
In questa lezione, utilizzeremo il package Caret per vedere come affrontare un semplice esempio di machine learning. Tra i vari algoritmi che possiamo utilizzare, proviamone uno dei più semplici: la regressione lineare.
La regressione lineare è una tecnica statistica che mira ad individuare il legame tra una variabile dipendente ed una o più variabili indipendenti. Acquisendo dati campionari da una popolazione teoricamente infinita tramite regressione lineare, si possono ottenere i parametri che permettono di individuare il valore atteso della variabile dipendente rispetto a quelle indipendenti. Esistono molti modi che passo passo permettono di attuare i calcoli della regressione lineare, ma qui ci affideremo alle funzionalità di Caret.
Dati di esempio
Per prima cosa, scegliamo il campione di dati da usare. Adottiamo uno dei dataset già disponibili in R, denominato trees, contenente informazioni su circonferenza, altezza e
volume di alberi. Possiamo vedere i dati disponibili nel dataset invocandone il nome, nella console di R:
> trees
Girth Height Volume
1 8.3 70 10.3
2 8.6 65 10.3
3 8.8 63 10.2
4 10.5 72 16.4
5 10.7 81 18.8
6 10.8 83 19.7
7 11.0 66 15.6
8 11.0 75 18.2
9 11.1 80 22.6
10 11.2 75 19.9
...Si tratta di un data.frame di tre colonne: circonferenza (Girth), altezza (Height) e volume (Volume). Vogliamo scoprire se esiste un modo di supporre il volume a partire dalla sola circonferenza, in pratica trattando il primo come variabile dipendente dalla seconda.
Osservare i dati
Uno dei momenti più delicati di un procedimento di machine learning è la scelta dell'algoritmo da usare. Per usare la regressione lineare, dobbiamo essere certi che ci sia una relazione
pressochè "lineare" tra Volume e Girth. Si può anche procedere per modalità grafica, individuando "a occhio" una certa linearità nell'insieme dei valori.
Realizziamo quindi un semplice grafico a punti che rappresenti il dataset:
> plot(trees$Girth, trees$Volume)Il risultato sarà il seguente:
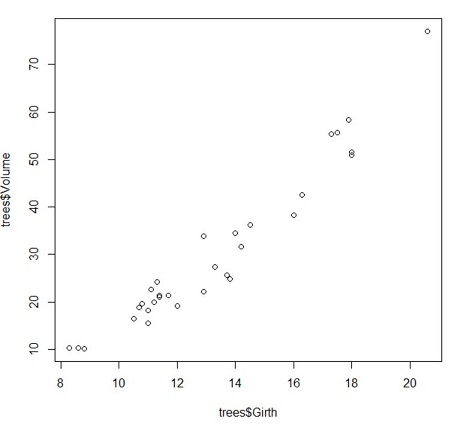
Come vede, i punti che si dipartono dall'origne degli assi sembrano svilupparsi attorno ad un'immaginaria semiretta. Lo scopo della regressione lineare è quello di individuare coefficiente angolare ed intercetta di tale retta. Una volta ottenuti questi dati, si potrà essere sempre in grado di supporre un valore atteso del volume rispetto alla circonferenza applicando la relazione lineare.
Regressione lineare con Caret
Per individuare i parametri della retta di regressione dobbiamo innanzitutto importare il package Caret:
> require("caret")Il meccanismo di training deve "studiare" dei dati, pertanto gliene prepariamo un set
sorteggiando circa un terzo del data.frame.
> trees.train<-trees[sort(sample(nrow(trees), nrow(trees)/10)), ]
> trees.train
Girth Height Volume
1 8.3 70 10.3
3 8.8 63 10.2
7 11.0 66 15.6
11 11.3 79 24.2
12 11.4 76 21.0
13 11.4 76 21.4
17 12.9 85 33.8
20 13.8 64 24.9
26 17.3 81 55.4
28 17.9 80 58.3Abbiamo fatto estrarre dieci righe casualmente e con la funzione sort() le abbiamo fatte disporre in ordine, per lo più a scopo di chiarezza nella visualizzazione.
Inneschiamo a questo punto il meccanismo di training con cui l'algoritmo tenterà di "imparare" dai dati:
> model.trees <- train(Volume ~ Girth, trees.train, method="lm")La funzione train() si occupa della fase di apprendimento e richiede i seguenti parametri:
Volume ~ Girth: con l'operatore~stabiliamo quali sono le variabili dipendenti (quelle a sinistra del simbolo, quindiVolumein questo caso) e quelle indipendenti (a destra, quiGirth);trees.train: indichiamo un set di dati che il sistema dovrà studiare;method="lm": specifichiamo quale algoritmo di learning dovrà essere applicato e indichiamolm, costante che sta per linear model.
Al termine delle operazioni non riceviamo output, ma potremo vedere quali sono i parametri
individuati. Si trovano in model.trees e possono essere ottenuto con:
> intercetta <- coef(model.trees$finalModel)[1]
> coef.ang <- coef(model.trees$finalModel)[2]
> intercetta
(Intercept)
-36.47653
> coef.ang
Girth
5.156046Cerchiamo innanzitutto una verifica visuale:
> plot(trees$Girth, trees$Volume)
> lines(trees$Girth, trees$Girth*coef.ang+intercetta)Con la funzione plot disegniamo i punti che abbiamo visto prima e con lines sovrapponiamo una linea parametrizzata sui dati ottenuti con regressione lineare. Ecco il risultato:
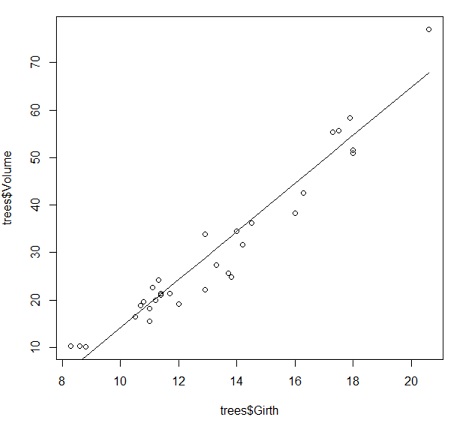
La retta sovrapposta attraversa l'area dei valori rappresentando un compromesso tra le varie posizioni. Potremmo usare i dati prodotti nel modello per fare delle predizioni "a mano", applicando la
formula geometrica. Ad esempio, tra i dati di trees non inclusi nel set di training abbiamo le seguenti
righe:
4 10.5 72 16.4
5 10.7 81 18.8
6 10.8 83 19.7Usando intercetta e coefficiente angolare del modello, i valori della circonferenza fornirebbero i seguenti
risultati:
> coef.ang*10.5+intercetta
17.66195
> coef.ang*10.7+intercetta
18.69316
> coef.ang*10.8+intercetta
19.20877Possiamo vedere che i valori "predetti" non si discostano molto da quelli reali. Come si immagina,
le stime produrrano un certo errore di predizione, soprattutto nell'esempio appena visto (in cui la relazione lineare può non essere la migliore possibile). Possiamo però considerare questo
esercizio come una dimostrazione delle finalità di un procedimento di machine learning.
Considerazioni finali
Un procedimento di machine learning richiede generalmente un'analisi prelimanre più approfondita, che esula dagli scopi di questa lezione dimostrativa. I vantaggi che offre il package Caret sono comunque notevoli, in quanto è corredato di molti strumenti collaterali per la preparazione corretta dei dati e molti algoritmi che possono essere eseguiti con facilità: è necessario per lo più sostituire l'indicazione del metodo nella funzione
Se vuoi aggiornamenti su Database inserisci la tua email nel box qui sotto:
