
Hibernate Panache è un'estensione di Hibernate che rende più veloce la scrittura di un ORM layer per le applicazioni. Un'entity Panache può essere definita in due modi. Il primo, anche il più semplice, prevede l'estensione della classe io.quarkus.hibernate.orm.panache.PanacheEntity che porta con sé il vantaggio della generazione automatica di un id indentificativo dell'Entity.
Il secondo richiede l'estensione della classe io.quarkus.hibernate.orm.panache.PanacheEntityBase e consente una gestione personalizzata della generazione degli identificativi di entità. Nella gestione dello strato di persistenza con Hibernate Panache dobbiamo scegliere tra l'utilizzo del pattern Active Record oppure del pattern Repository, quest'ultimo già esaminato nella trattazione dell'integrazione Spring Data-Quarkus.
L'idea alla base del pattern Active Record è quella di rappresentare una riga di una tabella come un'oggetto di una classe e inserendo, nella classe stessa, metodi d'interazione con il database. L'utilizzo di questo pattern è giustificato soltanto per applicazioni semplici e di piccole dimensioni in quanto consente un rapido sviluppo dello strato di persistenza applicativo.
Se l'applicazione ha invece una complessa logica di business con complesse relazioni tra tabelle Active Record può creare diversi problemi architetturali.
Active record con Panache
Iniziamo con l'inserire preliminarmente tutte le dipendenze necessarie per l'utilizzo di Hibernate Panache nel file pom.xml. Per semplicità prendiamo come riferimento il file pom.xml dell'articolo "Accesso ai dati in Quarkus: JDBC" ed inseriamo soltanto il seguente contenuto:
<!-- Hibernate ORM specific dependencies -->
<dependency>
<groupId>io.quarkus</groupId>
<artifactId>quarkus-hibernate-orm-panache</artifactId>
</dependency>Il database di riferimento è Postgres e una sua istanza pronta all'uso è ottenibile seguendo il procedimento illustrato in precedenza che prevede l'utilizzo di Docker in ambiente Linux. Come unica operazione aggiuntiva, inseriamo la seguente riga all'interno del file application.properties, anch'esso recuperato dall'articolo "Accesso ai dati in Quarkus: JDBC", per fare in modo che Hibernate crei automaticamente il database
quarkus.hibernate-orm.database.generation = drop-and-createRiprendiamo la definizione dell'entity Animal e riformuliamola seguendo il pattern Active Record:
package it.html;
import io.quarkus.hibernate.orm.panache.PanacheEntity;
import javax.persistence.Entity;
import java.util.List;
@Entity
public class Animal extends PanacheEntity {
public String name;
public String type;
public static Animal findByName(String name){
return find("name", name).firstResult();
}
public static List<Animal> findSelvatic(){
return list("type", "Selvatic");
}
}Notiamo come la struttura dell'entity preveda la definizione public dei campi della classe e l'aggiunta di metodi statici per l'interazione con il database. Questa tipologia di gestione non impedisce tuttavia di inserire i classici metodi getter/setter. Infatti, grazie al field access rewrite di Quarkus, quando scriviamo ad esempio un'istruzione del tipo animal.name, con animal istanza della classe Animal, se abbiamo definito un metodo getName() sarà questo ad essere invocato invece che l'attivazione di un accesso diretto al campo.
Per poter interagire con l'entity Animal andiamo a definire un semplice servizio REST:
package it.html;
import java.util.List;
import javax.enterprise.context.ApplicationScoped;
import javax.transaction.Transactional;
import javax.ws.rs.Consumes;
import javax.ws.rs.GET;
import javax.ws.rs.POST;
import javax.ws.rs.Path;
import javax.ws.rs.Produces;
import javax.ws.rs.WebApplicationException;
import javax.ws.rs.core.Response;
import org.jboss.resteasy.annotations.jaxrs.PathParam;
import io.quarkus.panache.common.Sort;
@Path("animals")
@ApplicationScoped
@Produces("application/json")
@Consumes("application/json")
public class AnimalService {
@GET
@Path("/all")
public List<Animal> get() {
return Animal.listAll(Sort.by("type"));
}
@GET
@Path("/selvatic")
public List<Animal> getSelvatic() {
return Animal.findSelvatic();
}
@GET
@Path("{name}")
public Animal getByName(@PathParam String name) {
return Animal.findByName(name);
}
@POST
@Transactional
public Response create(Animal animal) {
if (animal.name == null || animal.type == null) {
throw new WebApplicationException("Indalid data.", 422);
}
animal.persist();
return Response.ok(animal).status(201).build();
}
}Nel codice presentato evidenziamo due aspetti interessanti. Il primo riguarda l'uso di metodi ereditati dalla classe PanacheEntity, uno di questi è listAll() per recuperare tutte le istanze di entity. Il secondo aspetto è la possibilità di rendere persistente un'entity invocando il metodo persist() (anch'esso ereditato dalla classe PanacheEntity) in un contesto transazionale.
Avere a disposizione metodi di accesso già implementati, evidenzia come sia possibile realizzare velocemente applicazioni molto semplici che richiedano operazioni CRUD su un insieme limitato di tabelle.
Avviamo l'applicazione Quarkus eseguendo il comando quarkus:dev da Intellij e utilizziamo Postman per richiamare il servizio REST al fine di visualizzare ed inserire istanze della classe Animale:
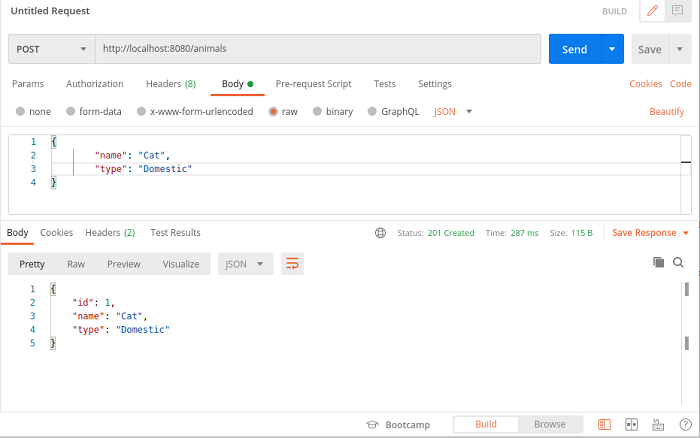
Figura 1. Inserimento
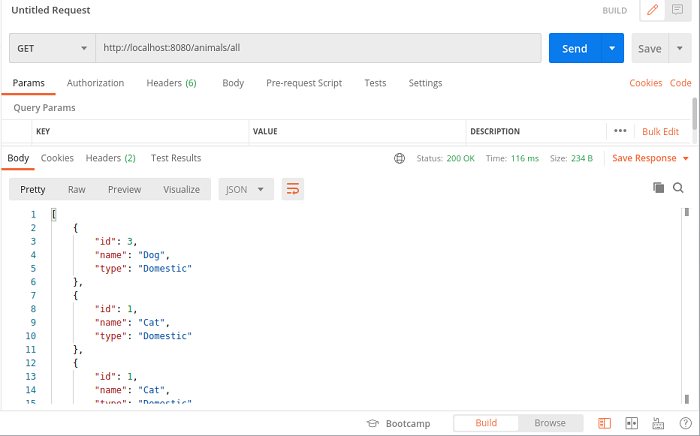
Figura 2. Lista totale
Repository pattern con Panache
Utilizzando il Repository pattern definiamo le entities come normali entities JPA:
@Entity
public class Person {
@Id
@GeneratedValue
private Long id;
public String name;
public String type;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public LocalDate getType() {
return type;
}
public void setType(LocalDate type) {
this.type = type;
}
}In questo contesto Panache può ancora semplificare la stesura del codice. Possiamo infatti evitare di scrivere i metodi get/set per ogni campo estendendo la classe PanacheEntityBase oppure estendendo ancora la classe PanacheEntity per avere il beneficio di un ID generato automaticamente.
Per realizzare un repository Panache, ed ottenere gli stessi benefici visti in precedenza, è sufficiente estendere la classe PanacheRepository ed inserirvi i propri metodi:
@ApplicationScoped
public class AnimalRepository implements PanacheRepository<Animal> {
public Animal findByName(String name){
return find("name", name).firstResult();
}
public List<Aninal> findSelvatic(){
return list("type", "Selvatic");
}
}all'interno del servizio rest andremo poi ad iniettare un riferimento al repository:
@Inject
AnimalRepository animalRepository;Se vuoi aggiornamenti su Development inserisci la tua email nel box qui sotto:

