
Dopo aver dedicato un approfondimento completo alla piattaforma cloud di Amazon, in questo articolo vedremo da vicino l’infrastruttura cloud che propone Google. Dopo aver esaminato la console di gestione e le caratteristiche del supporto, andremo ad analizzare da vicino i servizi Google Compute Engine, per la gestione di pesanti carichi di lavoro, Google Cloud Storage, per il salvataggio e la gestione di dati nel cloud, Google Cloud SQL, per far girare database MySQL nel cloud, Google BigQuery, per analizzare grandi mole di dati, e, infine, il servizio più noto: Google App Engine, per far girare applicazioni in Java, Python, Go e, da qualche settimana, PHP nel cloud.
La Google Cloud Platform
Google, insieme a Microsoft, è stata una delle prima grandi società a proporre dei servizi di PaaS per il mercato consumer. Le due aziende infatti, affiancate da Amazon per l’offerta di IaaS (solo recentemente introdotta nelle rispettive) hanno costituito uno standard de facto per l’hosting di applicazioni di molte realtà internazionali in logica PaaS. Sebbene il servizio principe di Google si differenzi molto dal PaaS di altri vendor, Google App Engine è sostanzialmente un runtime proprietario su cui possono essere distribuite le proprie applicazioni scritte in alcuni linguaggi, come Java, Python o Go, un linguaggio nato nel 2007 ed ottimizzato per la compilazione e l’esecuzione in ambienti concorrenti.
Insieme a Google App Engine (GAE) coesistono altri servizi della piattaforma sia a supporto dello stesso GAE che utilizzabili come servizi stand-alone. Un esempio è il servizio di IaaS “Compute Engine”, ancora in fase di preview ma sulla stessa idea di analoghi prodotti IaaS sul mercato, nonostante diverse limitazioni; un altro esempio è Google Cloud SQL, servizio MySQL completamente gestito ed erogato in logica PaaS.
Google Cloud Console
Per registrarsi alla piattaforma Cloud di Google occorre recarsi su https://cloud.google.com/console dove sarà necessario autenticarsi con il proprio Google Account. Alla prima registrazione inoltre, per verificare l’identità dell’utente, è necessario farsi fare una telefonata di verifica oppure farsi inviare un SMS, sempre di verifica dell’identità, contenente un codice di conferma da registrare sul portale: questa procedura è one-shot e serve per evitare il proliferare di account fasulli.
Dalla console è possibile creare nuovi progetti, analogamente a molte altre piattaforme di cloud. Il progetto, nella GCP, è una singola unità a cui sono poi associati i diversi servizi della piattaforma: un progetto deve essere visto come una unità isolata i cui servizi non possono comunicare con quelli di altri progetti.
Al primo login verrà subito chiesto di creare un nuovo progetto; in alternativa è sempre possibile utilizzare il pulsante Create Project nella schermata di riepilogo dei progetti attivi. Un progetto deve necessariamente avere un nome ed anche un soprannome univoco all’interno della piattaforma cloud di google. Nel nostro caso sotto creiamo un esempio apposta per questo articolo:
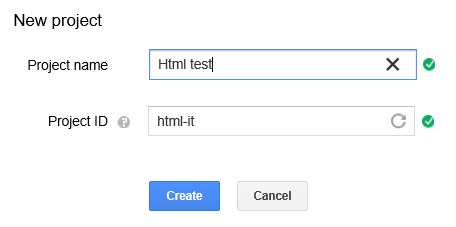
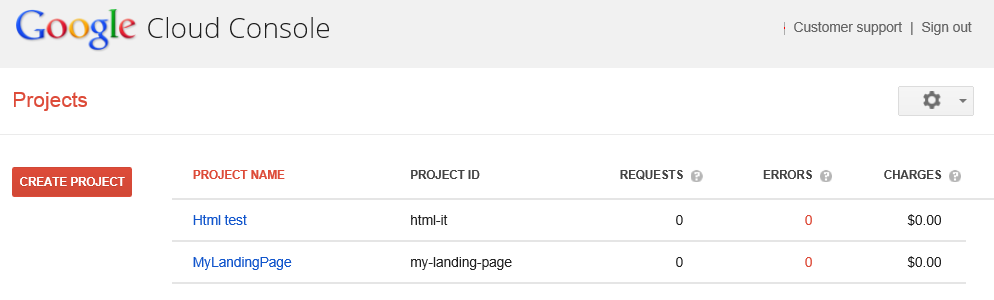
Nel caso avessimo altri progetti attivi, come in figura (sotto), avremo una lista di progetti con un riepilogo delle risorse consumate e, quindi, delle spese. Tutto ciò che riguarda il pricing dei servizi di GCP, lo affronteremo servizio per servizio, per poi avere un quadro generale dei consumi in una applicazione completa.
Livelli di supporto
Nel cloud è emerso che, al togliere della governance ai clienti, corrisponde un maggior numero di richieste di supporto. Sebbene alcune motivazioni siano del tutto fondate (disservizi, downtime, fatturazione, etc) altri motivi di contatto sono spesso legati ad un supporto tecnico e/o architetturale, che per le aziende fornitori di cloud diventa ben presto un servizio di consulenza.
Per affrontare questo genere di circostanze Google, ma non solo, ha introdotto dei pacchetti di supporto al fine di poter coprire i costi di quello che, si spera, diventi l’unico canale ufficiale di contatto tra cliente e fornitore di servizi cloud. Sebbene infatti per l’utente medio sia difficile pensare di non poter “mettere mano” sui proprio sistemi per fare troubleshooting e debugging, è sempre più dimostrato dalla pratica che questa modalità non ottimizza bensì uccide le architetture dei nostri sistemi.

Servizi
Sebbene Google sia uno dei player più importanti nel mercato dell’IT mondiale, con un numero di server incredibile solo a supporto del servizio principale, ovvero il motore di ricerca, sul mercato Cloud è ancora un prodotto che ha bisogno di crescere e, in termini di datacenter disponibili alla GCP è presente solo in Europa e negli Stati Uniti. Certamente non nella qualità di servizio, ma sicuramente nella sua eterogeneità e diversificazione, oltre che per il supporto di applicazioni scritte in linguaggi differenti. Se infatti ricordiamo AWS o Azure, vediamo che è sempre più inseguito il “cross” (platform/device/…) al fine di garantire al cliente la possibilità di avere un web-PaaS language-aware o un mobile-PaaS device-aware, e via dicendo. Con questa premessa affrontiamo ora passo-passo i vari servizi dello scenario GCP.
Google Compute Engine
Oltre al servizio più noto di GCP, Google App Engine, che vedremo per ultimo in questo articolo, da diversi mesi Google offre servizi di IaaS attraverso il nome di Google Compute Engine. Fino a poche settimane fa, il servizio era disponibile su invito o su colloquio con il team delle vendite di Google. Ora invece è disponibile pubblicamente per tutti coloro che abbiano una sottoscrizione al servizio di supporto di livello Gold. Tale sottoscrizione è abbastanza onerosa (al momento della scrittura dell’articolo costa 400$/mese) ed è il livello di supporto che permette un contatto diretto telefonico h24. Nel futuro è possibile che Google riveda questo requisito, come dichiarato ufficialmente.
Google offre uno IaaS su soli sistemi unix-based, come GCEL (Google Compute Engine Linux) o CentOS. GCEL (pronunciato “g-sel”) è una distribuzione derivata da un fork di Debian (e non supportata da Canonical Ltd.) ottimizzata per l’ambiente cloud di Google e con un numero minimo di pacchetti installati. Per gli amanti dell’open e delle internals di sistema operativo, Google mette a disposizione i kernel di GCEL su GitHub.
Tornando alle funzionalità di Compute Engine, come molti IaaS, esso permette di creare macchine virtuali di varie dimensioni (alzando però di un po’ l’asticella delle risorse rispetto ai competitor) e amministrarle via Console, API o linea di comando.
Siccome abbiamo imparato dai precedenti articoli che nel cloud il modello vincente è quello stateless, dobbiamo ricordarci che, anche qui, se vogliamo salvare in modo persistente le informazioni delle nostre istanze, esse vanno salvate su uno storage permanente (Persistent Disk) che va preventivamente montato sulle nostre macchine virtuali. Un disco persistente permette di preservare dati lungo il ciclo di vita dell’istanza e anche oltre, per esempio nel caso di failure e riattivazione o di eliminazione della macchina virtuale.
Un disco persistente può inoltre essere montato da più macchine contemporaneamente, con la limitazione che solo una di esse avrà accesso in scrittura mentre le altre lo potranno esclusivamente leggere. L’alternativa ai dischi persistenti di CE è rappresentata dagli Scratch Disk, dischi il cui contenuto non è preservato in caso di eliminazione o manutenzione delle istanze. Un disco Scratch è di default attaccato ad ogni istanza e prende il nome di disco Root.
La scelta di un disco persistente può avvenire tuttavia anche a livello di disco Root, specificando in fase di creazione che la nostra istanza dovrà girare su un Root Persistent Disk. Un buon modello di esecuzione per macchine che debbano comportarsi in modo stateful è infatti rappresentato da una configurazione di questo tipo:
- Root disk persistente con file di sistema, il più piccolo possibile
- Disco addizionale persistente con dati e programmi specifici (eventualmente condiviso in lettura)
- Uno o più dischi addizionali di tipo Scratch, per la memorizzazione transiente di dati non necessari tra un ciclo di vita della macchina e il successivo.
Ogni macchina di CE può avere fino a 16 dischi persistenti
- 28GB per macchina n1-standard-1
- 256GB per macchine n1-standard-2, n1-highmem-2, and n1-highcpu-2
- 512GB per macchine n1-standard-4, n1-highmem-4, and n1-highcpu-4
- 1024GB per macchine n1-standard-8, n1-highmem-8, and n1-highcpu-8
- Tutte le istanze in una zona potrebbero essere terminate e cancellate dai nostri progetti
- Con loro tutto il contenuto dei dischi scratch verrebbe perso
- Il contenuto dei dischi persistenti verrebbe invece preservato
- Se capitasse, l’utente verrebbe notificato e dovrebbe procedere alla ri-creazione di tutte le istanze nella zona interessata.
- Implementare una distribuzione geografica del nostro servizio: sebbene infatti sia molto raro che una zona fallisca è ancora più raro che ne falliscano due contemporaneamente. Avere una copia identica di ogni VM all’interno di una zona “backup” può aiutare, insieme al bilanciamento del carico, a garantire continuità di servizio.
- In coesione alla strategia al punto 1, è necessario implementare un sistema di bilanciamento del carico tra zone diverse. Siccome CE non offre un servizio del genere, l’unica tecnica è quella di utilizzare un DNS round-robin che cicli su N IP opportunamente configurati. Questa tecnica è tuttavia possibile solo ove si detenga il pieno controllo del sistema di risoluzione dei nomi e comunque fallisce nel caso delle cache DNS (molto frequenti).
- Utilizzare i dischi persistenti per lo storage critico. Saremo così sicuri che i dati torneranno disponibili quando la zona sarà di nuovo online o nel caso una istanza fallisca.
- Implementare degli script di startup permette di creare velocemente macchine al cui avvio verrà applicato uno script che, per esempio, può portare la macchina ad una configurazione particolare, installando pacchetti e configurando gli ambienti di esecuzione: questa strategia è una strategia vincente in molti sistemi stateless.
- Storage accessibile tramite HTTP(S)
- E tramite API REST
- Tariffa a consumo di spazio mensile
- In aggiunta alla banda consumata e al numero di richieste
- Geo-replica su più datacenter
- Gestione dei permessi su aree dello storage
- Spazio occupato al mese
- Banda consumata
- Transazioni, ovvero accessi IO allo storage
- Un'istanza con una minima quantità di RAM (0,125 GB)
- 500 MB di storage
- Banda e IO sufficienti per avere un minimo di performance
- 4,28$ di storage
- 37,49$ per il processing mensile dei dati
- Un datastore persistente che supporta query e transazioni
- Autoscaling e load balancing automatico
- Integrazione con i Google Account
- Task schedulati a supporto delle applicazioni
- Code di task per processing asincrono fuori dal contesto dell’applicazione
- URL Fetch
- Memcache
- Manipolazione immagini
- Blobstore
- Channel API
- Versioning
- Logging API
- Task queue
- Gratuita
- A pagamento
Questo significa che possiamo sia avere N dischi la cui dimensione totale sia la massima consentita che un solo disco della dimensione massima.
Snapshot
Lo stato di un disco persistente può essere catturato in qualsiasi momento tramite uno snapshot. Lo snapshot congela lo stato corrente di un disco e salva il risultato in uno storage apposito. L’operazione di snapshot è chiaramente automatizzabile tramite gli script a linea di comando e permette di effettuare backup applicativo sui nostri dischi (ricordiamo infatti che, ai fini del disaster recovery, su tutta l’infrastruttura sono previsti backup da parte di Google).
Google inoltre consiglia di effettuare snapshot in condizioni consistenti, ovvero facendo in modo di svuotare preventivamente i buffer dei dischi ed evitare quindi una potenziale perdita dei dati. Questa operazione prescinde infatti l’utilizzo o meno del cloud: ove si vada a creare uno snapshot di un disco è chiaro che i dati non ancora scritti presenti in cache, se non scaricati su disco, saranno persi.
I costi dei dischi persistenti e dei loro snapshots sono esposti nella tabella seguente:
Tabella 1 - Costi dei dischi persistenti, degli snapshot e delle operazioni di IO
| Tipo | Prezzo | ||||
| Provisioned Space (per GB/month) | $0.10 | ||||
| Snapshot Storage (per GB/month) | $0.125 | ||||
| IO Operations (per million) | $0.10 | ||||
| Configuration | Virtual Cores | Memory (GB1 | GCEU | Local Disk (GB) | Price (USD) / Hour |
| n1-standard-1-d | 1 | 3.75 | 2.75 | 420 | $0.132 |
| n1-standard-2-d | 2 | 7.50 | 5.5 | 870 | $0.265 |
| n1-standard-4-d | 4 | 15 | 11 | 1770 | $0.530 |
| n1-standard-8-d | 8 | 30 | 22 | 2 x 1770 | $1.060 |
| n1-standard-1 | 1 | 3.75 | 2.75 | 0* | $0.115 |
| n1-standard-2 | 2 | 7.50 | 5.5 | 0 | $0.230 |
| n1-standard-4 | 4 | 15 | 11 | 0 | $0.461 |
| n1-standard-8 | 8 | 30 | 22 | 0 | $0.922 |
Le macchine sopra sono definite “Standard”, al cui fianco possono essere posizionate quelle macchine di dimensione decisamente superiore (in termini di memoria o in termini di CPU) utili per l’esecuzione di strumenti di calcolo più imponenti:
Tabella 3 - Macchine ad alta Memoria
| Configuration | Virtual Cores | Memory (GB) | GCEUs | Local Disk (GB) | Price (USD) / Hour |
| n1-highmem-2-d | 2 | 13 | 5.5 | 870 | $0.305 |
| n1-highmem-4-d | 4 | 26 | 11 | 1770 | $0.611 |
| n1-highmem-8-d | 8 | 52 | 22 | 2 x 1770 | $1.221 |
| n1-highmem-2 | 2 | 13 | 5.5 | 0* | $0.244 |
| n1-highmem-4 | 4 | 26 | 11 | 0 | $0.488 |
| n1-highmem-8 | 8 | 52 | 22 | 0 | $0.975 |
Tabella 4 - Macchine ad alta CPU
| Configuration | Virtual Cores | Memory (GB) | GCEUs | Local Disk (GB) | Price (USD) / Hour |
| n1-highcpu-2-d | 2 | 1.80 | 5.5 | 870 | $0.163 |
| n1-highcpu-4-d | 4 | 3.60 | 11 | 1770 | $0.326 |
| n1-highcpu-8-d | 8 | 7.20 | 22 | 2 x 1770 | $0.653 |
| n1-highcpu-2 | 2 | 1.80 | 5.5 | 0* | $0.131 |
| n1-highcpu-4 | 4 | 3.60 | 11 | 0 | $0.261 |
| n1-highcpu-8 | 8 | 7.20 | 22 | 0 | $0.522 |
| Internet Egress (Americas/EMEA Destination) | Price (per GB/month) |
| 0-1TB | $0.12 |
| 1-10TB | $0.11 |
| 10+ TB | $0.08 |
| Internet Egress (APAC Destination) | Price (per GB/month) |
| 0-1TB | $0.21 |
| 1-10TB | $0.18 |
| 10+ TB | $0.15 |
Si noti come, per quasi tutti i vendor di cloud, sia più costoso il traffico verso l’Asia di quanto lo sia verso le Americhe o la zona EMEA (Europe Middle-East and Asia).
La seconda parte dell’articolo verrà pubblicata il prossimo lunedì
Google Cloud Storage
Per chi già conoscesse l’Azure Blob Storage o Amazon S3, non sono necessarie ulteriori competenze generali per utilizzare Google Clous Storage, lo storage della piattaforma di Google, se non quelle specifiche per il salvataggio e il reperimento delle informazioni. Da un prodotto di storage di un fornitore Cloud oggi ci si aspetta infatti una serie di caratteristiche ormai conformi ad un standard de facto. Tali caratteristiche sono:
Queste solo le funzioni necessarie ad un buon sistema di storage bucket
Per abilitare il servizio, si deve accedere alla console API di Google
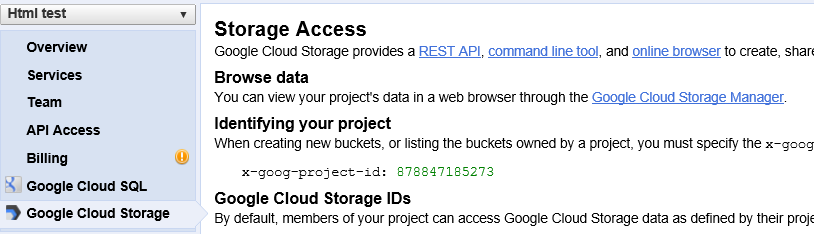
Possiamo usare uno strumento grafico di Google (Google Cloud Storage Manager - disponibile solo per browser Chrome e Firefox) che per il nostro progetto ha URL: https://sandbox.google.com/storage/?project=878847185273 dove il numero è il codice del nostro progetto.
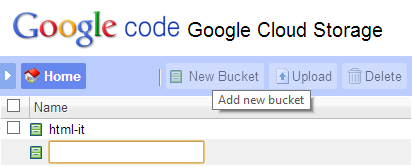
Lo strumento permette di creare nuovi bucket all’interno del nostro progetto e di gestire in modo semplificato l’upload e il download di risorse nel bucket. È lampante che l’utilizzo di uno storage siffatto sia appannaggio di strumenti di automazione, basati quindi su accesso tramite API, ma in fase di test è più che utile disporre di uno strumento del genere per velocizzare le operazioni. Per poter utilizzare il Cloud Storage è necessario attivare, se non già attivo, un profilo di billing, ovvero registrare una carta di credito per gli eventuali addebiti della piattaforma. Questo processo è disponibile nel menu Billing della console delle Google APIs.
Utilizzo del servizio
Dopo aver caricato qualche file e cartella di esempio sul bucket creato:
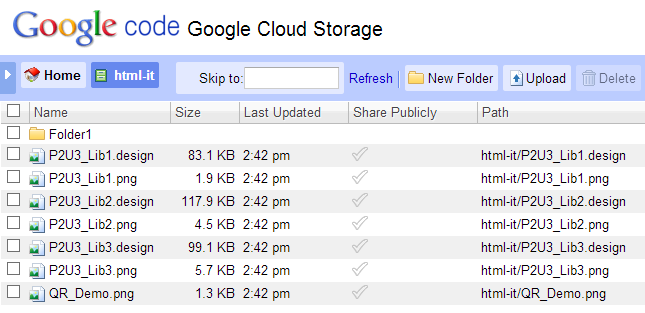
possiamo accedervi tramite HTTP:
Un esempio di accesso in scrittura via REST è il seguente:

Tariffe dello storage
Come introdotto sopra, ci aspettiamo che le tariffe di un prodotto di storage sul cloud tengano conto di:
Con queste considerazioni, notiamo che i prezzi di GCP per la parte di CS è in linea con gli altri competitor del mercato di riferimento:
Tabella 6 - Costo di occupazione
| Monthly Usage | Standard Storage (per GB per month) | Durable Reduced Availability Storage Price (per GB per month) |
| First 0-1 TB | $0.085 | $0.063 |
| Next 9 TB | $0.076 | $0.054 |
| Next 90 TB | $0.067 | $0.049 |
| Next 400 TB | $0.063 | $0.045 |
| Next 4500 TB | $0.054 | $0.042 |
Tabella 7 - Costo di banda
| Monthly Usage | Network (Egress) - Americas and EMEA* (per GB) |
Network (Egress) - Asia-Pacific (per GB) |
Network (Ingress) |
| 0 - 1TB | $0.12 | $0.21 | Free |
| Next 9TB | $0.11 | $0.18 | |
| Next 90TB | $0.08 | $0.15 |
Tabella 8 - Costo delle operazioni di IO
| Class A operations (per 1,000 requests/month) |
Class B operations (per 10,000 requests/month) |
Free operations |
| $0.01 | $0.01 | Free |
Per un dettaglio su cosa siano le operazioni di Classe A o B, si rimanda alla pagina del pricing
Google Cloud SQL
Google Cloud SQL è il prodotto di Google Cloud Platform che fornisce un database relazionale MySQL in logica PaaS, ovvero in ambiente completamente gestito. Il principio dominante di un DBMS del genere è il totale disinteresse dell’utente alle tematiche di configurazione e amministrazione del server, le quali sono completamente trasparenti all’utente e gestite da Google.
La versione di MySQL attualmente utilizzata dal PaaS è la 5.5 aggiornata con le patch e gli updates disponibili in GA; le funzionalità supportate dal Cloud SQL sono quasi tutte quelle di MySQL, ad eccezione di UDF (Uder-defined functions) e Replication; alcune istruzioni MySQL sono state escluse dal PaaS per incompatibilità con l’ambiente di esecuzione, per esempio tutte quegli statements relativi alla manipolazione di file, plugin e così via.
Creare una nuova istanza di Cloud SQL è una operazione disponibile all’interno della console della Google APIs. Dal menu servizi è possibile attivare Google Cloud SQL (previa attivazione di un profilo di billing) e procedere alla creazione dell’istanza:
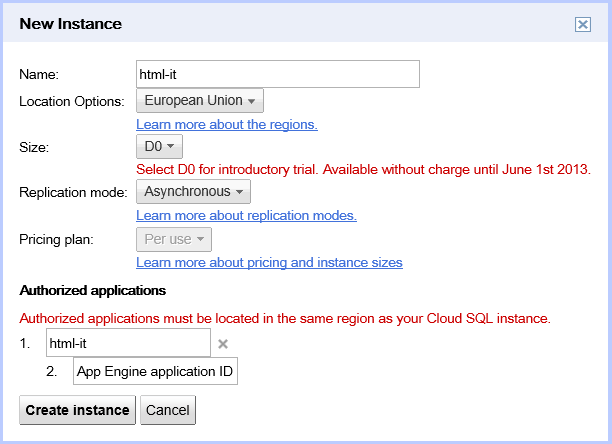
In questo esempio sto chiedendo a Google un'istanza che risieda nel datacenter europeo, di dimensione D0 (la dimensione minima consentita) e con modalità di replica asincrona. La differenza tra replica sincrona e asincrona è che nel primo caso, le scritture saranno sempre più lente ma, in caso di failure, avremo sicuramente un dato più aggiornato e consistente; nel secondo caso invece avremo delle prestazioni pressochè ottimali, con un potenziale drawback in fase di recovery da un eventuale guasto o failure.
Prima di confermare la creazione dell’istanza definisco quali applicazioni/progetti siano in grado di poter accedere al servizio SQL: questi progetti saranno automaticamente autorizzati ad accedere al servizio, diversamente dagli eventuali servizi esterni che avranno bisogno di un token OAuth2.
Dopo la creazione del servizio possiamo creare database, tabelle, viste e ogni genere di oggetto supportato. Cloud SQL permette inoltre di importare/esportare i dati tramite la funzione “Import data”/“Export data” e di default esegue backup automatizzati ogni giorno (opzione che si può disabilitare e/o modificare dal pannello). Il pannello di Cloud SQL permette infine di poter leggere i log di attività e di eseguire del semplice SQL verso il nostro server.
Costi di servizio
I costi di Cloud SQL possono essere a consumo o a pacchetto: sebbene infatti un prodotto cloud abbia senso se tariffato a consumo, è insolito pensare di avere un database “transiente”, motivo per cui in molti casi potrebbe aver senso tenere un server MySQL sempre acceso e, eventualmente, lavorare sull’up/down scaling. I pacchetti di utilizzo sono 6 è includono un pool di risorse tra RAM, Storage, IO e sono:
Tabella 9 - Pacchetti dell'offerta Cloud SQL
| Tier | RAM | Storage | I/O al giorno | Costo al giorno |
| D1 | 0.5GB | 1GB | 850K | $1.46 |
| D2 | 1GB | 2GB | 1.7M | $2.93 |
| D4 | 2GB | 5GB | 4M | $5.86 |
| D8 | 4GB | 10GB | 8M | $11.71 |
| D16 | 8GB | 10GB | 16M | $23.42 |
| D32 | 16GB | 10GB | 32M | $46.84 |
Se invece volessimo una tariffa a consumo
Tabella 10 - Voci di costo fattorizzate di Cloud SQL
| Resource | Charge |
| D1 Database Instance (0.5GB RAM) | $0.10 ad ora |
| D2 Database Instance (1GB RAM) | $0.19 ad ora |
| D4 Database Instance (2GB RAM) | $0.38 ad ora |
| D8 Database Instance (4GB RAM) | $0.77 ad ora |
| D16 Database Instance (8GB RAM) | $1.54 ad ora |
| D32 Database Instance (16GB RAM) | $3.08 ad ora |
| 1GB Storage | $0.24 al mese |
| I/O | $0.10 per millione |
Esiste anche una istanza D0, che è quella utilizzata nell’esempio e che consente di avere:
Il costo è 0,36 dollari al giorno nel caso di pacchetto oppure 0,024 dollari per ora nel caso di tariffazione a consumo.
La terza, e ultima, parte dell'articolo sarà pubblicata il prossimo lunedì.
BigQuery
BigQuery è la risposta OLAP che il Cloud necessita in un periodo fertile di iniziative e applicazioni volte all’analisi di grosse quantità di dati. Benchè Cloud SQL sia infatti la risposta di Google alla necessità di RDBMS per le nostre applicazioni (in logica OLTP, Online Transactional Processing), BigQuery cerca di risolvere il problema dell’analisi dei dati ove sussistano miliardi di record e siano necessari risultati in pochi secondi. BigQuery è quindi un OLAP (Online Analytical Processing) che supporta un piccolissimo subset di SQL solo allo scopo di filtrare e raggruppare dati: non è infatti un RDBMS e non è ottimizzata la scrittura, che avviene infatti tramite upload di file CSV.
Utilizzo di BigQuery
Un buon punto di partenza per fare dei test con BigQuery è avere un CSV con dei dati campione: possiamo fare upload di CSV fino ad 1GB alla volta, ma il consiglio è quello di iniziare con un file più piccolo. Caricato il file sul Cloud Storage si può creare, sia programmaticamente che manualmente, un “load job”: trattandosi di API REST, il caricamento manuale può avvenire tramite un tool di Google. La procedura di caricamento presuppone una completa conoscenza dell’API REST di BigQuery, motivo per cui non la riportiamo in questo articolo e la rimandiamo ad un approfondimento successivo.
Una volta caricati dei dati campione (in ogni caso BigQuery ne fornisce già in alcuni dataset precaricati) possiamo recarci nel pannello dedicato e creare delle query sul datastore.
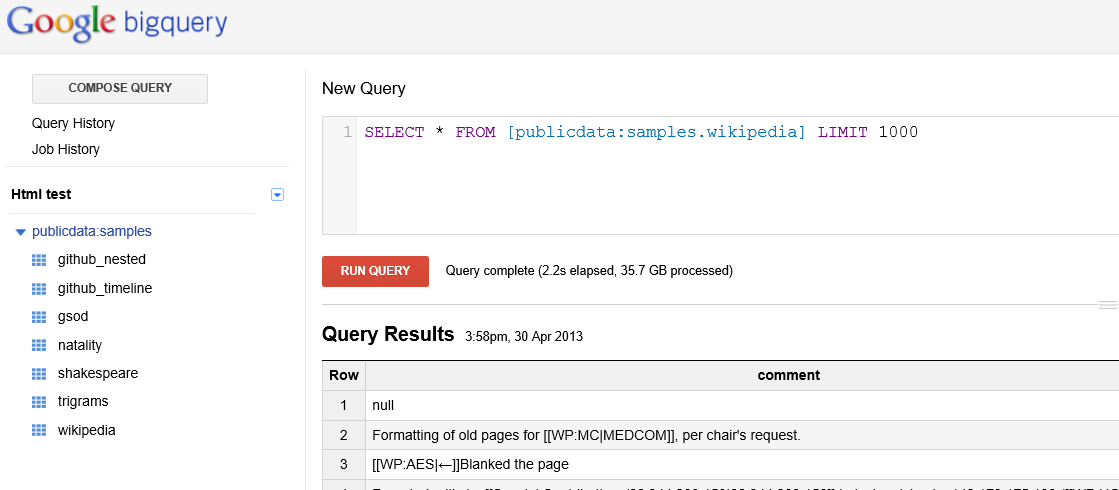
In questa finestra vediamo una serie di dataset con la possibilità di scrivere delle query custom in alto. Nell'esempio in figura sopra, vediamo che la query oggetto è stata eseguita in 2,2 secondi su un totale di 36GB di dati. Il beneficio più grande di questo strumento è ovviamente la proiezioni di raggruppamenti e selezioni specifiche un grande numero di record. Anche i dati risultati di BigQuery possono essere a loro volta salvati come tabella, per un eventuale utilizzo successivo come sorgente dati, oppure scaricati in CSV.
Costi di servizio
BigQuery ha un pricing model molto semplice, viene fatturato lo spazio occupato e i dati processati nelle query, secondo questa tabella:
Tabella 11 - Modello di billing per BigQuery
| Risorsa | Prezzo | Limiti predefiniti |
| Storage | $0.12 (per GB/mese) | 2TB |
| Interactive Queries | $0.035 (per GB processati) |
20,000 Total Queries Per Day (QPD) di qualsiasi tipo 20TB di dati processati al giorno |
| Batch Queries | $0.02 (per GB processati) |
Nell’esempio precedente quindi, supponendo che il dataset da 35,7GB circa l’avessimo caricato noi già un mese fa e che avessimo fatto una query al giorno come quella in esempio, avremmo speso:
C’è tuttavia da considerare che i primi 100 GB processati al mese sono gratuiti.
Google App Engine
Google App Engine (o GAE) è il prodotto PaaS principe di Google e, per molti versi, uno dei prodotti più interessanti del panorama Cloud odierno, anche se purtroppo soffre di alcune forti limitazioni sul codice eseguibile. App Engine permette l’hosting di applicazioni Java, Python, Go e, da alcune settimane, anche PHP, più una serie di servizi aggiuntivi/collaterali a supporto delle applicazioni distribuite.
Una trattazione completa di App Engine esula dallo scopo di questo articolo, poiché sicuramente molto complessa e articolata. La caratteristica più imponente di App Engine è la scalabilità automatica della nostra soluzione: con un modello di pricing basato sull’effettivo utilizzo di risorse e non sull’allocazione preventiva, GAE si posiziona in una stretta nicchia di prodotti che scalano automaticamente fornendo capacità computazionale on-demand, al crescere del carico.
GAE permette quindi l’hosting di soluzioni web con:
L’ambiente di sviluppo delle applicazioni per GAE plugin ufficiale
API e servizi
Tra i servizi di App Engine abbiamo uno store NoSQL (App Engine Datastore) che permette il salvataggio di dati con schema lasco sopra il quale è possibile fare query e attivare transazioni. Il datastore cresce insieme all’applicazione, nel senso che al crescere del carico, cambierà anche la topologia del servizio al fine di aumentare il throughput disponibile. Il datastore va visto come uno storage le cui entità non siano per forza dello stesso rigido schema, sul modello dell’Azure Table Storage e concordemente all’approccio NoSQL.
Tuttavia un eventuale controllo di schema può essere fatto tramite l’applicazione che, nel caso di Java, può accedervi tramite la JPA (Java Persistence API), uno standard di accesso ai dati, implementato inoltre da molti ORM del calibro di Hibernate, ma non solo.
GAE si avvale inoltre dell’ecosistema di Google fornendo alle sue applicazioni:
Google App Engine: quote e costi di servizio
Google App Engine è descritto da molti come un'infrastruttura a bassissimo costo di esercizio. Questo perché adotta un modello di pricing basato sull’effettivo consumo di risorse e non sull’allocazione preventiva di un pool (seppur basso) di risorse iniziali.
Supponendo infatti che una data richiesta Web consumi mezzo secondo CPU, Google tarifferà un’ora di calcolo al raggiungimento di 7200 richieste web identiche, sia che esse siano state fatte in pochi secondi che in diverse ore o giorni. Inoltre, le applicazioni distribuite su GAE sono inizialmente gratuite e il billing va abilitato (eventualmente) successivamente: questo perché nella maggioranza dei casi non sono necessarie applicazioni a pagamento visto che le quote gratuite di servizio sono relativamente generose.
Il contro di questo modello è un sistema di pricing particolarmente complesso, oltre le quote gratuite e una limitazione delle funzioni disponibili da codice. Sebbene lo scaling automatico e questo meccanismo di billing siano forse uno degli unici casi sul mercato, per abilitare questo modello è necessario imporre degli importanti vincoli su come siano scritte le applicazioni che vi girano sopra.
Uno degli esempi più eclatanti che sa sempre ha generato discussione su GAE è l’impossibilità di generare nuovi Thread, cosa inizialmente non possibile ed oggi possibile solo tramite una API apposita di generazione di Thread in background. Un altro caso è quello delle richieste che devono eseguire sempre in un tempo minore o uguale a 60 secondi, pena l’interruzione della richiesta e la generazione (in ambiente Java) di una eccezione di tipo DeadlineExceededException; non è inoltre possibile accedere a FileSystem, cosa tra l’altro pressoché ovvia in qualsiasi PaaS in commercio.
Sebbene alcune di queste limitazioni da un lato generino lock-in, ovvero tendano a fare scrivere agli sviluppatori soluzioni custom che quindi non funzionerebbero più una volta estrapolate dal contesto, dall'altro permettono all'infrastruttura di essere un esempio massimo di flessibilità.
Premesso quanto sopra possiamo definire quindi una applicazione come:
Un'applicazione gratuita ha a disposizione una quota giornaliera gratuita di ogni risorsa disponibile su GAE
La voce principale di consumo è certamente l’ora di calcolo
Tabella 12 - Blobstorage
| Resource | Free Default Limit | Billing Enabled Default Limit |
| Blobstore Stored Data | 5 GB | 5 GB free; no maximum |
Tabella 13 - Channel API
| Resource | Free Default Limit | Billing Enabled Default Limit | ||
| Daily Limit | Maximum Rate | Daily Limit | Maximum Rate | |
| Channel API Calls | 657,000 calls | 3,000 calls/minute | 91,995,495 calls | 32,000 calls/minute |
| Channels Created | 100 channels | 6 creations/minute | Based on your budget | 60 creations/minute |
| Channels Hours Requested | 200 hours | 12 hours requested/minute | Based on your budget | 120 hours requested/minute |
| Channel Data Sent | Up to the Outgoing Bandwidth quota | 22 MB/minute | 2 GB | 740 MB/minute |
Tabella 14 - Storage dove risiede il codice e le versioni dell'applicazione
| Resource | Cost |
| Code & Static Data Storage - First 1 GB | Free |
| Code & Static Data Storage - Exceeding 1 GB | $0.13 per GB per month |
Tabella 15 - Logs API
| Resource | Free Default Limit | Billing Enabled Default Limit |
| Logs data retrieval | 100 megabytes | No maximum for paid app. |
| Logs data | 1 gigabyte | Log data kept for a maximum of 365 days if paid, 90 days if free. |
Tabella 16 - Utilizzo Mail tramite gateway interno
| Resource | Free Default Limit | Billing Enabled Default Limit | ||
| Daily Limit | Maximum Rate | Daily Limit | Maximum Rate | |
| Mail API Calls | 100 calls | 32 calls/minute | 1,700,000 calls | 4,900 calls/minute |
| Messages Sent (billable) | 100 messages | 8 messages/minute | 100 messages daily until first charge cleared; 20,000 messages per day thereafter1 | 5,100 messages/minute |
| Admins Emailed | 5,000 mails | 24 mails/minute | 3,000,000 mails | 9,700 mails/minute |
| Message Body Data Sent | 60 MB | 340 KB/minute | 29 GB | 84 MB/minute |
| Attachments Sent | 2,000 attachments | 8 attachments/minute | 2,900,000 attachments | 8,100 attachments/minute |
| Attachment Data Sent | 100 MB | 10 MB/minute | 100 GB | 300 MB/minute |
Tabella 17 - Banda utilizzata
| Resource | Free Default Limit | Billing Enabled Default Limit | ||
| Daily Limit | Maximum Rate | Daily Limit | Maximum Rate | |
| Outgoing Bandwidth (billable, includes HTTPS) | 1 GB | 56 MB/minute | 1 GB free; 14,400 GB maximum | 10 GB/minute |
| Incoming Bandwidth (includes HTTPS) | 1 GB; 14,400 GB maximum | 56 MB/minute | None | None |
Tabella 18 - URL Fetch, ovvero chiamate HTTP verso internet
| Resource | Free Default Limit | Billing Enabled Default Limit | ||
| Daily Limit | Maximum Rate | Daily Limit | Maximum Rate | |
| UrlFetch API Calls | 657,000 calls | 3,000 calls/minute | 46,000,000 calls | 32,000 calls/minute |
| UrlFetch Data Sent | up to the Outgoing Bandwidth quota | 22 MB/minute | up to the Outgoing Bandwidth quota | 740 MB/minute |
| UrlFetch Data Received | up to the Incoming Bandwidth quota | 22 MB/minute | up to the Incoming Bandwidth quota | 740 MB/minute |
Capito come GAE allochi risorse alle applicazioni gratuite e a pagamento, un elenco dei prezzi sopra-soglia è disponibile alla pagina https://cloud.google.com/pricing/.
