
Le reti neurali ricorrenti permettono di lavorare su dati costituiti da sequenze di valori, si tratta di reti in grado di tenere memoria dei dati elaborati utilizzate per l'elaborazione testuale, traduttori o image captioning.
Architettura di una RNN
Una RNN nella sua forma più semplice è rappresentata da una rete neurale artificiale che riporta in input i dati di output dello step precedente. L'input è costituito non solo dal dato corrente ma anche dal risultato in uscita ottenuto nella fase precedente.
Una rete di questo tipo soffre però di perdita di memoria a lungo termine, una RNN calcola l'uscita in base a ciò che ricorda dallo step precedente e da tutto ciò che ha elaborato negli step precedenti ad esso. Parliamo quindi di memoria a lungo termine e a breve termine.
Una RNN viene addestrata con una variante dell'algoritmo di back propagation denominato back propagation in time o BPTT. Essa permette di tenere in considerazione gli istanti di tempo nei quali vengono sottoposti gli input. L'algoritmo è chiaramente più complesso e per ridurre la complessità computazionale si utilizza la sua variante troncata nella quale solo alcuni step vengono aggiornati.
Per risolvere il problema della perdita di memoria a lungo termine sono state introdotte nuove architetture tra cui LSTM (Long short term memory).
LSTM
Una rete LSTM è caratterizzata da uno stato di memoria a lungo termine (cell state) e uno stato di memoria a breve termine (hidden state). Entrambi vengono forniti
in input alla rete e aggiornati in output dalla rete stessa. Ovviamente la rete riceve anche l'input corrente.
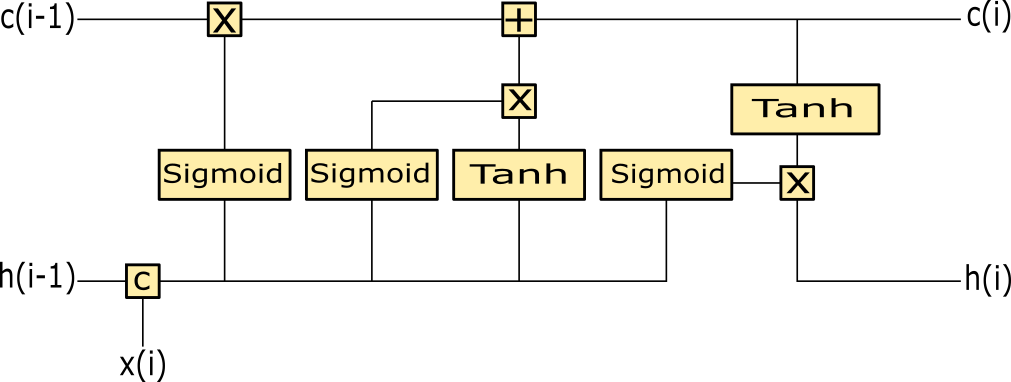
Figura 1. LSTM
Il cell state c(i) trasporta informazioni rilevanti della sequenza inviata in input alla rete, quindi verranno considerati anche i dati che sono stati forniti in input nei primi istanti, riducendo il problema della perdita di memoria a lungo termine.
Il cell state è un canale in cui viaggiano tutte le informazioni, su questo canale si agisce per aggiungere o rimuovere contenuti informativi durante il training. Nell'architettura sono presente i cosiddetti gate.
Partendo dalla concatenazione dell'input corrente x(i) e dello stato hidden h(i-1) dell'istante precedente, il forget gate costituito dal primo blocco sigmoid determina cosa cancellare dal cell state.
L'input gate, rappresentato dal secondo blocco sigmoid, sceglie cosa aggiungere nella memoria a lungo termine. L'output gate dell'ultimo blocco
sigmoid aggiorna lo stato hidden (memoria a breve termine). Lo stato hidden è anche l'output della rete.
L'unità sigmoid resituisce valori compresi tra 0 ed 1, per questa ragione viene utilizzata nelle fase di moltiplicazione dei dati, proprio per rimuovere quelli con valori vicini allo zero e tenere ciò che interessa con valori lontani dallo zero.
LSTM vista aperta
Una LSTM può anche essere vista in modalità aperta, ovvero pensando lo stesso blocco ripetuto e collegato in diversi istanti temporali. Non si tratta di una ripetizione vera e propria del blocco ma solo di una modalità di vista differente della rete che rimane rappresentata da un singolo blocco:
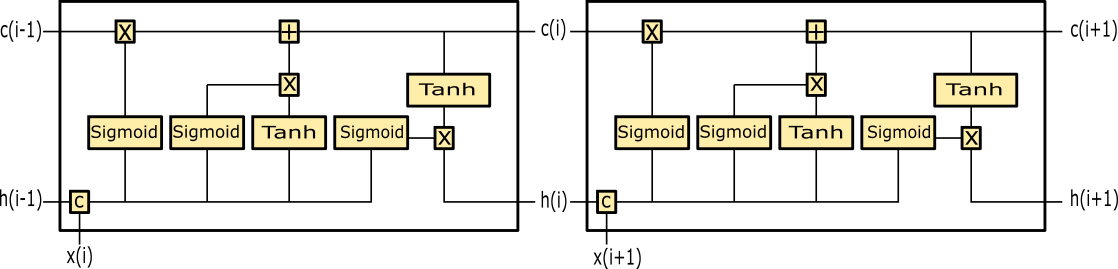
Figura 2. LSTM
Costruzione della rete
Deeplearning4j fornisce il modulo LSTM pronto all'uso, dobbiamo però definire le dimensioni di input e output. L'architettura di una LSTM è costituita da reti neurali artificiali, il nostro progetto deve consentire la memorizzazione di una frase, quindi la rete neurale ricorrente deve acquisire un carattere alla volta e predire il successivo.
Modifichiamo il pom maven facendo riferimento all'ultima millestone 1.0.0-M1.1 e iniziamo definendo alcune costanti:
import org.deeplearning4j.nn.conf.MultiLayerConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration;
import org.deeplearning4j.nn.conf.NeuralNetConfiguration.ListBuilder;
import org.deeplearning4j.nn.conf.Updater;
import org.deeplearning4j.nn.conf.layers.LSTM;
import org.deeplearning4j.nn.conf.layers.RnnOutputLayer;
import org.deeplearning4j.nn.multilayer.MultiLayerNetwork;
import org.deeplearning4j.nn.weights.WeightInit;
import org.deeplearning4j.optimize.listeners.ScoreIterationListener;
import org.nd4j.linalg.activations.Activation;
import org.nd4j.linalg.api.ndarray.INDArray;
import org.nd4j.linalg.api.ops.impl.indexaccum.custom.ArgMax;
import org.nd4j.linalg.dataset.DataSet;
import org.nd4j.linalg.factory.Nd4j;
import org.nd4j.linalg.learning.config.RmsProp;
import org.nd4j.linalg.lossfunctions.LossFunctions.LossFunction;
import java.util.ArrayList;
import java.util.LinkedHashSet;
import java.util.List;
public class RNN {
private static final char[] frase = "*Testo di prova.".toCharArray();
private static final List<Character> caratteri = new ArrayList<>();
private static final int HIDDEN_LAYER_WIDTH = 50;
private static final int HIDDEN_LAYER_CONT = 2;
public static void main(String[] args) {}frase rappresenta la sequenza da apprendere mentre caratteri una lista dei possibili caratteri, tutti i caratteri contenuti nella frase senza ripetizioni. Le altre due costanti servono per dimensionare i layer interni della rete.
Aggiungiamo il codice per la valorizzazione della lista dei caratteri:
LinkedHashSet<Character> chars = new LinkedHashSet<>();
for (char c : frase)
chars.add(c);
caratteri.addAll(chars);Iniziamo la configurazione della rete settando alcuni valori tra i quali l'ottimizzatore ed il learning rate:
NeuralNetConfiguration.Builder builder = new NeuralNetConfiguration.Builder();
builder.seed(123);
builder.biasInit(0);
builder.miniBatch(false);
builder.updater(new RmsProp(0.001));
builder.weightInit(WeightInit.XAVIER);
ListBuilder listBuilder = builder.list();Aggiungiamo quindi più layers LSTM:
for (int i = 0; i < HIDDEN_LAYER_CONT; i++) {
LSTM.Builder hiddenLayerBuilder = new LSTM.Builder();
listBuilder.layer(i, hiddenLayerBuilder.nIn(i == 0 ? caratteri.size() : HIDDEN_LAYER_WIDTH)
.nOut(HIDDEN_LAYER_WIDTH)
.activation(Activation.TANH).build());
}Per poter interpretare l'ouptut della rete in modo da proporre le probabilità per ciascun carattere utilizziamo il layer RnnOutputLayer:
RnnOutputLayer.Builder outputLayerBuilder = new RnnOutputLayer.Builder(LossFunction.MCXENT);
outputLayerBuilder.activation(Activation.SOFTMAX);
outputLayerBuilder.nIn(HIDDEN_LAYER_WIDTH);
outputLayerBuilder.nOut(caratteri.size());
listBuilder.layer(HIDDEN_LAYER_CONT, outputLayerBuilder.build());A questo punto la rete totale che fa uso di livelli LSTM è pronta, dobbiamo inizializzarla e impostare un listener:
MultiLayerConfiguration conf = listBuilder.build();
MultiLayerNetwork net = new MultiLayerNetwork(conf);
net.init();
net.setListeners(new ScoreIterationListener(1));Generazione dati di addestramento
Per addestrare la rete abbiamo bisogno di dati. Possiamo generarli facilmente in questo modo: ogni carattere viene codificato in one-hot, ciò significa che viene associato un array di valori binari con il valore 1 in corrispondenza del carattere rappresentato e tutti gli altri valori settati a zero.
L'array ha lunghezza pari al numero possibile di caratteri, tale meccanismo consente di rappresentare i caratteri possibili dell'insieme. Per ogni carattere in input abbiamo bisogno del carattere atteso in output, per il nostro task il carattere atteso è il successivo. Gli array input e labels rappresentano quindi i valori in input e i valori corrispondenti attesi.
INDArray input = Nd4j.zeros(1, caratteri.size(), frase.length);
INDArray labels = Nd4j.zeros(1, caratteri.size(), frase.length);
int samplePos = 0;
for (char currentChar : frase) {
char nextChar = frase[(samplePos + 1) % (frase.length)];
input.putScalar(new int[] { 0, caratteri.indexOf(currentChar), samplePos }, 1);
labels.putScalar(new int[] { 0, caratteri.indexOf(nextChar), samplePos }, 1);
samplePos++;
}
DataSet trainingData = new DataSet(input, labels);Addestramento e test
Completiamo il codice con la fase di addestramento e valutazione della rete. I caratteri vengono inviati uno alla volta come input, viene quindi calcolato il valore di output prendendo il carattere con la maggiore probabilità prodotta tra tutti i caratteri possibili:
for (int epoch = 0; epoch < 1000; epoch++) {
System.out.println("Epoch " + epoch);
net.fit(trainingData);
net.rnnClearPreviousState();
INDArray testInit = Nd4j.zeros(1,caratteri.size(), 1);
testInit.putScalar(caratteri.indexOf(frase[0]), 1);
INDArray output = net.rnnTimeStep(testInit);
for (char c : frase) {
int sampledCharacterIdx = Nd4j.getExecutioner().exec(new ArgMax(output, 1))[0].getInt(0);
System.out.print(caratteri.get(sampledCharacterIdx));
INDArray nextInput = Nd4j.zeros(1, caratteri.size(), 1);
nextInput.putScalar(sampledCharacterIdx, 1);
output = net.rnnTimeStep(nextInput);
}
System.out.print("\n");
}Eseguendo il programma vedremo la generazione progressiva di stringhe che porterà infine alla produzione della frase di test. La rete ha quindi imparato a riprodurre i caratteri della frase man man che li introduciamo nella rete.
