
L'XML (eXtensible Markup Language) permette di definire una grammatica per descrivere e formattare i documenti strutturati, consentendo il trasferimento dei dati e delle informazioni utili per elaborarli. Tra i vantaggi derivanti dall'XML vi è la possibilità di trasferire dati che siano comprensibili sia per un osservatore umano che per un elaboratore.
C'è però il rovescio della medaglia. L'utilizzo dei metadati comporta un incremento di dati da trasmettere. Al contempo, al crescere delle dimensioni dei documenti da trasmettere, l'XML comincia a diventare arduo da interpretare per occhi umani. Inoltre, spesso non vi è la necessità di mantenere il documento in forma comprensibile tra una elaborazione e l'altra.
Con il tempo si è conseguentemente diffusa la richiesta di strumenti utili a ottimizzare i documenti XML. In questo articolo si presenterà il problema, diversi approcci utili a risolverlo, e la soluzione offerta dal W3C (World Wide Web Consortium). Si introdurranno infine alcuni strumenti per l'ottimizzazione in Java.
L'articolo è costituito dalle seguenti sezioni:
- Introduzione al problema e tecniche di risoluzione
- L'approccio del W3C: EXI Efficient XML Interchange)
- Altre soluzioni per l'ottimizzazione dell'XML in Java
- Vincoli di memoria e banda markup
- Vincoli di elaborazione overhead
- Dati binari payloads
- Accesso casuale XML Namespaces
Introduzione al problema e tecniche di risoluzione
Come si è già accennato, sono diversi i motivi che hanno portato alla richiesta dell'ottimizzazione di documenti XML. Un problema parallelo è quello dell'ottimizzazione delle query XML, ma esso è fuori dalla portata dell'articolo.
In questa sezione si presenteranno le principali complicazioni che hanno portato alla richiesta di ottimizzazione, anche se si sottolinea che le cause spesso si sovrappongono e non si escludono. A seguire, le principali soluzioni con il relativo trade-off.
I problemi…
… e le soluzioni
Fin qui abbiamo introdotto i problemi. Passando alle soluzioni, la prima cosa da dire è che vi è un trade-off dovuto al fatto che ogni soluzione rappresenta un compromesso tra i benefici offerti dall'XML e il desiderio di migliorare le performance. Tra i principali vantaggi, l'XML è auto-esplicativo, facilmente estensibile, leggibile ad occhio umano, concettualmente semplice. Un'eventuale ottimizzazione dovrebbe tener conto di questi aspetti e preservarli. In più dovrebbe essere senza perdita, ossia partendo da un documento ottimizzato si dovrebbe poter ricostruire il documento XML originario.
Sono state offerte diverse soluzioni al problema, tra queste vi sono i metodi di compressione basati su Gzip o codifica ASN.1. Ma sarebbe preferibile utilizzare la formattazione come base per un'ottimizzazione mirata. E' possibile classificare le soluzioni nel seguente modo:
| Soluzione | Descrizione |
|---|---|
| Compressione testuale | tecnica tradizionale di compressione per ridurre le dimensioni di un documento. Presenta però gli svantaggi di richiedere tempo e tipicamente di rendere il documento opaco fino alla decompressione. |
| Codifica sulla lunghezza | codificare la lunghezza di elementi, attributi e altre strutture permette di accedere efficientemente e arbitrariamente a determinate parti del documento perché non occorre analizzare tutti i byte. Il problema è che il documento tende a divenire difficilmente comprensibile ad occhio umano. |
| Dizionario dei tag | rimpiazzare l'XML QNames |
| Riordino selettivo | la flessibilità nella serializzazione del documento può permettere ad alcune applicazioni di migliorare le prestazioni, specialmente se devono accedere solo a parti del documento analizzato. Ciò può andare a discapito della leggibilità. |
| Ricodifica selettiva | alcuni tipi di dati dell'XML, ad esempio il binario base64 |
| Codifica basata sui tipi | quando il tipo dell'informazione è noto, può essere utilizzato per ricodificare un documento ponendo i tipi in forma canonica, ad esempio con lunghezza fissa. La forma nativa verrebbe recuperata senza problemi. Ciò comporta un'elaborazione poco dispendiosa, al costo della leggibilità e della modificabilità del documento. |
| Codifica basata sullo schema | basandosi sulla struttura degli schemi XML associati ai documenti, è possibile generare particolari formati, richiedendo però che gli utilizzatori condividano la stessa versione dello schema per generare e consumare un particolare documento. Questa tecnica permette di abbattere le richieste di elaborazione e lo spazio, ma non è auto descrivente, per cui pone problemi al momento dell'evoluzione del formato e normalmente non risulta particolarmente leggibile. |
In generale, è probabile che uno strumento di ottimizzazione combini diverse delle tecniche presentate al fine di aumentarne l'efficacia.
Possiamo dire pertanto che l'ottimizzazione consiste in un insieme di metodi per riformattare un documento XML in modo da minimizzarne l'impatto in termini di risorse utilizzate, siano esse banda, memoria, e così via.
Un esempio
Si presenta un esempio di come potrebbe lavorare l'ottimizzazione. Partiamo da una classica struttura "Persona":
<Persona>
<Nome>Pippo</Nome>
<Cognome>De Pippis</Cognome>
</Persona>Una possibile ottimizzazione potrebbe portare l'XML in forma piatta, rimpiazzando il contenuto degli elementi con degli attributi, ad esempio:
<Persona Nome="Pippo" Cognome="De Pippis"/>Ciò ha portato a una significativa compressione dello spazio occupato (un risparmio di circa un terzo), ma risulta possibile recuperare il documento originario? In un caso così semplice si, ma come faremmo a distinguere gli attributi originari da quelli creati dall'ottimizzazione?
Il problema non è così semplice, vedremo pertanto nel prossimo capitolo una soluzione studiata dal W3C.
L'approccio del W3C: EXI (Efficient XML Interchange
Al fine di massimizzare il numero di sistemi e applicazioni in grado di comunicare tramite dati XML, il W3C ha avviato dei lavori che hanno portato alla specifica del formato EXI Efficient XML Interchange
EXI basa l'ottimizzazione su un approccio guidato dalla grammatica, utilizzando un modulo chiamato EXI processor streams EXI
EXI è definito schema informed
In questo capitolo si introdurranno i concetti di base della specifica e alcune valutazioni delle prestazioni offerte. Seguiranno delle valutazioni circa l'impatto del formato sulle applicazioni che utilizzano l'XML e, per finire, si presenteranno le principali implementazioni della specifica.
Elementi del formato
In fase di codifica la grammatica viene utilizzata per mappare un flusso di informazioni XML in uno stream più piccolo di eventi. Successivamente, il flusso di eventi viene codificato tramite dei codici d'evento, simili ai codici di Huffman. I codici formano una sequenza di valori che può essere compressa qualora desiderato, rimpiazzando i valori frequenti con specifici pattern per ridurre ulteriormente le dimensioni.
Un EXI stream è costituito da un header, EXI header, seguito da un body, EXI body. Il body rappresenta il contenuto del documento, mentre l'header contiene le informazioni sul formato EXI utilizzato e sulle opzioni adoperate per codificare il contenuto (ad esempio se è stata abilitata la compressione, se è schema informed e così via).
Un EXI header potrebbe iniziare con un EXI Cookie, un campo che ha lo scopo di indicare che lo stream che segue è parte di un EXI stream. Il campo consiste di quattro caratteri ($, E, X e I) e serve a distinguere gli EXI stream da altri tipi.
L'EXI body è costituito da una sequenza di eventi, gli EXI events. Come nel caso dell'XML, gli eventi occorrono in concomitanza di elementi di inizio e fine. Agli eventi vengono associati i codici evento, codificati in binario.
Pertanto, in estrema sintesi, al documento originario vengono associati una serie di eventi, a loro volta codificati in binario.
Prestazioni
Per valutare l'efficacia di EXI, sia dal punto di vista della capacità di compattazione che per l'efficienza di elaborazione, sono state effettuate delle valutazioni di seguito riportate.
Per ulteriori informazioni sui test, consultare EXI Evaluation.
Compattazione: confronti con Gzipped e ASN 1.0
Confronto tra EXI (in blu in entrambi grafici), Gzipped (a sinistra) e ASN. 1 (a destra)
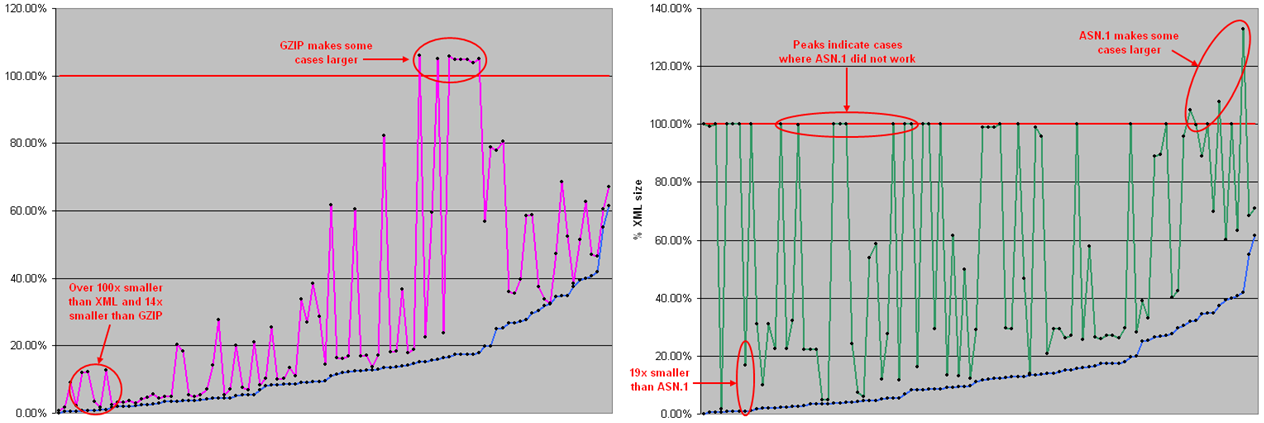
I due grafici mostrano il confronto tra una delle implementazioni della specifica EXI (Efficient XML 4.0), Gzipped e ASN. 1. Sulle ordinate troviamo la capacità di compattazione espressa in percentuale sulla base del documento originario. I risultati vengono presentati posizionando a sinistra i risultati migliori. Con EXI in alcuni casi si è arrivati ad ottenere un documento fino a 100 volte più piccolo dell'originario, mentre i risultati medi si aggirano su una riduzione di circa 10 volte.
EXI produce risultati sensibilmente migliori rispetto a Gzipped e ASN 1.0. Fino a 10 volte rispetto a gzip (ad esempio con messaggi basati su un alto volume di piccoli dati, come i dati tipici della geo localizzazione), e fino a 20 volte nel caso di ASN 1.0 (che in diversi casi non produce risultati apprezzabili).
Velocità di elaborazione
Per valutare i vantaggi dal punto di vista della velocità di elaborazione, si sono effettuate le operazioni di base di analisi e serializzazione con e senza EXI e con e senza EXI con compressione. Nel corso di operazioni di decodifica EXI ha migliorato le prestazioni mediamente di circa 15 volte senza compressione e di circa 9 volte con la compressione.
Per operazioni di serializzazione le prestazioni sono migliorate mediamente di 6 volte senza compressione e di circa 5 volte con la compressione.
Impatto di EXI
EXI è nato per essere compatibile con l'XML senza porre particolari aggravi sulle applicazioni che usano lo usano. Almeno in teoria. L'obiettivo è stato parzialmente soddisfatto, ma è possibile ridurne ulteriormente l'impatto.
| Caratteristica | Descrizione |
|---|---|
| Leggibilità | uno dei punti dolenti deriva dall'adozione di un formato binario che ha portato a sacrificare la leggibilità del documento ottimizzato. A meno di utilizzare specifici editor, uno dei principali vantaggi dell'XML è perso. |
| APIs | almeno formalmente, EXI dichiara di supportare tutte le APIs comunemente usate per processare gli XML, per cui EXI non avrebbe un impatto immediato sulle APIs già esistenti. In pratica, utilizzare le API preesistenti richiede che tutti i nomi e il testo di un documento EXI vengano convertiti in stringhe. Si può pertanto aspettare di più per limitare questo aspetto dell'impatto di EXI. |
| Sicurezza | firma e criptazione possono essere utilizzate con EXI, con qualche accorgimento. La firma è utilizzabile con EXI specificando un algoritmo esistente di canonizzazione (ad esempio Canonical XML MimeType EncryptedData |
| Progetto | Descrizione |
|---|---|
| Efficient XML | Probabilmente l'implementazione più matura della specifica, in grado di fornire supporto specifico per web services |
| EXIficient | progetto Open source avviato dalla Siemens AG. Supporta tutte le caratteristiche e le modalità di codifica di EXI. Lavora su Java. |
| EXIP | progetto Open source guidato da EISLAB. Lavora su Java. |
| OpenEXI | progetto Open source guidato da Fujitsu. Lavora su C. |
Altre soluzioni per l'ottimizzazione dell'XML in Java
Oltre alla specifica EXI e alle relative implementazioni, sono state già studiate e applicate diverse soluzioni per alleviare il problema. Alcune di queste hanno puntato alla conversione verso formati di scambio più leggeri, mentre altre ad ottimizzare le performance basandosi sulla presenza di schemi noti a priori. Si presentano a titolo di esempio alcune soluzioni adottate.
| Soluzione | Descrizione |
|---|---|
| JAXB Java Architecture for XML Binding | è una specifica (con diverse implementazioni e un'implementazione di riferimento nativa in Java a partire da Java SE 6) che, partendo dallo schema XML, permette di costruire l'albero degli oggetti corrispondente al documento XML analizzato, consentendo di mantenere l'XML in memoria ed evitando la pesantezza dell'approccio DOM. L'implementazione di riferimento è già approfondita nell'articolo JAXB: l'XML in Java |
| Protocollo SOAP | dispone di un meccanismo, MTOM/XOP (Message Transmission Optimization Mechanism/XML-binary Optimized Packaging
base64Binay
hexBinary
|
| Apache Axiom | nucleo del framework Apache Axis2, oltre a supportare la costruzione dell'albero degli oggetti, fornisce supporto nativo MTOM/XOP per trasportare dati binari in maniera efficiente. |

