
La storia di Git è profondamente legata a quella del Kernel Linux, quest'ultimo è un progetto rilasciato sotto licenza Open Source che per un periodo di circa 10 anni a partire dalla sua prima implementazione, risalente al 1991, veniva gestito in ambito collaborativo tramite lo scambio di semplici package (più propriamente degli archivi compressi con TAR) ai quali venivano aggiunte delle patch per le correzioni e gli aggiornamenti per il passaggio alle nuove release.
Tale sistema finì per rivelarsi eccessivamente macchinoso mano a mano che l'architettura del Kernel diveniva più articolata, da qui l'esigenza di adottare un DVCS.
Linus Torvalds e gli altri appartenenti alla community optarono per una soluzione proprietaria come BitKeeper della BitMover Inc.; per alcuni anni quest'ultima mise a disposizione la possibilità di utilizzare gratuitamente il proprio software per il controllo di versione, ma tale formula venne revocata nel 2005 costringendo gli sviluppatori del Kernel a realizzare una soluzione propria, questa volta libera e aperta, avvalendosi dell'esperienza maturata con BitKeeper.
Ponendosi in aperta polemica con sistemi preesistenti come Subversion, che egli riteneva architetturalmente poco sensati, Torvalds decise di creare un'alternativa veloce, scalabile e completamente distribuita che fosse in grado di supportare lo sviluppo di progetti di grandi dimensioni sulla base di più rami paralleli, rifiutando in questo modo un approccio centralizzato improntato sull'implementazione lineare.
L'importanza degli snapshots
A caratterizzare Git è il fatto che esso non funziona come la maggior parte degli altri sistemi per il versioning, a questo proposito abbiamo già citato Subversion che Torvalds considerava un esempio di come non sviluppare un software per il controllo di versione; questi ultimi infatti sono stati concepiti non di rado con lo scopo di memorizzare le informazioni sotto forma di elenchi in grado di riportare i cambiamenti subiti dai progetti gestiti. Si hanno così a disposizione degli insiemi di file associati alle modifiche eseguite con il passare del tempo.
Nel caso specifico di Git, i dati vengono rappresentati invece come delle istantanee, o snapshots, quando si memorizza lo stato di un progetto il sistema crea quindi un'immagine di tutti i file al momento corrente; in sostanza Git non fa riferimento alle differenze tra le varie versioni, ma ne "fotografa" gli stati di avanzamento.
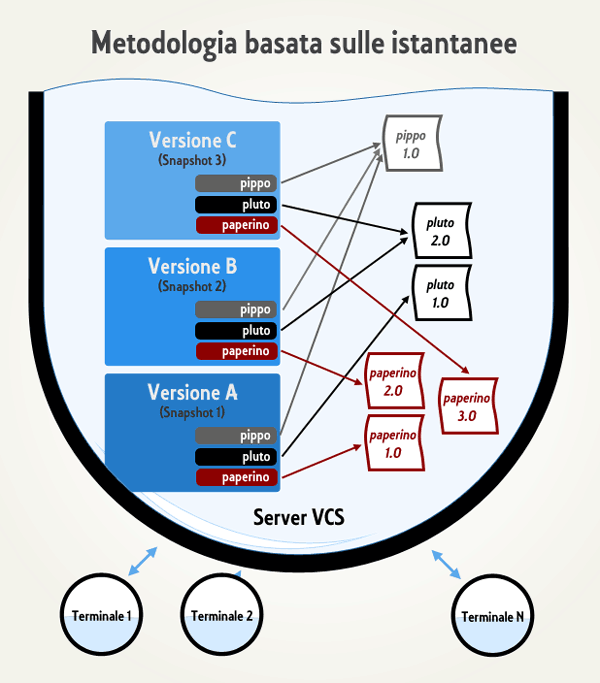
Il vantaggio a livello di efficienza risulta immediatamente evidente, questo perché nel caso in cui un file non dovesse subire delle modifiche, il DVCS non provvederà a salvarlo nuovamente ma si limiterà a definire un collegamento con il salvataggio già effettuato.
Lavorare offline con Git
Dal punto di vista della produttività, il maggior livello di efficienza descritto in precedenza si traduce anche in velocità di esecuzione più elevate per le diverse procedure, in Git infatti vengono eliminate quasi tutte le latenze che potrebbero verificarsi nel caso in cui ad un sistema distribuito si preferisca un impianto centralizzato basato su un singolo server remoto; ciò è dovuto in particolare al fatto che, grazie alla sua architettura, quasi tutte le operazioni per la memorizzazione si svolgono in locale e a carico di risorse disponibili localmente.
La possibilità di lavorare localmente, e quindi offline, rappresenta un vantaggio non indifferente, in mancanza di una connessione si potrà operare su un progetto affrontando tutte le fasi del versioning fatta eccezione di quella dell'upload, che potrà essere completata non appena stabilito un nuovo collegamento.
Tutte quelle operazioni che un CVCS non consentirebbe disponendo del solo ambiente remoto, come per esempio inviare le modifiche al database, visualizzare lo storico di un progetto o verificare le differenze tra due versioni lontane nel tempo, con Git saranno invece possibili.
Gestione del flusso di lavoro in Git
Sostanzialmente i file di un progetto in Git possono assumere tra stati differenti:
| Stato | Descrizione |
|---|---|
| Committati | I file sono stati memorizzati localmente nel database. |
| Modificati | I file hanno subito dei cambiamenti ma non sono stati ancora committati. |
| In stage | I file sono stati coinvolti da modifiche e verranno inclusi in un'istantanea con la prossima commit. |
Agli stati elencati corrispondono altrettante sezioni di un progetto gestito tramite Git:
| Sezione | Descrizione |
|---|---|
| Directory di Git | L'area per il salvataggio del database e dei metadati di un progetto, cioè le informazioni copiate in fase di clonazione di un repository. |
| Directory di lavoro | La copia di backup (checkout) di una determinata versione di un progetto, per ottenerla si estraggono i file dall'archivio della directory di Git in modo da poterli manipolare dal proprio disco. |
| Area di stage | Definita anche come "Indice", è un'area rappresentata da un file contenente le informazioni relative alla commit successiva. |
Un file modificato e aggiunto in area di stage si dirà "in stage", una release presente nella directory di Git si dirà "committata", una version estratta, modificata ma non "in stage" si dirà "in lavorazione". Tenendo conto degli stati e delle sezioni che regolano il funzionamento di Git, è possibile definire un flusso che in pratica prevede di eseguire le operazioni per la modifica dei file nella directory di lavoro, fatto questo si potrà procedere con l'aggiunta degli snapshots nell'area di stage in modo da poter eseguire la necessaria commit per il salvataggio di file nella directory del DVCS.
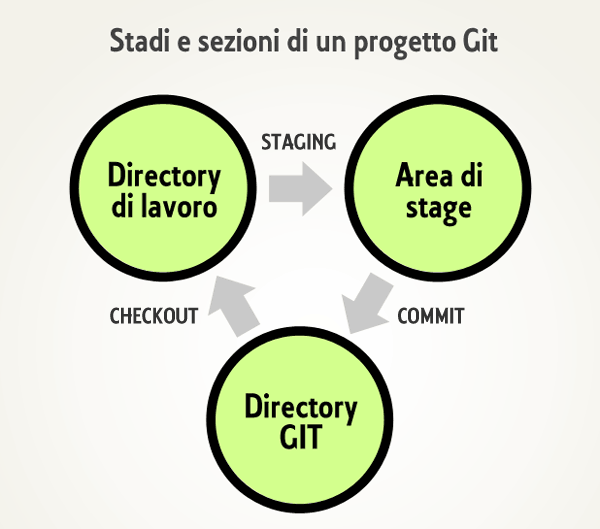
In Git il workflow si basa quindi sul passaggio di stato, un sistema incentrato sulla transizione di un progetto da una sezione ad un'altra dove i file potrebbero subire delle modifiche accidentali corrompendosi; per evitare che ciò avvenga Git utilizza un sistema di controllo basato sul checksum, cioè una sequenza di bit che viene adottata per verificare l'integrità di un dato. Nel caso specifico ciascuno stato sarà associato ad un hash (cioè una stringa di lunghezza predefinita riferita ad un elemento dotato di contenuto e struttura variabili) prodotto tramite algoritmo di cifratura SHA-1 che restituisce stringhe di 40 caratteri.
Tali stringhe verranno impiegate da Git per eseguire dei confronti, in pratica delle verifiche di integrità; un elemento verrà considerato integro, e quindi non corrotto, finche continuerà a corrispondere al checksum ad esso associato. A questo proposito è bene ricordare le parole di Linus Torvalds, che ha voluto più volte ricordare di non aver scelto SHA-1 per la sicurezza di Git, si tratta infatti di un algoritmo in parte compromesso, ma come semplice contromisura per le corruzioni accidentali.
