
Finora abbiamo visto, attraverso la definizione di variabili, come possiamo accedere e modificare la memoria attraverso un nome o identificatore. Il linguaggio C++, tuttavia, mette a disposizione del programmatore un costrutto di "basso livello", i puntatori, che ci consentono di accedere alla memoria anche attraverso gli indirizzi.
La memoria di un calcolatore è costitutita da una serie di celle o locazioni, che consentono di immagazzinare un certo numero di bit consecutivi. Ad ogni cella è associato un indirizzo diverso e celle adiacenti hanno indirizzi consecutivi.
I puntatori sono un particolare tipo di variabili usate per contenere e manipolare indirizzi.
Per capire come funzionano e perchè si usano, bisogna analizzare il modo in cui un programma viene rappresentato nella memoria di un calcolatore.
Il sistema operativo si occupa infatti dell'assegnazione di un'area di memoria per ogni programma e per i dati che da esso saranno manipolati. Tale memoria è suddivisa in vari segmenti, con funzioni differenti come illustrato nella figura seguente:
Layout dei segmenti di programma nella memoria virtuale (click per ingrandire)
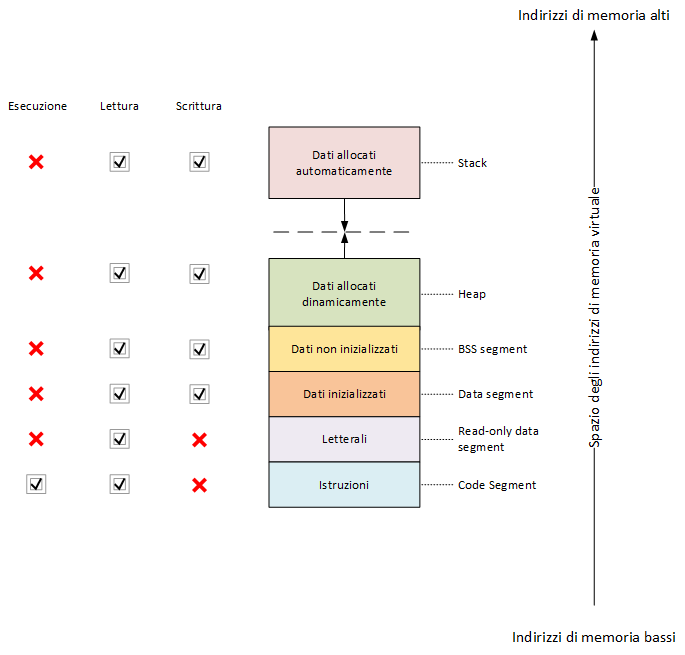
Code segment e Read-ondy data segment sono aree di memoria la cui dimensione e contenuto sono determinati dal compilatore, e non cambiano durante l'esecuzione del programma. I segmenti Data e BSS sono anch'essi aree di dimensione nota a tempo di compilazione, ma i dati in essi contenuti possono essere alterati.
Tuttavia, per quanto riguarda il comportamento a tempo di esecuzione, le aree di memoria maggiormente utilizzate sono lo heap e lo stack.
Lo stack è, per definizione, una struttura dati di tipo lista i cui gli elementi sono accessibili con una politica LIFO (Last In First Out). L'esempio tipico è quello della pila di piatti, in cui l'ultimo piatto aggiunto sarà anche il primo ad essere riutilizzato.
Nel contesto della memoria del programma, gli elementi dello stack sono detti stack frame, e ognuno di essi contiene tutte le variabili definite in un blocco compreso tra parentesi graffe {}.
Durante l'esecuzione del programma lo stack frame in testa è quello relativo al blocco che contiene l'istruzione correntemente in fase di esecuzione, mentre quelli successivi corrispondono ai blocchi esterni secondo il loro ordine di annidamento.
L'esempio seguente mostra la situazione dello stack durante l'esecuzione di un semplice programma:
#include <iostream>
int main()
{
int a = 0; // stack: {a}
{
int b = a + 1; // stack: {b} {a}
{
int c = b + 1; // stack: {c} {b} {a}
} // stack: {b} {a}
} // stack: {a}
return 0;
}Le variabili a, b, e c sono immagazzinate nello stack fin tanto che è attivo il loro ambito di visibilità, ma una volta al di fuori di esso tali variabili vengono distrutte: la locazione di memoria ad esse associata viene nuovamente resa disponibile. Per tal motivo, questo tipo di variabile è detta automatica: non è infatti richiesta nessuna istruzione particolare per cancellarla dallo memoria.
Lo stack è una struttura dati per sua natura molto efficiente: il costo di accesso al primo frame, infatti, non cambia al variare della dimensione dello stack. Ciò implica che le operazioni di allocazione e distruzione sono molto rapide. Tuttavia, lo spazio riservato allo stack ha un limite preciso che dipende dal linguaggio, l'architettura usata e altri fattori, e quando esso viene esaurito si verifica una condizione di errore nota come stack overflow, che provoca la terminazione immediata del programma.
Come si fa quindi a tenere in memoria una grande quantità di dati o a estendere la vita utile delle nostre variabili al di là dei limiti imposti dal contesto della loro dichiarazione?
La risposta consiste nel fare ricorso allo heap. Il termine, in questo caso, non fa riferimento all'utilizzo della omonima struttura dati, ma semplicemente al significato di "quantità": una grande area di memoria virtuale riservata al programma.
Per gestire la memoria dello heap è necessario fare ricorso a istruzioni particolari che necessitano dell'uso di puntatori. Con la seguente sintassi si possono dichiarare variabili puntatore, e allocare o deallocare le corrispondenti aree di memoria nello heap:
// dichiarazione di un puntatore
<tipo> * <identificatore>;
// allocazione di un'area di memoria nello heap sufficiente per una variabile del tipo dichiarato
* <identificatore> = new <tipo>;
// liberazione della memoria associata alla variabile puntatore <identificatore>
delete <identificatore>;L'esempio successivo mostra l'uso di questa sintassi per l'allocazione nello heap di una variabile di tipo intero.
#include <iostream>
int main()
{
int * p;
p = new int;
...
delete p;
...
return 0;
}La prima istruzione crea una variabile puntatore a intero p nello stack. L'indirizzo in essa contenuto è casuale e un tentativo di accesso alla locazione puntata potrebbe avere effetti imprevedibili.
Nella seconda istruzione, la parola chiave new seguita dal tipo int restituisce l'indirizzo della prima area di memoria disponibile nello heap sufficientemente grande per contenere un intero, e tale valore viene assegnato a p.
La parola chiave delete, seguita dall'identificatore p, consente invece di liberare la memoria nello heap corrispondente all'indirizzo contenuto in p. Dopo questa istruzione, qualunque tentativo di accedere alla locazione indirizzata da p ha effetti imprevedibili; tuttavia, è importante distruggere una variabile allocata dinamicamente quando essa non serve più per preservare l'efficienza e la stabilità del programma.
Tutte le variabili scritte nello stack, infatti, sono automatiche, inclusi i puntatori. Tuttavia essendo un puntatore un contenitore di indirizzi di memoria, non è detto che le cella corrispondente a tale indirizzo sia anch'essa gestita dallo stack, cioè non è detto che se la locazione di memoria occupata da un puntatore viene distrutta, lo stesso accade per le locazioni a cui esso punta.
L'esempio successivo mostra una situazione di questo tipo, in cui la distruzione automatica di un puntatore provoca un effetto collaterale noto come memory leak: ovvero una perdita del riferimento della memoria da esso puntata, che rimarrà occupata e inutilizzabile fino alla terminazione del programma.
#include <iostream>
int main()
{
...
{
int * p; // inserimento di p nello stack
p = new int; // allocazione di una variabile di tipo intero nello heap
...
} // rimozione di p dallo stack: memory leak!
...
return 0;
}L'unico modo per prevenire i leak consiste nel liberare esplicitamente lo spazio occupato nello heap tramite delete.
Inoltre, anche lo heap ha un limite di estensione, e pertanto una corretta gestione della memoria è fondamentale per evitare di ricadere in una condizione di errore simile a quella dovuta all'esaurimento dello stack. Quando ciò accade, ogni istruzione che utilizzi il costrutto new produrrà come risultato un indirizzo di memoria nullo, cioè non valido.
A partire dallo standard c++11, questo valore è identificato dal letterale nullptr, cui corrisponde una particolare sequenza di bit. Anche se tale sequenza è tipicamente composta da soli zeri, l'uso di nullptr è sempre preferibile al letterale 0 o alla macro NULL per l'inizializzazione di un puntatore.
L'esempio successivo mostra l'uso di nullptr per l'inizializzazione di un puntatore nullo e per verificare il buon esito dell'allocazione della memoria corrispondente nello heap:
#include <iostream>
int main()
{
int * p = nullptr;
p = new int;
if (p == nullptr)
{
... // errore nell'allocazione della memoria associata a 'p'.
}
else
{
...
delete p;
}
return 0;
}L'allocazione di variabili nello heap è meno efficiente rispetto allo stack, ma risulta indispensabile per la gestione di una memoria estesa. Ciò nonostante, l'uso dei puntatori non è esclusivamente legato alla gestione della memoria, come vedremo nel seguito con l'introduzione degli operatori di referenziazione e dereferenziazione.
