
Uno dei requisiti fondamentali per chi si occupa di data storage è la tolleranza ai guasti. Questa proprietà, infatti, è ciò che consente
ad un sistema di memorizzazione di riuscire a mantenere l’integrità dei dati anche in seguito ad un guasto dei dispositivi di storage, ed in alcuni casi
anche di continuare a funzionare. Per riuscire ad incrementare il livello di resistenza ai malfunzionamenti degli hard disk, IBM ha
brevettato, nel 1978, la tecnologia RAID, acronimo che inizialmente stava per Redundant Array of Inexpensive Disks, ma che in
seguito fu tramutato in Redundant Array of Independent Disks. Con questa tecnologia, infatti, è possibile utilizzare più memorie di massa, in modo
tale da creare una sorta di memoria di massa “virtualmente unica”, al fine di migliorarne l’affidabilità, l’efficienza, la velocità e
(ultima ma non meno importante) la tolleranza ai guasti.
Nel seguito vedremo come sfruttare un tool per sistemi Linux, mdadm (acronimo di Multiple Device Administrator), in grado
di implementare sistemi RAID software. Prima, però, spiegheremo brevemente come funzionano questi sistemi, per poi approfondire meglio la parte di
configurazione vera e propria.
Com’è fatto un RAID
Esistono sostanzialmente due tipologie di implementazione del RAID. La più efficiente è la categoria delle implementazioni hardware, dal
momento che essa consente la parallelizzazione delle operazioni di lettura e scrittura sui dischi, mediante l’utilizzo di appositi controller ai quali è
possibile collegare diversi hard disk. Questo tipo di soluzione è, comunque, più costosa delle implementazioni software, che consentono di
utilizzare lo stesso tipo di concetti che stanno alla base di quelle hardware, con la differenza che il tutto dev’essere gestito dal sistema operativo (con
una conseguente perdita di efficienza). Il pregio del software, però, è che non richiede hardware addizionale, e può essere configurato in modo
teoricamente indipendente dalla piattaforma.

Dopo il brevetto di IBM, alcuni autori hanno definito diversi livelli di RAID, ognuno dei quali ha i propri pregi e difetti. Per poter
capire i meccanismi che stanno dietro alla configurazione, è bene conoscere tali livelli, e per questo motivo li riassumeremo di seguito. I lettori che
conoscono già questi concetti, e che sono interessati soltanto alla parte di configurazione, possono tranquillamente passare al paragrafo successivo.
RAID 0
E’ la modalità più semplice (anche conosciuta come striping), mediante la quale più dischi vengono concatenati insieme, semplicemente al
fine di creare un solo disco virtuale, a partire da un grande numero di piccoli dischi fisici. Proprio per questo motivo, possiamo pensare a questa
tipologia di RAID come una sorta di “partizionamento invertito”.
I vantaggi possono derivare dalla possibilità di parallelizzare le operazioni di lettura e scrittura, che possono avvenire su più dischi simultaneamente.
Tuttavia, dal punto di vista della tolleranza ai guasti, questa configurazione ha un’affidabilità addirittura inferiore a quella di un unico disco, dal
momento che il guasto di un dispositivo comporta il malfunzionamento dell’intero RAID.
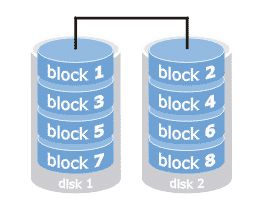
Il numero minimo di dischi per realizzare un RAID 0 è pari a 2. La capacità C di una configurazione RAID 0 è data dalla somma delle capacità dei dischi che
lo compongono:
C = C1 + C2 + ... CN
RAID 1
Con questa configurazione (anche conosciuta come mirroring), si introduce la ridondanza dei dati, al fine di consentire la tolleranza ai
guasti. Sostanzialmente, si utilizzano due o più dischi (supposti di uguale capacità), ognuno dei quali contiene esattamente gli stessi dati, che vengono
continuamente mantenuti allineati. Tutte le operazioni di lettura e scrittura sono, quindi, effettuate allo stesso modo, su tutti i dischi.
Il vantaggio principale di questa configurazione è che avendo N dischi, anche nel caso in cui se ne guastino N – 1, il sistema può continuare a funzionare.
Gli svantaggi derivano dal fatto che, anche usando 100 dischi da 1 TB (il che è abbastanza irrealistico), l’effettivo spazio utilizzabile rimane sempre di
1 TB, dal momento che 99 dischi sono utilizzati unicamente come “copie di backup” del primo. Vedremo, con le prossime configurazioni, che vi sono tecniche
più sofisticate, finalizzate ad un migliore utilizzo dello spazio, pur mantenendo la ridondanza dei dati.
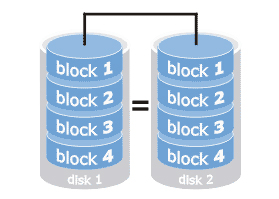
Il numero minimo di dischi per realizzare un RAID 1 è pari a 2. La capacità C di una configurazione RAID 1 è data dalla capacità minima tra quelle dei
dischi che lo compongono:
C = min(C1, C2, ..., CN)
RAID 2
Un sistema RAID 2 integra lo striping del RAID 0, con l’utilizzo di un codice di Hamming per
la correzione degli errori. Sostanzialmente, i dati vengono suddivisi bit a bit, e ad essi vengono associati ulteriori bit per la
costruzione del già citato codice. Ciò rende il sistema più affidabile, poiché consente di correggere errori su singoli bit, o di rilevare errori doppi.
Questa configurazione si rivela utile nei casi in cui si verificano abbastanza frequentemente errori di lettura o scrittura, ma ad oggi viene molto poco utilizzata poiché richiede molto overhead computazionale (proprio per il controllo degli errori), ma anche perché utilizza
molti dischi ridondanti, in maniera poco efficiente. Inoltre, i dispositivi di memorizzazione moderni sono sempre più affidabili, e gli errori di lettura o
scrittura diventano sempre meno frequenti, riducendo l’importanza dei meccanismi di controllo degli errori.

RAID 3
Il RAID 3 aggiunge un ulteriore livello di controllo degli errori, mediante l’aggiunta di un disco dedicato al controllo di parità. Anche questa
configurazione, nella pratica, è poco utilizzata, per motivi che derivano sostanzialmente dall’overhead computazionale e dalle restrizioni
sulla parallelizzazione degli accessi ai dischi, derivanti dal meccanismo di controllo ed eventuale correzione degli errori utilizzato.
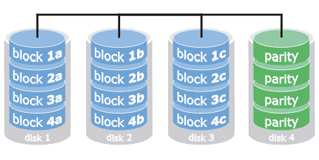
Il numero minimo di dischi per realizzare un RAID 3 è pari a 3. La capacità C di una configurazione RAID 3 è data da:
C = min(C1, C2, ..., CN) × (N - 1)
RAID 4
Molto simile al RAID 3, questa configurazione si distingue dalla precedente per il fatto che i dati non vengono suddivisi bit a bit, ma per blocchi. Ciò consente ad ogni disco di operare in maniera indipendente quando è richiesto un singolo blocco, e quindi aumenta le
possibilità di parallelizzazione degli accessi, con un conseguente miglioramento di efficienza.
Con il RAID 4, inoltre, il controllo di parità consente anche la già citata tolleranza ai guasti. Se si guasta un solo disco, infatti, è
possibile ripristinare i dati persi dopo la sostituzione del dispositivo malfunzionante, in maniera automatica e dettata da un opportuno
algoritmo.
Il numero minimo di dischi per realizzare un RAID 4 è pari a 3. La capacità C di una configurazione RAID 4 è data da:
C = min(C1, C2, ..., CN) × (N - 1)
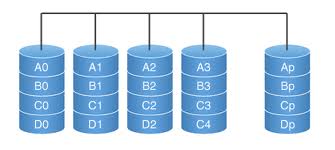
RAID 5
Questa modalità di RAID è una delle più utilizzate, sia in hardware che in software. Essa prevede la distribuzione dei dati di parità
(utilizzati sempre per il controllo degli errori) tra i vari dischi (piuttosto che su dischi dedicati). Ciò garantisce la possibilità di recuperare
eventuali errori, indipendentemente dal disco che si guasta (mentre nelle precedenti configurazioni il guasto del disco contenente i dati di parità
annullava tutti i metodi di controllo degli errori).
Rispetto al RAID 4, le letture sono più lente, mentre le scritture sono più efficienti. Ciò può essere un vantaggio in tutti quei casi in cui il sistema
RAID è utilizzato a fini di archiviazione, e le letture sono abbastanza rare.
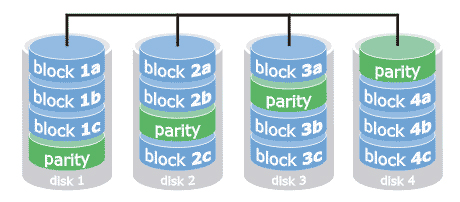
Il numero minimo di dischi per realizzare un RAID 5 è pari a 3. La capacità C di una configurazione RAID 5 è data da:
C = min(C1, C2, ..., CN) × (N - 1)
RAID 6
Nel RAID 6 si introduce un ulteriore livello di ridondanza (che è sempre distribuita tra i vari dischi, e non dedicata), finalizzato a
garantire una maggiore tolleranza ai guasti. Ciò, ovviamente, implica una minore efficienza dal punto di vista della velocità di lettura e scrittura, ma
fornisce maggiori garanzie in tutte quelle situazioni nelle quali la perdita dei dati è intollerabile.
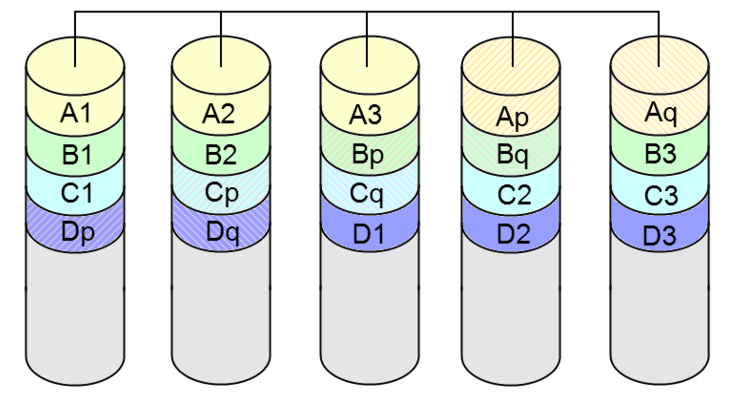
Il numero minimo di dischi per realizzare un RAID 6 è pari a 3. La capacità C di una configurazione RAID 6 è data da:
C = min(C1, C2, ..., CN) × (N - 2)
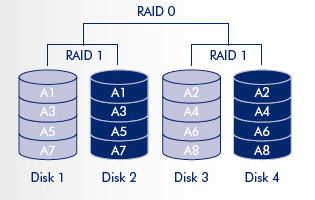
Livelli di RAID annidati
Esiste anche la possibilità di annidare più livelli di RAID, per garantire maggiore efficienza e più tolleranza ai guasti, al prezzo di un
maggior numero di dischi o di controllori più costosi (nelle implementazioni hardware).
Non ci addentreremo ulteriormente in questo ambito, poiché è più che sufficiente la conoscenza dei livelli di base, ma ci limitiamo semplicemente a citarne
l’esistenza.
Configurare un RAID su Linux
Dopo questa breve panoramica sulle varie configurazioni, non ci resta che capire come creare un RAID software su Linux. Dal momento che non ho a
disposizione moltissimi hard disk, ho utilizzato VirtualBox (ma sarebbe andato bene qualsiasi altro software di virtualizzazione), che
consente di creare una macchina virtuale con un numero teoricamente illimitato di dispositivi di memorizzazione (virtuali). Nello specifico, io ho
utilizzato 5 hard disk (virtuali), ciascuno da 8 GB, più un ulteriore disco sul quale è installato il sistema operativo (io ho scelto Ubuntu 14.04, ma
l’intero procedimento può essere facilmente esteso ad una qualsiasi altra distribuzione).
Parte I: formattare i dischi
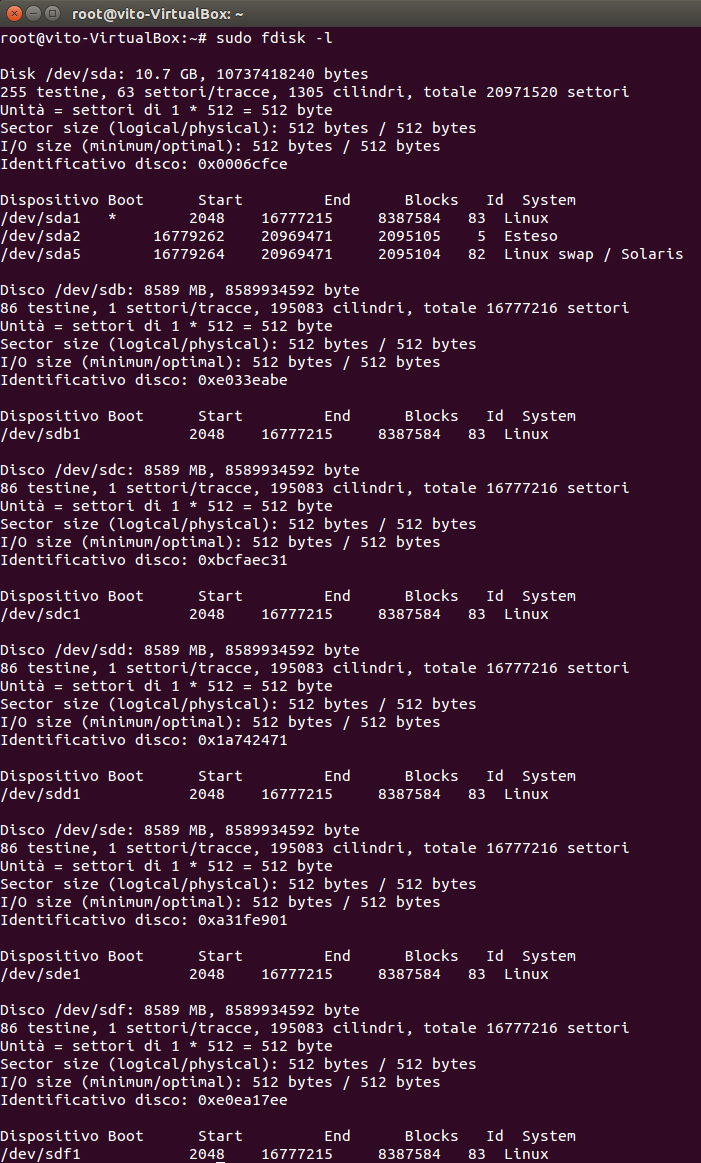
Per cominciare, dobbiamo formattare i nostri 5 dischi, e la prima cosa utile da fare è utilizzare il comando fdisk (ovviamente con i privilegi di
root, che su Ubuntu si ottengono con sudo), per ottenere la lista di tutti i dispositivi, e le relative partizioni:
vito@vito-VirtualBox:~$ sudo fdisk -l
Disk /dev/sda: 10.7 GB, 10737418240 bytes
255 testine, 63 settori/tracce, 1305 cilindri, totale 20971520 settori
Unità = settori di 1 * 512 = 512 byte
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Identificativo disco: 0x0006cfce
Dispositivo Boot Start End Blocks Id System
/dev/sda1 * 2048 16777215 8387584 83 Linux
/dev/sda2 16779262 20969471 2095105 5 Esteso
/dev/sda5 16779264 20969471 2095104 82 Linux swap / Solaris
Disco /dev/sdb: 8589 MB, 8589934592 byte
255 testine, 63 settori/tracce, 1044 cilindri, totale 16777216 settori
Unità = settori di 1 * 512 = 512 byte
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Identificativo disco: 0x00000000
Il disco /dev/sdb non contiene una tabella delle partizioni valida
Disco /dev/sdc: 8589 MB, 8589934592 byte
255 testine, 63 settori/tracce, 1044 cilindri, totale 16777216 settori
Unità = settori di 1 * 512 = 512 byte
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Identificativo disco: 0x00000000
Il disco /dev/sdc non contiene una tabella delle partizioni valida
Disco /dev/sdd: 8589 MB, 8589934592 byte
255 testine, 63 settori/tracce, 1044 cilindri, totale 16777216 settori
Unità = settori di 1 * 512 = 512 byte
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Identificativo disco: 0x00000000
Il disco /dev/sdd non contiene una tabella delle partizioni valida
Disco /dev/sde: 8589 MB, 8589934592 byte
255 testine, 63 settori/tracce, 1044 cilindri, totale 16777216 settori
Unità = settori di 1 * 512 = 512 byte
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Identificativo disco: 0x00000000
Il disco /dev/sde non contiene una tabella delle partizioni valida
Disco /dev/sdf: 8589 MB, 8589934592 byte
255 testine, 63 settori/tracce, 1044 cilindri, totale 16777216 settori
Unità = settori di 1 * 512 = 512 byte
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Identificativo disco: 0x00000000
Il disco /dev/sdf non contiene una tabella delle partizioni valida
Come si vede da questo output, l’unico disco formattato è quello identificato con /dev/sda, da 10.7 GB. Ed in effetti, è proprio su questo disco
che ho installato Ubuntu. Tutti gli altri dischi (da /dev/sdb, fino a /dev/sdf), invece, non sono formattati, e di conseguenza non contengono
alcuna tabella delle partizioni.
Il prossimo passo, quindi, è creare almeno una partizione per ognuno dei 5 dischi da formattare. Ancora una volta, utilizziamo fdisk:
sudo fdisk /dev/sdb
A questo punto, dovremo interagire con fdisk. Per prima cosa, digitiamo la lettera n per creare una nuova partizione. Ci verrà chiesto
che tipo di partizione vogliamo creare (extended o primary). Nel nostro caso, digitiamo p per una partizione primaria, e
premiamo Invio. Inseriamo, quindi, il numero della partizione (che sarà 1), e confermiamo con Invio i cilindri di partenza e di
fine (utilizziamo i valori predefiniti), per creare un disco con un’unica partizione da circa 8 GB (cioè, della massima dimensione possibile). Per creare
la partizione, a questo punto, non resta che premere la lettera w (che sta per “write”), ed il gioco è fatto. Ripetendo questi comandi anche per
gli altri dispositivi, avremo finalmente formattato tutti gli hard disk, e potremo procedere con la configurazione del RAID.
Parte II: installare madmn
Per potere configurare il RAID, abbiamo bisogno di un tool per Linux chiamato mdadm (acronimo che sta per Multiple Device Administrator). Se utilizziamo Ubuntu, come nel mio caso, lo troviamo già nei repository, e possiamo installarlo tramite apt con il seguente comando:
sudo apt-get install mdadmn
Nella maggior parte delle principali distribuzioni, questa utility è presente nei repository software ufficiali, ed è quindi abbastanza semplice ottenerla.
Se così non è, possiamo sempre fare riferimento al sito dell’autore di questo software, Neil Brown (che, tra le
altre cose, è uno degli sviluppatori di SUSE), che mantiene una pagina dotata di link al repository Git di mdadmn, nonché l’opportuna documentazione.
Non ci resta, finalmente, che utilizzare questo tool.
Parte III: creare il RAID
Supponiamo, a titolo di esempio, di volere sfruttare i nostri 5 hard disk per configurare un RAID 1 (mirroring) tra i dischi /dev/sdb e /dev/sdc, ed un RAID 5 sfruttando gli altri 3 dischi. In questo modo avremo due sistemi RAID, il primo di capacità pari a:
CRAID1 = min(8, 8) = 8 GB
ed il secondo di capacità pari a:
CRAID5 = min(8, 8, 8) × (3 - 1) = 16 GB
Con mdadmn, tutto ciò può essere fatto con due soli comandi. Il primo, per creare il sistema RAID 1, è il seguente:
mdadm --create --verbose /dev/md0 --level=raid1 --raid-devices=2 /dev/sdb1 /dev/sdc1
Con l’opzione --create di mdadm, abbiamo specificato che vogliamo creare un RAID, che sarà identificato da /dev/md0; inoltre, l’opzione --level ci consente di specificare il livello di RAID (in questo primo caso, RAID 1). Infine, abbiamo specificato quante partizioni vogliamo
utilizzare (--raid-devices=2) e quali sono (/dev/sdb1 e /dev/sdc1).
In modo analogo, se vogliamo creare il RAID 5 con gli altri tre dispositivi, digitiamo da terminale il comando seguente:
mdadm --create --verbose /dev/md1 --level=raid5 --raid-devices=3 /dev/sdd1 /dev/sde1 /dev/sdf1A questo punto, dovremo formattare i due sistemi RAID, e possiamo farlo con i comandi seguenti:
sudo mkfs.ext3 /dev/md0
sudo mkfs.ext3 /dev/md1In questo modo, avremo due RAID con file system EXT3. Nulla vieta, ovviamente, di utilizzare altri tipi di file system.
Per verificare che tutto sia andato a buon fine, verifichiamo che anche fdisk si sia accorto dei nuovi RAID:
vito@vito-VirtualBox:~$ sudo fdisk -l /dev/md0 /dev/md1
Disco /dev/md0: 8584 MB, 8584626176 byte
2 testine, 4 settori/tracce, 2095856 cilindri, totale 16766848 settori
Unità = settori di 1 * 512 = 512 byte
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Identificativo disco: 0x00000000
Il disco /dev/md0 non contiene una tabella delle partizioni valida
Disk /dev/md1: 17.2 GB, 17168334848 bytes
2 testine, 4 settori/tracce, 4191488 cilindri, totale 33531904 settori
Unità = settori di 1 * 512 = 512 byte
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 524288 bytes / 1048576 bytes
Identificativo disco: 0x00000000
Il disco /dev/md1 non contiene una tabella delle partizioni validaGli "allarmanti" messaggi sulla mancanza delle tabelle delle partizioni, in questo caso, non sono rilevanti, e possiamo tralasciarli. Ciò che importa è, invece, che i dischi /dev/md0 e /dev/md1 siano effettivamente presenti. A questo punto, se vogliamo provare a scrivere qualcosa su uno dei due sistemi RAID di cui sopra, basterà semplicemente montarli su una qualsiasi directory ed utilizzarli:
#Creiamo una directory per ogni RAID:
mkdir /home/vito/RAID1 /home/vito/RAID5
#Montiamo i due RAID nelle rispettive cartelle
sudo mount /dev/md0 /home/vito/RAID1
sudo mount /dev/md1 /home/vito/RAID5
#Già che ci siamo, prendiamo possesso di queste directory...
chown vito /home/vito/RAID1 /home/vito/RAID5
#...in modo da potervi accedere senza i privilegi di rootE il gioco è fatto! Abbiamo creato due directory, ognuna delle quali punta ad un diverso sistema RAID. Possiamo accedervi anche dal desktop di Unity, ed utilizzarle per tutti gli scopi che riteniamo utili.
Nel prossimo paragrafo, concluderemo con alcune informazioni che possono tornare utili per utilizzare al meglio questa tecnologia.
Altre informazioni di configurazione utili
Come abbiamo già accennato, è possibile associare i dischi RAID ad una directory con il comando mount. E’ anche possibile rendere questa
operazione automatica, in modo che essa venga eseguita durante la fase di avvio del sistema. Per farlo, dobbiamo innanzitutto procurarci
gli UUID relativi ai dispositivi RAID, con il comando blkid:
vito@vito-VirtualBox:~$ sudo blkid /dev/md*
/dev/md0: UUID="72e32a4e-acfd-4c34-a8fe-cefd4e59cee5" TYPE="ext3"
/dev/md1: UUID="dcd83bc4-5edc-453f-9a54-f3fda4323509" TYPE="ext3"
A questo punto, possiamo utilizzare l’output del comando precedente all’interno del file /etc/fstab, che contiene le informazioni relative ai
dispositivi che vengono montati automaticamente all’avvio. Dopo averlo aperto con qualsiasi editor di testo (ed i privilegi di root), aggiungiamo in coda
ad esso le righe seguenti:
[code]
UUID=72e32a4e-acfd-4c34-a8fe-cefd4e59cee5 /home/vito/RAID1 ext3 defaults 0 0
UUID=dcd83bc4-5edc-453f-9a54-f3fda4323509 /home/vito/RAID5 ext3 defaults 0 0
[/code]
A questo punto, anche dopo il riavvio, potremo accedere automaticamente al contenuto dei due RAID direttamente dalle directory che avevamo precedentemente
creato.
Per completare il quadro, è bene sapere anche come rimuovere il RAID per poter tornare ad utilizzare i singoli hard disk. Innanzitutto,
dovremo smontare i due RAID (se sono montati), con il comando umount. Infine, sfrutteremo di nuovo mdadm per eliminarlo:
[code]
umount /home/vito/RAID1
umount /home/vito/RAID5
mdadm -S /dev/md0
mdadm -S /dev/md1
[/code]
Così facendo, gli hard disk che compongono il RAID potranno essere riformattati singolarmente ed utilizzati per ogni necessità.
