
Negli ultimi tempi abbiamo assistito ad un crescente interesse verso tecnologie che, fino a pochi anni fa, sembravano di stretta competenza di centri di ricerca e università, ma che stanno trovando applicazioni pratiche sempre più frequenti. Tra queste, di particolare rilievo è il machine learning (spesso abbreviato in ML), che raggruppa tutta una serie di algoritmi di statistica ed intelligenza artificiale mirati all'analisi dei dati ed al loro uso per "apprenderne" l'andamento o alcune caratteristiche da essi derivanti. La fase di apprendimento (training) può essere finalizzata ad effettuare previsioni piuttosto attendibili, o a classificare e raggruppare i dati in maniera automatica e il più possibile efficiente (clustering).
Su HTML.it abbiamo già visto come implementare alcuni algoritmi di machine learning (ad esempio nella guida al linguaggio R, parlando espressamente del supporto al machine learning). In questa lezione, forniremo una panoramica di come e perché utilizzare il machine learning su Javascript, ad oggi uno dei linguaggi di programmazione più diffusi, e spesso utilizzato per il web.
Perché Javascript?
Accostare machine learning e Javascript non è cosa comune. Spesso, anzi, il machine learning viene più facilmente implementato con altri linguaggi, quali Python o il già citato R. Eppure, esiste un vasto numero di librerie già pronte all'uso, che permettono di implementare tutti i principali algoritmi di machine learning su Javascript. Tra queste, alcune permettono di implementare le reti neurali (brain.js, Synaptic, Neataptic), altre forniscono strumenti per l'NLP (Natural), altre ancora forniscono strumenti per il deep learning (Webdnn) e molte altre funzionalità (ml.js). Unendo a questa grande disponibilità di librerie la possibilità di utilizzare framework come Node.js (e quindi sfruttare Javascript anche lato server), è evidente come Javascript diventi un'opzione concreta anche in applicazioni potenzialmente complete e pronte per le fasi di produzione.
Altre critiche comunemente rivolte a Javascript sono relative all'efficienza e alla difficoltà di manipolare le matrici. Tuttavia, va rilevato il crescente supporto a questo linguaggio di programmazione (grazie anche alla diffusione delle app mobile web-based), che ha assottigliato le differenze tra l'uso di Javascript ed altri linguaggi interpretati (Python, R), soprattutto in termini di tempi di esecuzione. Inoltre, esistono molte librerie che permettono di manipolare in modo agevole matrici ed altre strutture dati su Javascript: si pensi ad esempio a math.js, che rappresenta un fondamentale aiuto in questo senso.
Un esempio pratico
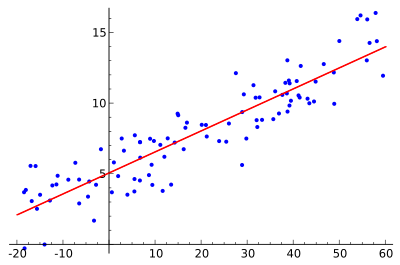
Chiarito perché può avere senso realizzare applicazioni di machine learning su Javascript, vediamo ora un esempio pratico sfruttando la già citata libreria ml.js. In questo esempio pratico, vedremo come realizzare una regressione lineare: si tratta di un processo che permette di approssimare l'andamento di una funzione, "apprendendolo" a partire da un set di dati cosiddetti di "addestramento" (training set).
Installazione delle librerie
Iniziamo innanzitutto con l'installazione delle librerie necessarie, che potremo effettuare tramite il package manager yarn:
$ yarn add ml-regression csvtojsonIn alternativa, possiamo sfruttare npm:
$ npm install ml-regression csvtojsonInstallando ml-regression otterremo tutte le funzionalità richieste per implementare la regressione lineare, mentre csvtojson è una libreria che useremo per importare i dati di training (disponibili a questo link e, come accade in genere, formattati in CSV).
Inizializzazione delle librerie e caricamento dei dati
A questo punto, creiamo un nuovo progetto su Node.js (facendo riferimento alla nostra guida a Node.js nel caso non fossimo in grado), e inseriamo il codice seguente all'interno del file index.js:
const ml = require("ml-regression");
const csv = require("csvtojson");
const SLR = ml.SLR; // Simple Linear Regression
const csvFilePath = "advertising.csv"; // path al file .csv
let csvData = [],
x = [],
y = [];
let regressionModel;
Sfruttiamo ora il metodo fromFile della libreria csvtojson per caricare il contenuto del file .csv all'interno della variabile csvData:
csv()
.fromFile(csvFilePath)
.on("json", (jsonObj) => {
csvData.push(jsonObj);
})
.on("done", () => {
prepareData();
performRegression();
});Preparare i dati per la regressione
A questo punto, dobbiamo convertire i dati salvati all'interno della variabile csvData (in formato JSON) in un formato tale da permetterci di effettuare la nostra regressione. Per farlo, dovremo popolare i due array x e y, rappresentanti rispettivamente gli input e gli output del nostro training set. A tal proposito, useremo la funzione prepareData(), così definita:
function prepareData() {
/**
* Ogni riga dell'oggetto csvData sarà così formattata:
* {
* TV: "10",
* Radio: "100",
* Newspaper: "20",
* Sales: "1000"
* }
*/
csvData.forEach((row) => {
X.push(parseFloat(row.Radio));
y.push(parseFloat(row.Sales));
});
}Addestramento e predizione
Non resta quindi che capire come eseguire la regressione vera e propria, implementata con la seguente funzione:
function performRegression() {
regressionModel = new SLR(x, y);
console.log(regressionModel.toString(3));
}
La prima istruzione della funzione performRegression() effettua l'addestramento, e quindi la regressione vera e propria. Tramite il metodo toString() (il cui parametro rappresenta il numero di decimali da utilizzare per la visualizzazione dei numeri decimali), possiamo inoltre convertire il modello in una forma facilmente leggibile (del tipo f(x) = a * x + b, dove a e b sono i parametri ottenuti per mezzo della regressione).
A questo punto, non resta che usare il modello appena addestrato per effettuare qualsiasi tipo di predizione. Per farlo, possiamo utilizzare il metodo predict(), a cui passeremo il nostro input:
regressionModel.predict(my_input)Conclusioni
Quello appena visto è ovviamente solo un semplice esempio di applicazione del machine learning su Javascript. Molte altre informazioni sull'uso della libreria ml.js possono essere reperite facendo riferimento agli esempi già pronti disponibili sul repository GitHub ufficiale.
Quello appena visto è ovviamente solo un semplice esempio di applicazione del machine learning su Javascript. Molte altre informazioni sull'uso della libreria ml.js repository GitHub ufficiale
Nella seconda parte di questo articolo vedremo un'altra tecnica di machine learning, sempre usando ml.js kNN
Nella prima parte di questo articolo
ml.js
machine learning
ml.js
kNN
K
n
n
kNN è un algoritmo utilizzato soprattutto per la classificazione di dati: utilizzando un training set (cioè una serie di dati, ciascuno dei quali è etichettato come appartenente ad una classe), possiamo infatti addestrare kNN in modo che esso stabilisca a quale delle classi presenti nel training set appartiene un nuovo dato.
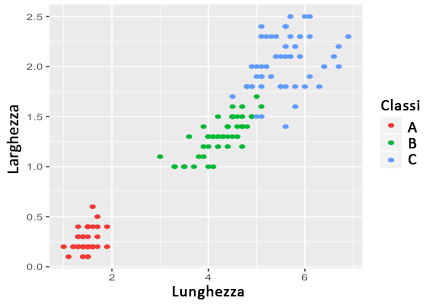
Per capire meglio come funziona kNN, consideriamo un caso pratico. L'immagine seguente mostra un training set di esempio, in cui ogni dato è costituito da due valori (lunghezza e larghezza delle foglie di una varietà di piante):
In questo caso, ogni punto è associato ad una classe. Passando questo training set (opportunamente codificato) ad un algoritmo kNN, questo sarà in grado di "imparare" in che modo classificare i dati, associando quelli nuovi ad una delle tre classi disponibili. In pratica, kNN trova i dati più vicini al dato da classificare, e associa tale dato alla classe dei dati più vicini. Il numero di dati vicini da confrontare è un parametro, tipicamente indicato come k
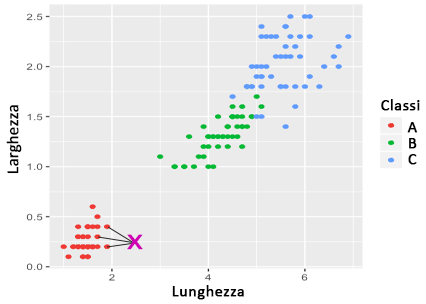
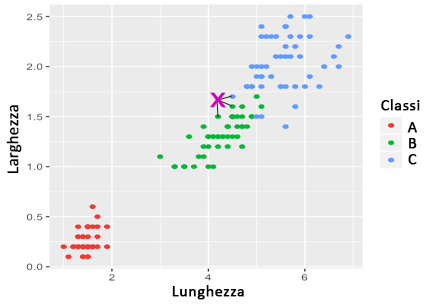
Per capire meglio, consideriamo l'esempio seguente:
In questo caso, con k
k
k
In questo esempio, il punto sarà associato alla classe maggiormente rappresentata tra quelle dei vicini (in questo caso, la classe B). Ovviamente, possono esserci casi in cui non ci sono classi dominanti (ad esempio con k
Chiarito, per grandi linee, il funzionamento di kNN, vediamo in che modo è possibile utilizzare la libreria ml.js per implementarlo.
Analogamente a quanto visto nella prima parte di questo articolo, installiamo le librerie necessarie. Possiamo utilizzare yarn:
Come funziona kNN
Utilizzare kNN
Installazione
$ yarn add ml-knn csvtojson prompt
In alternativa, possiamo optare per npm:
$ npm install ml-knn csvtojson promptml-knn implementa il kNN, mentre csvtojson (che abbiamo già usato) permetterà di caricare il training set a partire da un file CSV. Infine, utilizzeremo prompt per implementare un esempio interattivo per verificare il funzionamento del nostro algoritmo.
I dati di training che utilizzeremo (resi pubblicamente disponibili dall'Università della California) possono essere scaricati a questo link.
Inizializzazione delle librerie e caricamento dei dati
Creiamo ora un nuovo progetto su Node.js, ed aggiungiamo il codice seguente all’interno del file index.js:
const KNN = require('ml-knn');
const csv = require('csvtojson');
const prompt = require('prompt');
let knn;
const csvFilePath = 'iris.csv'; // path al file dei dati
const names = ['sepalLength', 'sepalWidth', 'petalLength', 'petalWidth', 'type']; // utilizzati per la visualizzazione
let seperationSize; // usata per separare i dati di training da quelli di test
let data = [],
X = [],
y = [];
let trainingSetX = [],
trainingSetY = [],
testSetX = [],
testSetY = [];La variabile separationSize sarà utilizzata per decidere quale frazione del training set servirà per verificare l'accuratezza del risultato dell'addestramento (cosa che, comunque, sarà automaticamente gestita da ml.js).
Usiamo quindi il metodo fromFile per caricare i dati dal file CSV:
csv({noheader: true, headers: names})
.fromFile(csvFilePath)
.on('json', (jsonObj) => {
data.push(jsonObj);
})
.on('done', (error) => {
seperationSize = 0.7 * data.length;
data = shuffleArray(data);
dressData();
});
Ogni riga del file CSV (rappresentata dalla variabile jsonObj
data
seprationSize
data.length
Il metodo shuffleArray non fa altro che mescolare casualmente i dati del training set, per renderne più uniforme la distribuzione. Una possibile implementazione (tratta da StackOverflow) è la seguente:
function shuffleArray(array) {
for (var i = array.length - 1; i > 0; i--) {
var j = Math.floor(Math.random() * (i + 1));
var temp = array[i];
array[i] = array[j];
array[j] = temp;
}
return array;
}Preparazione dei dati
Prima di continuare, diamo un'occhiata alla struttura dei dati appena caricati. Consideriamo il seguente esempio:
{
sepalLength: "5.1",
sepalWidth: "3.5",
petalLength: "1.4",
petalWidth: "0.2",
type: "Iris-setosa"
}
type rappresenta il nome della classe, che dovremo convertire in numeri. Inoltre, gli altri valori rappresentano le componenti dei dati da classificare (in questo caso, quindi, ogni punto ha 4 dimensioni): dobbiamo quindi convertire anche questi valori in numeri (tramite la funzione parseFloat). Tutto ciò è implementato all'interno della funzione dressData(), definita come segue:
function dressData() {
/**
* Le classi sono rappresentati da tre possibili
* valori del parametro type:
*
* 1. Iris-setosa
* 2. Iris-versicolor
* 3. Iris-virginica
*
* Convertiremo questi valori in numeri, secondo
* lo schema seguente:
*
* Iris-setosa -> 0
* Iris-versicolor -> 1
* Iris-virginica -> 2
*/
let types = new Set();
data.forEach((row) => {
types.add(row.type);
});
typesArray = [...types];
data.forEach((row) => {
let rowArray, typeNumber;
rowArray = Object.keys(row).map(key => parseFloat(row[key])).slice(0, 4);
typeNumber = typesArray.indexOf(row.type);
X.push(rowArray);
y.push(typeNumber);
});
trainingSetX = X.slice(0, seperationSize);
trainingSetY = y.slice(0, seperationSize);
testSetX = X.slice(seperationSize);
testSetY = y.slice(seperationSize);
train();
}Addestramento e predizione
Si noti che abbiamo usato la funzione dressData() anche allo scopo di effettuare il training vero e proprio, mediante la funzione train(), definita come segue:
function train() {
knn = new KNN(trainingSetX, trainingSetY, {k: 7});
test();
}Il metodo di addestramento richiede due argomenti obbligatori: i dati di input (qui denominati trainingSetX, e comprendenti in questo caso i valori di sepalLength, sepalWidth, petalLength e petalWidth) e quelli di output (qui denominati trainingSetY, e rappresentanti la classe di appartenenza di ogni entry). Inoltre, opzionalmente è possibile specificare il valore di k, che per default è pari a 5. In questo caso, addestreremo kNN per funzionare con k = 7.
Una volta preparato il training set, valutiamone le performance con il metodo test(), che stima quanti errori di predizione vengono effettuati:
function test() {
const result = knn.predict(testSetX);
const testSetLength = testSetX.length;
const predictionError = error(result, testSetY);
console.log(`Dimensione Test Set: ${testSetLength}nNumero di errori di classificazione: ${predictionError}`);
predict();
}
La funzione error()
function error(predicted, expected) {
let misclassifications = 0;
for (var index = 0; index < predicted.length; index++) {
if (predicted[index] !== expected[index]) {
misclassifications++;
}
}
return misclassifications;
}A questo punto, non resta che provare ad effettuare le predizioni. Per farlo, possiamo sfruttare la libreria prompt
function predict() {
let temp = [];
prompt.start();
prompt.get(['Sepal Length', 'Sepal Width', 'Petal Length', 'Petal Width'], function (err, result) {
if (!err) {
for (var key in result) {
temp.push(parseFloat(result[key]));
}
console.log(`With ${temp} -- type = ${knn.predict(temp)}`);
}
});
}