Qualche articolo fa ci siamo occupati del meccanismo delle Java Annotations e abbiamo visto come sia semplice utilizzarle, creandone di nuove, con la possibilità di recuperarne a runtime i valori. Abbiamo imparato che la potenza di questo meccanismo risiede nella capacità di dare più espressività al codice che scriviamo. In molti casi tutto questo si traduce nell'utilizzare le annotazioni per creare, già in fase di scrittura del codice, dei meccanismi di configurazione.
Gli Enterprise Java Bean, dal rilascio della java virtual machine 5, e quindi di JEE 5, si sono radicalmente trasformati, entrando pienamente nell'ottica delle Java Annotations.
Uno dei grossi limiti nell'utilizzare la logica di business della piattaforma enterprise di Java è sicuramente il numero molto elevato di nozioni da apprendere e, soprattutto, il numero elevato di requisiti a cui ogni EJB doveva aderire. Leggendo la guida J2EE avrete avuto modo di vedere che ogni EJB costruito deve creare una serie di interfacce, dei descrittori ed una classe contenente la logica applicativa vera e propria.
La presenza di tool di sviluppo, negli anni, ha diminuito questo problema, permettendo la creazione dei componenti in maniera anche visuale, con maschere di dialogo. Ma il problema della intrinseca complessità della tecnologia è sempre rimasto come alone della piattaforma JEE.
Il passaggio da EJB 2 ad EJB 3
La grossa differenza nel passaggio da una versione ad un'altra è stata l'eliminazione delle classi utilizzate come Factory per istanziare concretamente il bean. Ciò significa che nella versione 3 non dovremo più creare una classe Home per ogni bean creato, né dovremo preoccuparci di estendere altre classi o interfacce.
La ragione per cui queste classi esistevano risiede nell'architettura degli EJB versione 2. L'architettura era stata appositamente pensata per permettere l'esecuzione di middleware e della logica applicativa su una macchina remota. Infatti, ogni metodo doveva obbligatoriamente lanciare l'eccezione java.rmi.RemoteException, in quanto l'architettura del componente era tale da rendere necessario questo accorgimento su tutti i componenti eseguibili in remoto.
Gli EJB 3.0 hanno modificato radicalmente l'architettura, lasciando molta più libertà alla costruzione dell'application server che ospiterà i componenti. Sarà infatti il container e la maniera in cui esso è implementato a gestire il ciclo di vita del componente. Non importa come questo avvenga: importante è rispettare la specifica e garantire il corretto ciclo di vita dei componenti. Fondamentalmente nella versione 3 sarà sufficiente scrivere una classe POJO (Plain Old Java Object) che implementa l'interfaccia di business.
Questa cosa potrebbe non essere positiva, in quanto in questo modo perderemmo la possibilità di intervenire in particolari momenti del ciclo di vita dell'oggetto (ad esempio durante le operazioni di passivazione ed attivazione). Ciò viene risolto dalla possibilità di creare delle apposite classi callback oppure di scrivere i metodi per gestire gli eventi ed annotarli con le annotazioni.
Ad esempio potremo creare un metodo da eseguire prima dell'evento di rimozione annotandolo con l'annotazione @Remove e così via con tutte gli eventi del ciclo di vita del componente. Il numero di annotation disponibili all'interno dello sviluppo del componente sono innumerevoli, tante quanti i possibili eventi e stati in cui un bean possa trovarsi. È evidente che questo stato di cose permette un lavoro di codifica molto più fluido, guidato dall'uso delle giuste annotazioni, ed in particolare, solo di quelle che realmente interessano la nostra applicazione.
Utilizzeremo quindi le annotazioni per marcare i metodi, gli attributi e, soprattutto, le stesse classi. Sarà attraverso l'uso delle annotazioni @Stateful, @Stateless e @MessageDriven che il compilatore prima, e il tool di deploy dopo, potranno procedere ad installare i bean all'interno del container.
Un aiuto verrà inoltre dalla gestione semplificata dell'ambiente di esecuzione. Prima, bisognava affidarsi alla classe java.naming.Context per recuperare i servizi presenti all'interno dell'application server: fare chiamate JNDI ed utilizzare poi lo specifico servizio. Ora tutto è estremamente semplificato dalla presenza di opportune annotazioni. Con una semplice annotazione recupereremo un Datasource, con un'altra recupereremo un EJB, l'accesso al servizio di invio mail e via dicendo.
Il descrittore di deploy
A questo punto risulta piuttosto evidente che il descrittore di deploy è inutile. Attraverso le annotazioni, infatti, riusciamo a definire in maniera precisa il componente e le sue diverse funzionalità, il ciclo di vita (anche le transazioni o altre funzioni di middleware da implementare). Di tutti i componenti, probabilmente questo è stato quello meno amato per un semplice motivo: è XML. Difficile da scrivere, da leggere e da capire, attraverso le annotazioni, fortunatamente questo componente viene meno. Inoltre, la sua redazione avviene in una seconda fase rispetto allo sviluppo del componente, quindi, l'insidia può essere rappresentata dalle dimenticanze. La possibilità di definire già all'interno della classe il suo comportamento del componente (transazioni, sicurezza, riferimenti ad altri ejb, ecc) facilita (e non poco) il lavoro.
In realtà il componente rimane perché è possibile ancora utilizzarlo per tutte le sue funzionalità (cioè definire il middleware in maniera esplicita). Si tratta solo di decidere se utilizzarlo o meno. Nel caso di utilizzo, le informazioni contenute nelle annotazioni vengono sorvolate, quindi, comunque, il descrittore di deploy ha precedenza sulle annotazioni.
La presenza del descrittore di deploy è, a mio avviso, una cosa ancora estremamente importante e da non sottovalutare, perché permette di configurare il componente dall'esterno del codice. Ciò vuol dire modificare esclusivamente un file di configurazione e non entrare nel codice per metterci mano (test da rifare, possibili insidie dovute alle nuove modifiche).
Utilizzare le annotazioni porta sicuramente ai grossi benefici citati ma, un eccessivo uso potrebbe essere deleterio ai fini di un corretto sviluppo e soprattutto di una corretta manutenzione. Di sicuro facilita la vita in fase di sviluppo, ma potrebbe complicarla in fase di manutenzione del componente, quindi, estrema cautela e scelte ben ponderate (soprattutto se l'applicazione è vasta ed implica la presenza di diverse figure professionali).
Costruire una web application in un lampo
Si tratta di una semplice applicazione web based il cui compito é quello di presentare all'utente una lista di prodotti, il cui prezzo può variare nel tempo, e che permette, allo stesso tempo, di registrare le ultime ricerche effettuate dal singolo utente. I casi d'uso sono quindi la ricerca di un oggetto e visualizzazione dell'elenco, la visualizzazione del prezzo di un oggetto e la visualizzazione delle ultime ricerche effettuate.
Partiamo subito dalla parte più interessante, la logica applicativa. Il diagramma delle classi ci aiuterà a comprendere come abbiamo disegnato l'applicativo.
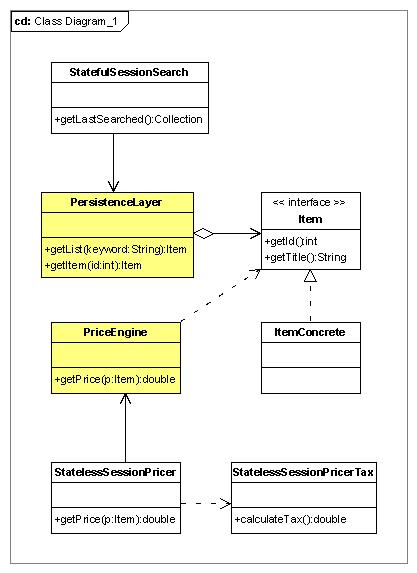
Notiamo subito l'interfaccia Item, che virtualizza un prodotto e relativa realizzazione concreta, ItemConcrete. Per semplicità abbiamo simulato la presenza di un layer di persistenza che, nel nostro caso, si occuperà di istanziare una serie di prodotti concreti e mantenerli in una struttura dati, rispondendo alle ricerche. Anche la classe PriceEngine, virtualizza la presenza di un motore di prezzi (che dovrebbe agire dinamicamente in base alle condizioni del prodotto, dell'utente, del periodo, ecc).
Il primo bean che vediamo é il bean StatefulSessionSearch, che fa da wrapper per le ricerche dell'utente. I due bean in basso, invece, collaborano per realizzare il servizio di calcolo del prezzo. Il bean StatelessSessionPricer (quello che espone la logica) si poggia a PriceEngine per recuperare il prezzo base dell'oggetto Item passato come riferimento, utilizzando l'altro bean StatelessSessionPricerTax, per recuperare dinamicamente la percentuale di tassa da applicare.
Questa logica esposta verrà utilizzata da una servlet di controllo, che gestirà il flusso delle operazioni di ricerca e visualizzazione del prezzo (i nostri casi d'uso): riprenderemo il discorso dopo aver mostrato come sviluppare gli EJB 3.0.
Usare le Annotations per definire i bean
Non entriamo nel dettaglio delle classi che simulano lo strato di persistenza (PersistenceLayer) ed il motore dei prezzi (PriceEngine). Quindi vediamo immediatamente come creare un EJB nella sua versione 3.0. Iniziamo con la creazione del primo stateless session bean, partiamo dall'interfaccia:
Listato 1. Interfaccia stateless session bean
package it.html.ejb3.pricer;
import it.html.ejb3.persistence.Item;
import javax.ejb.Local;
@Local
public interface StatelessSessionPricerTaxLocal {
double calculateTax();
}
Abbiamo creato una semplice interfaccia Java, annotandola con l'annotazione @Local. Ciò vuol dire che abbiamo intenzione di utilizzare questa classe all'interno dello stesso container. Qualora avessimo voluto esporre il servizio come interfaccia remota, avremmo dovuto annotarla con l'annotazione @Remote. Lo stesso se vogliamo predisporre entrambe le interfacce.
Passiamo all'implementazione concreta:
Listato 2. Implementazione completa interfaccia
package it.html.ejb3.pricer;
import it.html.ejb3.persistence.Item;
import javax.annotation.PostConstruct;
import javax.annotation.Resource;
import javax.ejb.Stateless;
//Stateless Session Bean utilizzato per definire la politica sui prezzi
//da applicare. La creazione avviene mediante l'uso delle opportune annotazioni.
@Stateless
public class StatelessSessionPricerTaxBean implements StatelessSessionPricerTaxLocal {
//Recuperiamo il valore della variabile (algorithmToUse) dal descrittore di deploy
//a tempo di deploy. Serve per definire quale algoritmo utilizzare.
@Resource(name="algorithmToUse")
public String algorithm;
//Il metodo ha una logica molto semplice, in base all'algoritmo indicato
//restituiamo un valore numerico, indicante una percentuale
public double calculateTax() {
if (algorithm!=null && algorithm.equals("easy"))
return 0.15;
if (algorithm!=null && algorithm.equals("hard"))
return 0.25;
//default medium
return .20;
}
}
La classe (che implementa l'interfaccia locale, o remota, o entrambe) viene annotata con @Stateless, indicando chiaramente che questa classe é un bean di tipo Stateless. Il metodo esposto nell'interfaccia viene implementato (in questo caso la logica é molto semplice). Utilizzare delle risorse all'interno del bean diventa facile con le annotations. In pratica, lo strumento ci consente di marcare delle risorse che a tempo di deploy verranno configurate opportunamente. Notate nel nostro caso l'attributo algorithm, che viene marcato dall'annotazione @Resource(name=...): stiamo dicendo al container che quella variabile dovrà essere valorizzata con il parametro "algorithmToUse" contenuto nel descrittore di deploy. In questo modo potremo modificare il comportamento del componente modificando solo il file XML, senza accedere in alcun modo al codice.
Proseguiamo con la nostra applicazione, e vediamo il secondo stateless session bean, partendo sempre dall'interfaccia che definisce il servizio:
Listato 3. Business interface per StatelessSessionPricer enterprise bean
package it.html.ejb3.pricer;
import it.html.ejb3.persistence.Item;
import javax.ejb.Local;
@Local
public interface StatelessSessionPricerLocal {
double getPrice(Item prod) throws it.html.ejb3.persistence.ItemNotFoundException;
}
Il servizio che deve garantire questo bean é quello di calcolare il prezzo del prodotto, poggiandosi al PriceEngine ed al bean che calcola la percentuale di tasse da pagare. Come prima, una semplice interfaccia annotata come @Local. Vediamo l'implementazione:
Listato 4. Il bean (stateless) calcola il prezzo finale di un oggetto passato come riferimento
package it.html.ejb3.pricer;
import it.html.ejb3.persistence.Item;
import it.html.ejb3.persistence.ItemNotFoundException;
import javax.annotation.PostConstruct;
import javax.ejb.EJB;
import javax.ejb.Stateless;
@Stateless
public class StatelessSessionPricerBean implements StatelessSessionPricerLocal {
//Recuperiamo l'EJB utilizzato per il calcolo delle tasse
@EJB
private StatelessSessionPricerTaxLocal taxEngine;
//La classe che simula il price engine
private PriceEngine engine;
//Il metodo verrà chiamato subito dopo il costruttore, valorizzando le variabili di istanza presenti
@PostConstruct
private void postConstruct(){
engine=new PriceEngine();
}
//Il metodo di logica, per recuperare il prezzo dell'oggetto passato come riferimento
public double getPrice(Item prod) throws ItemNotFoundException {
//Inoltriamo la richiesta al layer, aggiungendo il valore della tassa al momento della richiesta
return engine.getPrice(prod)*(1+(taxEngine.calculateTax()));
}
}
La classe concreta viene annotata come @Stateless implementando l'interfaccia locale. Per poter implementare il metodo di logica abbiamo bisogno del PriceEngine e del bean visto in precedenza. Vediamo le annotazioni in azione: attraverso l'annotazione @EJB diamo un riferimento del bean che vogliamo usare. Nessun uso di Context (come avveniva in EJB 2.0) o altri strumenti. Semplicemente la definizione dell'interfaccia da utilizzare, annotata con l'opportuna annotation.
Potrete chiedere tutti i servizi dell'application server in maniera immediata, Datasource, code, servizi di messaggistica e tutto quanto vi può essere utile, direttamente dal codice, senza dover configurare file XML o altri sistemi di configurazione. Immediato e semplice, no? Inoltre anche la lettura del codice ne beneficia, che come vediamo si commenta anche grazie l'uso delle annotazioni.
La creazione della classe PriceEngine viene delegata nel metodo postConstruct(). Banalmente inizializziamo la classe. La cosa interessante é notare l'annotazione usata per il metodo @PostConstruct. Attraverso quest'annotazione stiamo dicendo al container, che, seguendo il ciclo di vita del componente, subito dopo il costruttore, dovrà essere richiamato il metodo postConstruct().
Attraverso l'annotazione dei metodi possiamo dunque gestire direttamente dal codice l'intero ciclo di vita del bean: @PreActivate, @PostActivate, @PostConstruct... esistono decine di annotazioni, usando le quali riuscirete a seguire il ciclo di vita del componente. In pratica, le annotazioni, in questo caso, sostituiscono la classe callBack handler, gestendo direttamente il comportamento del bean. Ovviamente, tali metodi possono non essere implementati.
La logica del metodo, a questo punto, é un'operazione tra l'engine appena recuperata e l'altro EJB a cui il bean fa riferimento.
Stateful Session Bean
L'idea é identica, cambiano ovviamente alcune annotazioni.
Listato 5. Business interface per StatefulSessionSearch enterprise bean
package it.html.ejb3.search;
import java.util.Collection;
import javax.ejb.Local;
@Local
public interface StatefulSessionSearchLocal {
Collection searchAll();
Collection getLastSearched();
Collection search(String title);
}
Definizione del comportamento del componente, sempre come interfaccia locale (per mantenere alte le performance).
Listato 6. Il bean (stateful) si occupa di mantenere una struttura dati contenente le ultime
package it.html.ejb3.search;
import it.html.ejb3.persistence.PersistenceLayer;
import java.util.Collection;
import java.util.Queue;
import java.util.Stack;
import javax.annotation.PostConstruct;
import javax.ejb.Stateful;
@Stateful
public class StatefulSessionSearchBean implements StatefulSessionSearchLocal {
//Utilizziamo una struttura dati a pila, riprendendo l'implementazione java.util
Stack<String> stack;
//Il layer di persistenza
PersistenceLayer pl;
@PostConstruct
private void postConstruct(){
stack=new Stack<String>();
pl=PersistenceLayer.getInstance();
}
//Restituisce tutti gli oggetti
public Collection searchAll() {
return pl.getList();
}
//Restituisce gli elementi, che compiono match con la stringa passata in riferimento
public Collection search(String title) {
//Aggiungiamo la stringa richiesta
stack.add(title);
//Inoltriamo la richiesta
return pl.getList(title);
}
//Recuperiamo le ultime ricerche effettuate
public Collection getLastSearched(){
return stack;
}
}
I commenti contenuti nel codice spiegano abbastanza bene il comportamento della logica di business. Notiamo che la classe viene annotata come @Stateful, in quanto questo componente é un componente che mantiene la sessione dell'utente (ricordiamo che deve registrare le ultime ricerche effettuate da ogni utente).
Per completezza andiamo a vedere il client di questa logica applicativa. Una servlet che funge da controller che ha il compito di definire il flusso di operazioni dei nostri due casi d'uso (ricerca e visualizzazione prezzo). Come al solito racchiudiamo ognuno di questi casi d'uso in un metodo della servlet:
Listato 7. La servlet funge da flusso di controllo
@EJB(name="SessionSearchRef", beanInterface=StatefulSessionSearchLocal.class)
public class Controller extends HttpServlet {
//Utilizziamo le annotazioni per utilizzare gli EJB
@EJB
private StatelessSessionPricerLocal pricer;
//Il layer viene utilizzato per recuperare informazioni (simulate) di persistenza sull'oggetto
private PersistenceLayer pl;
//Manteniamo un riferimento al Context, potrebbe esserci utile
private Context ctx;
//Inizializzazione componente
public void init(){
try {
ctx=new InitialContext();
} catch (NamingException ex) {
ex.printStackTrace();
}
pl=PersistenceLayer.getInstance();
}
protected void service(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//dispatch the request
String op=request.getParameter("op");
if (op!=null && op.equals("search")){
doSearch(request,response);
}else if (op!=null && op.equals("getPrice")){
doGetPrice(request,response);
}else{
printMessage(response,"Operazione non disponibile.");
}
}
//Flusso operazioni di ricerca
private void doSearch(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
StatefulSessionSearchLocal ssfSearch;
Collection toRet=null;
//Valorizziamo il bean con quello relativo alla sessione dell'utente che ne fa richiesta
ssfSearch=(StatefulSessionSearchLocal) request.getSession(true).getAttribute("sessionSearch");
if (ssfSearch==null){
try {
//se non é stato creato, lo creiamo
ssfSearch=(StatefulSessionSearchLocal) ctx.lookup("java:comp/env/SessionSearchRef");
} catch (NamingException ex) {
printMessage(response,"Errore durante l'operazione di ricerca!");
return;
}
request.getSession(true).setAttribute("sessionSearch",ssfSearch);
}
//Recupero la keyword
String keyword=request.getParameter("keyword");
//ed effettuo la ricerca
if(keyword==null)
toRet=ssfSearch.searchAll();
else
toRet=ssfSearch.search(keyword);
System.out.println("DEBUG: "+toRet);
//Salviamo l'oggetto nella request, in modo da renderlo visibile
RequestDispatcher rd=this.getServletContext().getRequestDispatcher("/index.jsp");
request.setAttribute("list",toRet);
//alla pagina JSP che verrà inoltrata
rd.forward(request,response);
}
//Flusso operazioni prezzo prodotto
private void doGetPrice(HttpServletRequest request, HttpServletResponse response) throws IOException {
//Cerco l'oggetto
String pid=request.getParameter("pid");
Item i;
try {
i = pl.getItem(Integer.parseInt(pid));
//il prezzo corrente
double price=pricer.getPrice(i);
//e stampo l'informazione
printMessage(response,"Il prezzo del prodotto <b>"+i.getTitle()+"</b> ... "+price+" Eu");
} catch (NumberFormatException ex) {
ex.printStackTrace();
} catch (ItemNotFoundException ex) {
printMessage(response,"Oggetto non trovato!");
}
}
}
In testa alla servlet definiamo il riferimento che utilizzeremo e l'interfaccia del bean. La servlet, infatti, dovrà poggiarsi al bean stateful per effettuare le ricerche ed al bean stateless per recuperare i prezzi. Il bean stateless viene recuperato mediante l'annotazione @EJB, lo stateful in maniera classica, in quanto dobbiamo preoccuparci di crearne uno per ogni diverso utente (e poi salvarlo in sessione).
Tutto ciò può essere evidenziato nel metodo doSearch() dove, in testa ad esso, viene recuperato il bean (dalla sessione utente, o creato, se non esiste), prima di eseguire la logica. Il metodo doGetPrice() fa uso del bean stateless (che può essere uno qualunque del pool dei bean di quel tipo, essendo stateless).
Ultimo passo, prima di concludere é di mostrare la pagina JSP, nello scriptlet che effettua la lettura delle ricerche (dal bean memorizzato in sessione) e la visualizzazione dei risultati:
Listato 8. Servlet che effettua la lettura delle ricerche
<%
it.html.ejb3.search.StatefulSessionSearchLocal ssfSearch=(it.html.ejb3.search.StatefulSessionSearchLocal)session.getAttribute("sessionSearch");
if (ssfSearch!=null){
//mostra ultime ricerche
%>
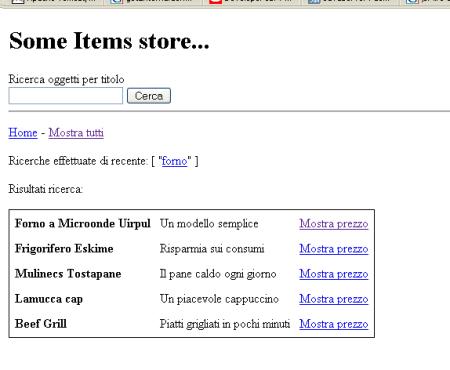
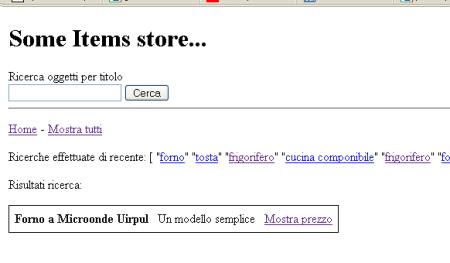
<p>Ricerche effettuate di recente: [
<%
java.util.Collection<String> searches = ssfSearch.getLastSearched();
for (String i:searches){
out.println(" "<a href="controller?op=search&keyword="+i+"">"+i+"</a>" ");
}
%> ]
</p>
<%
}
%>
<%
java.util.Collection<it.html.ejb3.persistence.Item> list=(java.util.Collection)request.getAttribute("list");
if (list!=null){
//mostra contenuto ricerca
%>
<p>Risultati ricerca:
<table style="border:solid 1px #000000;">
<%
for (it.html.ejb3.persistence.Item i : list){
%>
<tr>
<td style="padding:5px 5px 5px 5px;">
<strong><%=i.getTitle()%></strong>
</td>
<td style="padding:5px 5px 5px 5px;">
<%=i.getDescrption()%>
</td>
<td style="padding:5px 5px 5px 5px;">
<a href="controller?op=getPrice&pid=<%=i.getId()%>">Mostra prezzo</a>
</td>
</tr>
<%
}
%>
</table>
</p>
<%
}
%>
Vista la natura introduttiva dell'articolo non abbiamo potuto vedere le centinaia di annotazioni che completano la tecnologia EJB 3.0, per cui vi invito ad approfondire il discorso, se interessati allo sviluppo, con guide su EJB 3.0 e relative annotazioni. Di seguito il risultato di una generica esecuzione.