
Una delle differenze più evidenti tra DBMS relazionali e NoSQL è il diverso modo di mettere in relazione i record tra loro. In questa lezione, esploreremo le modalità supportate da OrientDB mettendole a confronto con gli omologhi meccanismi del paradigma relazionale.
Relazioni e JOIN nei DBMS relazionali
Negli RDBMS, i dati disposti su più tabelle sono messi in relazione mediante le chiavi primarie che identificano univocamente i record e che vengono sfruttate per stabilire collegamenti con altri record. Esistono per lo più tre tipi di relazioni nel paradigma relazionale:
- relazione uno-a-uno: due record, presenti in tabelle diverse, sono messi in relazione dalla chiave primaria di uno dei due. L'utilità risiede nella possibilità di arricchire di ulteriori dettagli un record presente in una tabella. Nella figura seguente supponiamo di avere una tabella con un elenco di calciatori ed in un'altra i record contenenti le caratteristiche di ognuno: il campo id_calciatore della prima tabella stabilisce il collegamento.
Figura 1. Relazione uno-a-uno negli RDBMS
 Figura 1. Relazione uno-a-uno negli RDBMS (click per ingrandire)
Figura 1. Relazione uno-a-uno negli RDBMS (click per ingrandire)

- relazione uno-a-molti: a volte, più record di una tabella possono corrispondere ad un unico elemento di un'altra. Prendiamo il caso di più squadre ed i loro calciatori: ogni giocatore appartiene ad un solo team al quale, al contrario, appartengono
più giocatori. La figura seguente mostra come ciò può essere rappresentato: ogni record della tabella Calciatori possiederà il
riferimento alla chiave primaria della Squadra di appartenenza:Figura 2. Relazione uno-a-molti negli RDBMS (click per ingrandire)
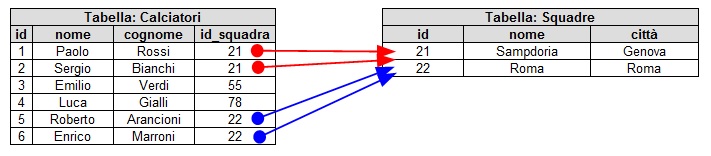
- relazione molti-a-molti: altro caso molto utile è quando due tabelle possono avere reciprocamente una relazione multipla.
In questo caso, è necessario aggiungere un'ulteriore tabella in cui vengano registrate le corrispondenze tra le chavi dei record collegati.
La figura seguente mostra una relazione molti-a-molti dove viene memorizzato lo storico delle squadre in cui ogni giocatore ha
militato: ad ogni squadra saranno appartenuti molti giocatori e, viceversa, ogni giocatore avrà probabilmente giocato in più squadre.Figura 3. Relazione molti-a-molti negli RDBMS (click per ingrandire)

Il meccanismo che si usa per estrapolare informazioni dalle relazioni create in questi modi è il JOIN, molto usato ma spesso anche costoso in termini di prestazioni: in particolare, il costo di un JOIN è proporzionale al numero di record delle tabelle coinvolte. Per migliorarne le performance, si può far uso di indici, che velocizzano le operazioni di lettura ma ralleno quelle di scrittura e cancellazione. Pertanto tale idea non è universalmente adeguata, soprattutto quando si ha a che fare con grandi moli di dati.
OrientDB non fa uso di JOIN, e risolve il problema delle relazioni in stile NoSQL offrendo due soluzioni: link e record embedded.
I link
Sfruttando i vantaggi della propria natura a grafo, OrientDB collega le informazioni in record diversi affidandosi ai RID (Record ID) di cui si è parlato nelle lezioni precedenti. Tali riferimenti, grazie alla loro composizione che include il numero del cluster ed un altro progressivo, rendono i record inconfondibili nel database e saranno sufficienti a stabilire un collegamento diretto con un altro record.
Se uno o più record dovranno fare riferimento ad un altro, è sufficiente creare un campo di tipo LINK. Si pensi agli esempi della relazione uno-a-uno oppure al caso di più record relativi ad un singolo calciatore, che puntano ad un'unica squadra.
Qualora un record avesse bisogno di conservare il riferimento a più record, esistono altri tipi che rappresentano vere e proprie strutture dati:
- LINKLIST: elenco ordinato di link;
- LINKSET: elenco non ordinato di link, che non ammette duplicati;
- LINKMAP: elenco di coppie chiave/valore, in cui le chiavi sono stringhe ed i valori sono i link dei record cui si vuole
puntare.
L'aspetto interessante di questi diversi tipi di dato consiste nella possibilità di archiviare i link non solo come insieme di valori, ma dotandoli anche di politiche di accesso a seconda del senso della relazione.
Record Embedded
Quando si stabilisce una relazione come illustrato nel paragrafo precedente, si mettono in connessione record indipendenti tra loro. A volte capita che un oggetto vada messo in collegamento con un record, ma che non ci siano i presupposti affinchè sia memorizzato separatamente da esso. In questo caso, non si ricorrerà ad una relazione bensì si creerà un campo del record contenente l'oggetto stesso, annidato o embedded secondo la terminologia ufficiale.
La differenza principale tra link e record embedded consiste nel fatto che il primo tipo collega record indipendenti dotati ognuno di un proprio RID, mentre il secondo vede un record principale fornito di RID ed un record innestato in esso ma sprovvisto di un proprio RID. Quest'ultimo approccio ha il vantaggio di evitare relazioni in fin dei conti superflue e può essere messo in parallelo con il pattern della composizione dell'UML.
Anche per i record embedded esistono appositi tipi di dato:
- EMBEDDED: un singolo nodo innestato;
- EMBEDDEDLIST: elenco ordinato di record;
- EMBEDDEDSET: elenco non ordinato di record, che non ammette duplicati;
- EMBEDDEDMAP: elenco di coppie chiave/valore, in cui le chiavi sono stringhe ed i valori sono i record embedded.
TRAVERSE
Stabilite le relazioni, uno dei principali problemi è navigare i record attraverso esse, recuperandone i dati. Nei database relazionali, questa operazione si implementa con le operazioni di JOIN, OrientDB invece mette un comando SQL apposito a disposizione: TRAVERSE.
TRAVERSE può essere considerato l'equivalente di una SELECT "intelligente", che recupera i dati tramite i riferimenti ai nodi collegati. Supponiamo di avere due classi collegate, Calciatore e Squadra:
CREATE CLASS Calciatore;
CREATE PROPERTY Calciatore.nome STRING;
CREATE PROPERTY Calciatore.cognome STRING;
CREATE PROPERTY Calciatore.id_squadra LINK;
CREATE CLASS Squadra
CREATE PROPERTY Squadra.nome STRINGInseriamo una nuova Squadra:
INSERT INTO Squadra SET nome='Milan'e colleghiamo il record di un nuovo calciatore:
INSERT INTO Calciatore SET nome='Carlo',cognome='Bianchi',id_squadra=#15:0Il RID #15:0 identifica il record corrispondente alla squadra di appartenenza, e tale riferimento ci verrà fornito in output dalla console.
A questo punto si può fare uso di TRAVERSE per estrapolare i dati del calciatore collegati a quelli relativi al team in cui esso milita:
TRAVERSE * FROM Calciatore
Vedremo l'output mostrare sia i dati appartenenti ai record della classe Calciatore che quelli collegati. Il comando TRAVERSE ha varie opzioni per affinare la ricerca, alcune delle quali saranno usate nei successivi esempi della guida. Per il momento, ci limitiamo a segnalare l'apposita voce della documentazione ufficiale.
Se vuoi aggiornamenti su Database inserisci la tua email nel box qui sotto:
