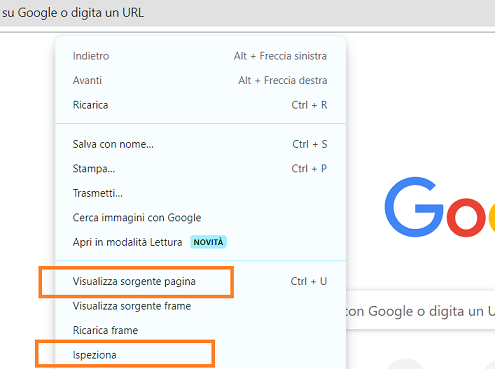
Ricerca di codice sorgente di una pagina web
Utilizzandoli si aprirà, nel caso della visualizzazione del sorgente, una nuova scheda nel browser che mostrerà il codice HTML direttamente. Per l'ispezione sarà disponibile un tool secondario dedicato allo sviluppo web che evidenzierà i singoli elementi della pagina illustrandone il codice e permettendo azioni di debug ed interrogazione. Ciò ci servirà perché dovremo essere in grado di individuare il percorso nella struttura della pagina web in modo da saper spiegare a Selenium come raggiungerli.
Per chi non fosse avvezzo al linguaggio HTML, diciamo subito che un elemento in tale formato è spesso costituito da alcune parti:
- il tag ovvero la parola chiave HTML che genera l'elemento come
inputper un campo di un form,tdper la cella di una tabella,divper fare da contenitore e così via; - gli attributi, proprietà impostate tipicamente nel formato chiave/valore, che accompagnano il tag e ne specificano caratteristiche come stile, comportamento, identificativo;
- id e classi che tecnicamente sono attributi ma, come vedremo, sono fondamentali nella struttura degli elementi e indispensabili per aiutarci a spiegare a Selenium come individuare gli elementi che li possiedono;
- il valore che è tipicamente ciò che viene mostrato all'utente.
Facciamo un esempio. Prendiamo un collegamento ipertestuale, o "link", ovvero uno di quegli elementi su cui l'utente clicca con il mouse affinché la sua navigazione sia rimandata ad un'altra pagina.
<a href="paginadacontattare.html" id="link1" class="linknuovarisorsa">clicca qui!</a>Al suo interno troviamo:
- il tag HTML
ache ci dice che questo è un collegamento ipertestuale; - l'attributo
hrefdi valorepaginadacontattare.htmlche ci dice dove verremo rediretti se cliccheremo il link; - l'id di valore
link1che fornisce l'identificativo univoco che in tutta la pagina ci farà riconoscere questo elemento (gli id dovrebbero sempre essere univoci!); - la classe
linknuovarisorsache associa uno o più elementi nella pagina tipicamente per associare degli stili. Attenzione: il valore dell'attributoclassindica molto spesso più classi; - il valore ovvero cosa mostrerà il collegamento ipertestuale, in questo caso, a "clicca qui!".
Come procedere all'identificazione di elementi
Quando lavoriamo con Selenium, dovremo intanto scegliere l'elemento o gli elementi da contattare utilizzando il metodo find_element (per un singolo elemento) o find_elements per avere una lista di elementi. Dovremo poi scegliere come individuare i nostri obiettivi utilizzando uno dei valori offerti dalla classe By in selenium.webdriver.common.by che, mediante costanti, permette di scegliere tra una delle seguenti strategie di ricerca:
CLASS_NAMEdove indichiamo la classe degli elementi da individuare. Ideale per la ricerca di più elementi della stessa classe;IDcon cui specificheremo l'identificativo univoco dell'elemento, ideale per indirizzare un singolo elemento con id;TAGper trovare tutti gli elementi con lo stesso tag HTML;NAMEche richiede l'attributonameper gli elementi che ne sono dotati. Molto comodo per i campi form;LINK_TEXTper ricercare un link per ciò che appare nel collegamento (deve esserci corrispondenza esatta!) oPARTIAL_LINK_TEXTper cercare una parte del testo del link;CSS_SELECTORper indicare un percorso tra i selettori CSS. Pratica che conosce bene chi sviluppa lato client;XPATHper esprimere i propri obiettivi con una query XPath. Tecnica molto potente cui dedicheremo lezioni nel seguito della guida.
Quale tecnica di ricerca scegliere?
In buona parte, si può procedere per preferenze personali o esperienze pregresse. Soprattutto se, ad esempio, si è lavorato molto con selettori CSS o XPath. Ma in generale si potrebbe esprimere un ordine di priorità:
- se si cerca un singolo elemento con ID, procedere decisamente in base all'identificativo;
- se si cercano più elementi si potrebbe ricorrere al tag ma con il rischio di trovare troppi elementi di cui molti non desiderati. In tali casi procedere con la ricerca per classe può essere più fruttuoso e soprattutto perché spesso le classi associano all'elemento uno stile estetico che rende gli elementi più riconoscibili e affini tra loro;
- se la situazione si complica e i casi precedenti non bastano ad individuare tutti e solo gli elementi necessari, conviene ricorrere all'espressività di selettori CSS e XPath. Si consideri però che se non si ha esperienza in questi campi sarà necessaria una fase di studio preliminare.
Gli altri casi con name e testo dei link possono essere molto utili se gli elementi HTML da cercare ci sono propizi. Ma non sempre capita.
Una delle prime difficoltà che si incontrerà sarà la navigazione in strutture articolate come "trovare il secondo link, all'interno di ogni riga di una lista" o cose simili. Tra gli strumenti che abbiamo elencato c'è comunque tutto ciò che ci potrà servire. E' il momento di passare alla sperimentazione pratica ma lo faremo nella prossima lezione.
