
Matplotlib è sicuramente una delle librerie di visualizzazione più utilizzate al mondo. Contiene moltissime
funzionalità e tutti gli strumenti di cui il data scientist può avere bisogno. Eppure, negli anni, si è affermato un altro protagonista che ha guadagnato grande fama: Seaborn, il tema di
questa lezione. In generale, Seaborn svetta per alcune caratteristiche tra cui:
- un tocco grafico particolarmente moderno. Sappiamo che i grafici sono molto utili per avere un approccio immediato alle informazioni e poterle "vedere" in maniera chiara piuttosto che
racchiuse in tabelle testuali. Tali rappresentazioni vengono sfruttate non solo da tecnici ma anche da persone appartenenti ad altri settori come il marketing, l'ambito commerciale o dirigenziale
spesso abituati a visualizzazioni dai toni più vivaci rispetto a quelli classici di Matplotlib: Seaborn offre con pochi tocchi una veste che può soddisfare utenza di ogni estrazione; - una sintassi più snella. Utilizzando Seaborn si viene spesso colpiti dalla sua intuitività richiedendo in genere un DataFrame Pandas, qualche indicazione sulle colonne da impiegare e rapidamente appare tutto ciò che da
essi si può evincere; - tipologie di grafici che mettono il data scientist in condizioni di conoscere rapidamente aspetti interessanti delle distribuzioni di dati, pensiamo ad esempio a
pairplotche incrocia tra loro
instantaneamente tutte le colonne di un DataFrame eheatmap, una tabella colorata molto utilizzata per evidenziare correlazioni. Conosceremo entrambe a breve.
Installazione di Seaborn
Seaborn viene messo a disposizione da Anaconda ma volendo possiamo installarla in un nostro
ambiente di lavoro mediante i classici package manager di Python passando:
- per il Python Package Index tramite
pip:pip install seaborn - per il client
condacon:conda install -c anaconda seaborn
Una volta messo a disposizione del proprio ambiente di lavoro si può iniziare ad utilizzarlo.
Plot e scatter
Per prima cosa, vediamolo al lavoro sui grafici più classici: linee e punti. Seaborn è caratterizzato da un feeling particolare con i DataFrame Pandas, molto usati nella Data Science. In genere,
sarà sufficiente fornire il nome della struttura contenente i dati in un parametro denominato data ed indicare quali colonne vogliamo vedere rappresentate. Per i nostri esempi,
useremo dei DataFrame già pronti, ispirati a classici dataset per la sperimentazione e la didattica. Potremo caricarli con il metodo load_dataset specificando uno dei nomi indicati
nel repository GitHub di Seaborn.
Proviamo tips riguardante dati riferiti a mance ricevute dal personale durante pasti serviti in un ristorante:
import seaborn as sb
tips=sb.load_dataset("tips")Ecco un campione dei suoi dati ottenuto con tips.head():
total_bill tip sex smoker day time size
0 16.99 1.01 Female No Sun Dinner 2
1 10.34 1.66 Male No Sun Dinner 3
2 21.01 3.50 Male No Sun Dinner 3
3 23.68 3.31 Male No Sun Dinner 2
4 24.59 3.61 Female No Sun Dinner 4Ogni mancia è associata all'importo del conto, il sesso del cliente, il tipo di pasto (Dinner o Launch) e altri dati. Iniziamo a vedere un grafico a punti, uno scatter plot:
import seaborn as sb
tips = sb.load_dataset("tips")
sb.scatterplot(x="tip", y="total_bill", hue="time", data=tips)Il risultato che otteniamo è questo:
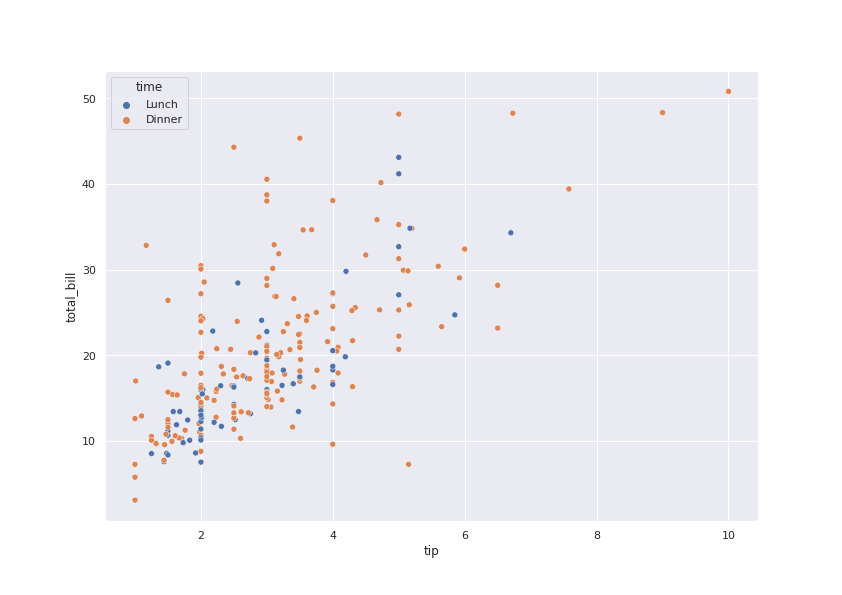
Con i parametri x e y abbiamo indicato quali valori usare per ascisse ed ordinate mentre con hue abbiamo specificato che
in base al valore contenenuto nel campo time ogni punto dovrà assumere un colore diverso. In questo modo, non solo Seaborn ha permesso di visualizzare in maniera molto chiara i valori
ma ha anche associato una legenda automaticamente. Oltre a hue possiamo fare un'ulteriore distinzione con style che si occuperà di cambiare la forma di ogni punto in base
ai possibili valori disponibili in un ulteriore campo che indicheremo. Ad esempio, lo scatter seguente mostrerà i punti nella stessa posizione del precedente ma questi avranno colori diversi
in base al tipo di pasto e forma diversa in base al giorno della settimana (con il parametro s ne fissiamo la dimensione):
import seaborn as sb
tips = sb.load_dataset("tips")
sb.scatterplot(y="total_bill", x="tip", hue="time", style='day',data=tips, s=100)Ecco qui:
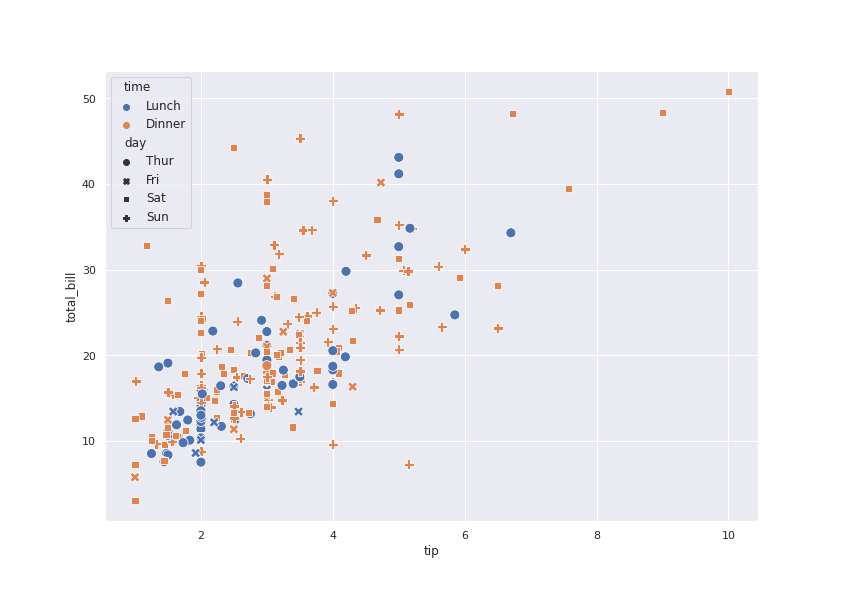
Per visualizzare i dati con delle linee, si può usare il lineplot. Seaborn, nel caso di più valori delle ordinate per singole ascisse, si preoccuperà di renderci comunque un'idea chiara
dell'andamento tracciando un'area della loro dispersione con le cosiddette error bands. Osserviamo il seguente esempio:
sb.lineplot(y="total_bill", x="day",data=tips)Avendo chiesto come ascissa i giorni della settimana e corrispondendo ad ognuno di essi una varietà di valori come total_bill ci verrà fornita graficamente un'idea
dell'andamento medio della distribuzione con tanto di area colorata ad integrazione:

Con Seaborn è possibile usare una funzione grafica generale, relplot, che di default rappresenta uno scatter ma passando il parametro kind="line" mostrerà il tutto come grafico
lineare. Sfruttiamo un esempio in merito per vedere come si può richiedere a Seaborn di creare più grafici distribuiti per righe e colonne. Osserviamo l'andamento delle mance rispetto
al conto totale spalmando i punti su più grafici dove le colonne indicheranno il sesso del cliente e le righe il tipo di pasto:
sb.relplot(x="total_bill", y="tip", data=tips, hue="day", row="time", col="sex")Il risultato:
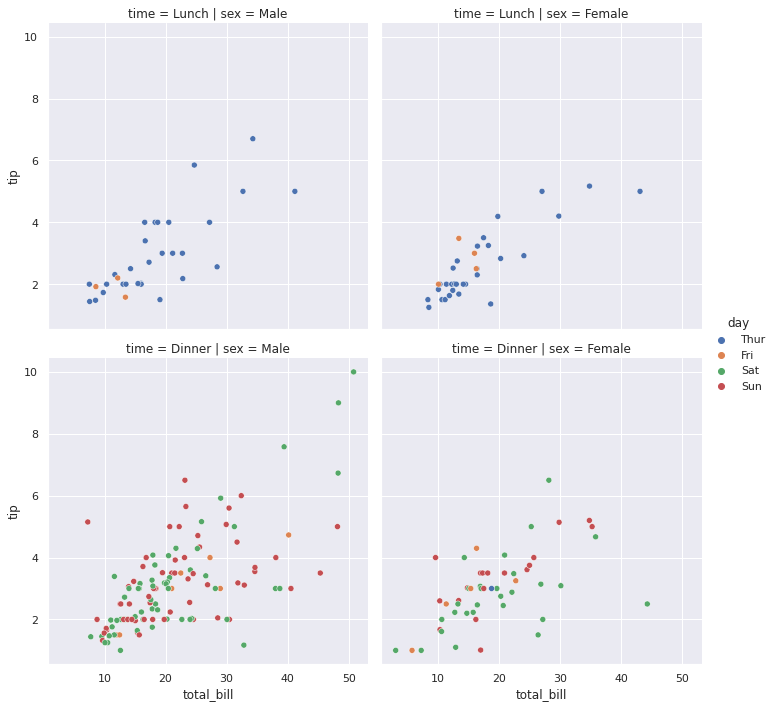
Pairplot e heatmap
Concludiamo questa panoramica su Seaborn con altri due grafici molto importanti in fase di esplorazione dei dati. Il primo è il pairplot che ha il grande merito di incrociare
tra loro tutti i campi in una griglia di scatter. Ogni mattonella rappresenterà l'incrocio tra il valore indicato nella corrispondente riga e quello nell'analoga colonna. Il comando è semplicemente
questo:
tips.pairplot()e offre tutto ciò:
Figura 5. Come appare un pairplot

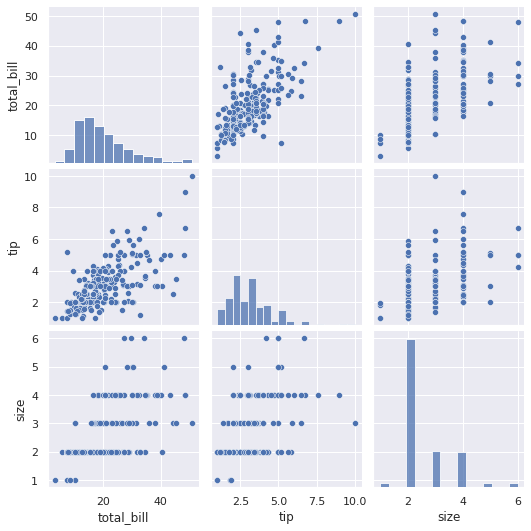
Un heatmap invece è utilissima per visualizzare graficamente una matrice di correlazione. Con Pandas, per visualizzare il fattore di correlazione tra tutte le colonne di un DataFrame
ci basta fare così:
tips.corr()e si ottiene una struttura comoda da leggere di questo tipo:
total_bill tip size
total_bill 1.000000 0.675734 0.598315
tip 0.675734 1.000000 0.489299
size 0.598315 0.489299 1.000000Chiaro sì ma se fossimo in cerca di un impatto visivo migliore ci potremmo rifare a Seaborn che con sb.heatmap(tips.corr()) restituisce questo:
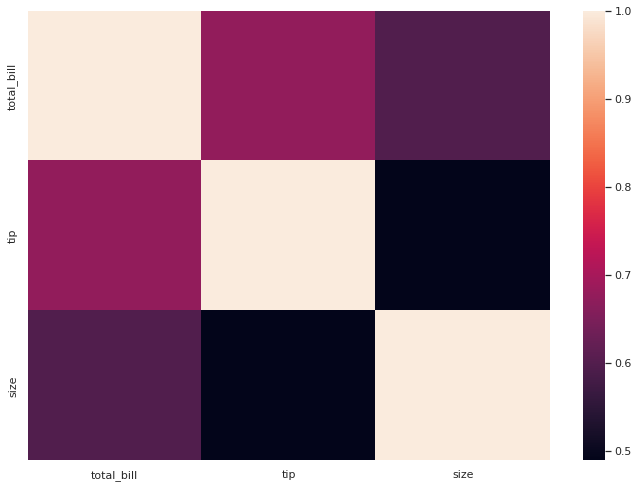
In quest'ultimo grafico vediamo che una scala di colori, a destra, associa una gradazione di colore al livello di correlazione: più questa si fa stretta, più il colore utilizzato diventa chiaro.
A colpo d'occhio, potremmo dire, davvero efficace.
Se vuoi aggiornamenti su Essentials inserisci la tua email nel box qui sotto:
