
Le reti CNN sono simili alle reti neurali viste nei capitoli precedenti e costituite da neuroni con parametri da apprendere nella fase di addestramento. Si caratterizzano per lavorare esclusivamente su immagini. Tramite le CNN siamo in grado di risolvere diversi problemi come la classificazione di immagini e l'identificazione di oggetti in un'immagine, potendo cosi trovare molti campi di applicazione tra cui la guida auto-assistita e il riconoscimento di patologie.
Perchè non una semplice rete neurale?
Ci si potrebbe chiedere perchè non utilizzare una semplice rete neurale anche per compiti che riguardano il parsing di immagini. Per rispondere ricordiamo come è fatta una rete neurale. Abbiamo un input che viene trasformato da una serie di hidden layers fino a giungere al livello di uscita. Ciascuno di essi costituito da neuroni collegati ai neuroni del livello precedente.
Il problema è proprio la caratteristica di connessione completa dei neuroni che devono ricevere tutto l'input in ingresso, in questo modo non si riesce a gestire in modo efficiente un'immagine complessa.
Supponiamo di avere immagini da 200x200x3 (il terzo valore rappresenta la profondità RGB). In questo caso un neurone dovrebbe avere un numero di parametri pari a 200*200*3=120.000. L'intera rete avrebbe quindi un numero di parametri enorme è sarebbe molto difficile da addestrare se non addirittura impossibile. Un rete CNN risolve il problema attraverso neuroni che scorrono sull'input acquisendo di volta in volta solo una parte dell'input stesso.
CNN: Convolutional Layer
Per costruire una rete CNN abbiamo a disposizione tre tipi di layer: Convolutional Layer, Pooling Layer e Fully-Connected Later. Descriviamo nell'immediato il convolutional layer lasciando il pooling layer come descrizione finale.
Il fully connected layer è una rete neurale classica in uscita, utilizzata per scopi di classificazione finale. Una rete CNN è in grado di catturare caratteristiche dell'immagine
in input tramite una catena di layer convoluzionali e di pooling.
In un layer convoluzionale abbiamo in generale diversi filtri (neuroni) tridimensionali. Ogni filtro è caratterizzato da un'ampiezza, un'altezza e una profondità. La profondità è la stessa del blocco in input che, essendo un'immagine, può avere profondità uno, tre, oppure maggiore di tre nei livelli intermedi in base ai filtri utilizzati.
Ogni filtro è dotato di parametri che devono essere appresi. Un tipico filtro ha dimensioni HxWxD dove D è la profondità dell'input al quale è applicato il filtro stesso, e HxW (receptive field) è la dimensione del filtro.
Un filtro di questo tipo si muoverà lungo l'input moltiplicando i parametri per i valori rgb incontrati, producendo cosi un valore per il blocco in uscita. Questa operazione è denominata convoluzione. In generale alla combinazione lineare dei valori rgb dell'input ottenuta dal filtro si applica una funzione non lineare. L'insieme di più filtri costituisce un layer di convoluzione.
Sottolineiamo il fatto che ogni filtro produce un output che si concatena con l'output prodotto dagli altri filtri. Questa concatenazione rappresenta l'input per il successivo layer.
Un parametro importante per un filtro è lo stride che indica il numero di pixel di movimento orizzontale e verticale del filtro lungo l'input. Nell'immagine che segue abbiamo l'applicazione di un filtro ad un'immagine in input e il caso di una molteplictà di filtri. Il filtro si muove orizzontalmente di uno scendendo dello stesso valore non appena raggiunto il limite.
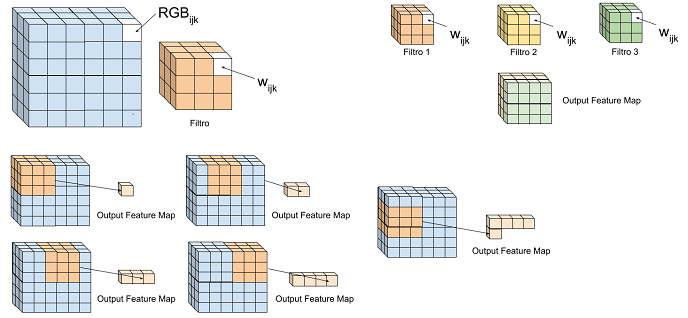
Figura 1. Convoluzione
Il filtro presente nell'immagine, riduce le dimensioni in input. Talvolta può essere conveniente fare in modo che le dimensioni in output siano le stesse dell'input, questa operazione è possibile eseguendo un padding sull'input prima di applicare il filtro. Il padding consiste nell'applicare dei valori nulli intorno all'immagine in input.
Nel caso di immagini WxW e filtro FxF, per calcolare la dimensione in output ai può utilizzare la formula: output = (W−F+2P)/S + 1 dove W rappresenta la dimensione in input, F quella del filtro, P il numero di padding zero utilizzati intorno all'immagine, S lo stride. Se abbiamo un input 200x200 con un livello padding, stride 1 e filtro di dimensione 3, la dimensione in output sarà: (200-3+2*1)/1 + 1= 200, ovvero 200x200.
Un esempio di architettura è il seguente:
- INPUT [32x32x3]: immagine con colori R,G,B.
- 12 filtri di convoluzione che producono un blocco [32x32x12]
- Funzione
RELU=max(0,x)applicata ai valori del blocco - Pooling layer che porta la dimensione del blocco a 16x16x12.
- Fully connected layer che calcola i valori di output producendo un blocco 1x1x10 dove ogni valore corrisponde ad una probabilità di appartenza ad una categoria.
Pooling Layer
Il pooling riduce le dimensioni degli output nella rete in questo modo si riesce a diminuire il numero di parametri. Un pooling layer è costituito da filtri che estraggono il valore massimo valore/valore medio.
In pratica un filtro di pooling è simile a un filtro di convoluzione ma non ha parametri. Il suo scopo è processare l'immagine calcolando il valore massimo (o medio) dei pixel in certo punto e fornendolo in output.
Un filtro di pooling ha quindi la sua dimensione e il suo stride. Per visualizzare il pooling si può fare riferimento all'immagine di Figura 1 considerando il filtro senza parametri.
Se vuoi aggiornamenti su Development inserisci la tua email nel box qui sotto:

