Una delle esigenze che uno sviluppatore software dovrebbe maggiormente sentire, quando si parla di interazione tra utente e macchina, è quella di rendere l'esperienza del primo, il meno complessa possibile. La complessità non risiede solo nell'organizzare le informazioni in maniera adeguata, ma anche il tempo con cui queste informazioni vengono raccolte e visualizzate.
Lo sviluppo di applicazioni web based è affiancato tipicamente da una base di dati dalla quale caricare le informazioni che l'utente richiede. In questo articolo cercheremo di comprendere come realizzare uno strumento che riduca il numero di accessi alla base di dati, avendo come effetto principale quello di velocizzare la visualizzazione delle informazioni.
Un buono progettista di software sa che un DBMS è un sistema che gestisce in maniera semplice e standard le operazioni sui dati, e sa anche che ogni volta che ci si accede c'è un buona quantità di risorse di sistema che vengono impegnate per svolgere la funzione richiesta. In gergo si dice che il DBMS è un collo di bottiglia, cioè, il flusso di esecuzione viene rallentato (al momento della chiamata). Spesso in fase di scelta della configurazione si preferisce dedicare maggiori risorse (finanziarie, soprattutto) per acquistare DBMS più veloci e potenti, trascurando il dettaglio che dei semplici accorgimenti software possono incrementare la velocità a costo zero.
La cache, cioè uno strumento che mantiene in memoria volatile dati utilizzati frequentemente dall'applicazione. Diciamo subito che vedremo una semplice soluzione adattabile in maniera immediata a ogni contesto applicativo, mentre esistono strumenti e framework che ne gestiscono i dettagli avanzati in maniera completa.
Analisi e disegno del progetto
Lo scenario d'uso cui faremo riferimento è quello di una tipica applicazione web, dove è l'utente a effettuare delle ricerche (con un modulo di ricerca testuale) su una base di dati. Uno scenario piuttosto comune in applicativi web based.
Per semplicità supponiamo anche che l'utente possa decidere se forzare l'accesso sulla base di dati (in modo da valutare la differenza di tempo tra il primo e il secondo metodo).
Avremo un layer di persistenza gestito con una classe che avrà il metodo di accesso per la ricerca (ci atteniamo allo scenario definito). Il client di questa classe deve avere trasparenza rispetto alla cache, quindi, il client deve conoscere il comportamento astratto.
Possiamo già identificare la classe astratta Database e quella concreta DatabaseConcrete. Quest'ultima, però, deve occuparsi esclusivamente di gestire le operazioni di persistenza, senza altri compiti. Una terza classe, la cache, quindi, mantiene il riferimento a un DatabaseConcrete e mantiene in memoria le informazioni rilevanti in una struttura dati, inoltrando le richieste verso il DatabaseConcrete. La classe cache (o proxy) DatabaseProxy presenterà gli stessi metodi della classe Database, quindi può ereditare da essa agendo da intermediario tra il client e il DatabaseConcrete. Tutto trasparente al client, che comunicherà con il tipo astratto Database.
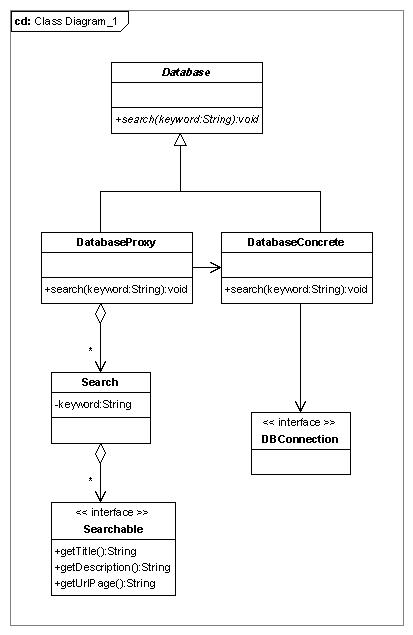
Il diagramma delle classi illustra chiaramente il principio che in letteratura dei pattern di progetto è noto come Proxy. L'idea del proxy è semplice e potente allo stesso tempo: permette di svolgere delle funzioni concrete appoggiandosi a un layer sottostante, gestendo una logica (anche complessa) al suo interno. Nel caso della cache l'operazione sarà:
- verifica che l'informazione richiesta sia nella struttura dati;
- se esiste, restituisci l'informazione;
- altrimenti richiama il layer sottostante;
- salva nella struttura dati;
- e restituisci l'informazione.
- se la chiave di ricerca è nella cache, restituiamo quel risultato;
- altrimenti, effettuiamo una ricerca sul database;
- salviamo i risultati in cache e li restituiamo al client.
- search
- timeLoading
L'uso dei proxy è largamente utilizzato nella progettazione software, proprio perché in maniera trasparente al client vengono create delle logiche particolarmente utili e intercambiabili (sostituire la classe non influenza il client).
Implementazione
Seguendo il requisito noi ci occuperemo della sola operazione di caricamento, ma è bene dire che è possibile utilizzare cache anche per le operazioni di salvataggio sulla base dati.
Prima di mostrare l'implementazione della cache, mostriamo l'interfaccia Searchable. L'introduzione di questa interfaccia fa sì che ogni oggetto, che può essere rappresentato sotto forma di ricerca, possa estendere questa interfaccia ed essere integrato nei risultati della ricerca.
Listato 1. L'interfaccia definisce il comportamento di un oggetto "ricercabile"
//Searchable.java
package it.html.cache.items;
public interface Searchable {
//Restituisce il titolo della risorsa
public String getTitle();
//Restituisce la descrizione dell'oggetto in esame
public String getDescription();
//Restituisce la URL a cui è linkata la pagina di dettaglio dell'oggetto
public String getUrlDetail();
}
Una ricerca (classe Search) è invece rappresentata da una keyword (una stringa) e una collezione di oggetti Searchable.
Listato 2. Funge da struttura dati. Lo scopo è di associare una singola ricerca a una collezione di oggetti che corrispondono a quella ricerca
public class Search {
//La chiave di ricerca
private String keyphrase;
//La struttura dati in cui sono contenuti gli oggetti corrispondenti
private Collection
//Costruttore
public Search(String keyprhase) {
this.keyphrase=keyprhase;
list=new ArrayList();
}
..//
Immaginiamo che la vostra applicazione abbia le classi Foto e Video, facendo implementare l'interfaccia Searchable, entrambi potranno fare parte dello stesso risultato di ricerca con una data keyword.
Come caso di esempio ereditiamo la classe Resource utilizzata nell'articolo dedicato alla tag cloud. A questa faremo ereditare l'interfaccia Searchable, implementandone ovviamente i metodi.
Vediamo allora come si presenta la cache. La classe madre della gerarchia presenta i metodi che un client può utilizzare:
Listato 3. virtualizza le funzioni che dovranno essere presenti sul layer di persistenza
//Database.java
package it.html.cache.proxy;
import it.html.cache.items.Resource;
import it.html.cache.items.Search;
import java.util.Collection;
public abstract class Database {
//Ricerca e restituisce gli oggetti che corrispondono alla keyword
public abstract Search search(String keyphrase);
//Ricerca e restituisce gli oggetti che corrispondono alla keyword, forzando il reload della cache
public abstract Search search(String keyphrase,boolean forceCache);
//Carica la risorsa identificata da ID
public abstract Resource load(int id);
}
Accanto ai metodi di ricerca abbiamo previsto il metodo load della singola risorsa, in modo da caricare un determinato dettaglio.
La classe DatabaseConcrete non deve fare nulla di diverso rispetto a quanto farebbe una classe che fa parte di un layer di persistenza, cioè interagire con il database, in questo caso per il caricamento dei dati. Quindi, dal punto di vista dello sviluppo nulla cambia rispetto all'articolo precedente (cloud tag) da cui abbiamo in eredità la struttura dati e il codice di questa classe.
Listato 4. Interagisce con il db
public Search search(String keyphrase) {
Search toRet=new Search(keyphrase);
try{
//Recupero una connessione
dbConnection.openConnection();
Connection connection=dbConnection.getConnection();
//Effettuo la query
String sql="SELECT * FROM resource where title like ? OR description like ?";
PreparedStatement pst=connection.prepareStatement(sql);
pst.setString(1,"%"+keyphrase+"%");
pst.setString(2,"%"+keyphrase+"%");
ResultSet rs=pst.executeQuery();
//Leggo e salvo i risultati
while (rs.next()){
//Se esiste, recuperiamo i parametri
int id=rs.getInt("id");
String title=rs.getString("title");
String description=rs.getString("description");
Searchable x=new Resource(id,title,description);
//Aggiungiamo la risorsa alla ricerca
toRet.add(x);
}
//Chiusura dei flussi aperti
rs.close();
pst.close();
dbConnection.closeConnection();
}catch(Exception e){
e.printStackTrace();
}
return toRet;
}
Come vediamo dal codice sorgente, viene effettuata una query di selezione. La parte di logica che ci interessa è quella contenuta nel proxy, che andiamo a vedere subito:
Listato 5. L'istanza del layer concreto di persistenza, usata per interrogare il database
public class DatabaseProxy extends Database{
private DatabaseConcrete db;
//La struttura dati della cache
private Map<String,Search> cache;
public DatabaseProxy(DatabaseConcrete db) {
this.db=db;
cache=new HashMap();
}
..//
Vediamo come la classe contenga un'istanza di DatabaseConcrete a cui si poggia per le operazioni di base (se necessarie). Inoltre abbiamo una struttura dati veloce, un Hashmap, che ha una complessità algoritmica costante. La struttura dati è tipizzata (secondo lo stile java 1.5) ed è composta da una stringa (la chiave di ricerca) e una Search (la collezione di risultati contenuta nella classe).
Il processo di ricerca è il seguente:
Listato 6. Processo di ricerca
public Search search(String keyphrase) {
// step 1
if (cache.containsKey(keyphrase)){
return (cache.get(keyphrase));
}else{
//step 2
Search s=db.search(keyphrase);
// step 3
cache.put(keyphrase,s);
return s;
}
}
Per risolvere il problema della dirty cache (cioè di quando i dati sono inconsistenti con il layer sottostante), in questo esempio, non abbiamo adottato nessuna strategia. L'unico modo per avere dati "freschi" è la richiesta dell'utente di caricamento forzando la cache. È in questo caso che avviene l'allineamento della cache:
Listato 7. Allineamento della cache
//Ricerco i risultati, forzando la cache
public Search search(String keyphrase, boolean forceCache) {
if (forceCache){
//Rimuovo l'oggetto dalla cache, in modo che faccia spazio al nuovo risultato
cache.remove(keyphrase);
Search s=db.search(keyphrase);
//Salvo l'oggetto in cache
cache.put(keyphrase,s);
return s;
}else{
return search(keyphrase);
}
}
Ultimo metodo, che per scelta non vogliamo aderisca a nessuna politica di caching è il metodo di load che si limita a inoltrare la richiesta al layer sottostante.
public Resource load(int id) {
return db.load(id);
}
Controller e interfaccia
Nel diagramma delle classi abbiamo omesso quello che è il client della cache, cioè il controller. Quest'ultimo si occuperà di gestire la creazione della struttura dati cache in maniera corretta utilizzando il metodo statico in una classe Factory.
Il caso d'uso concreto verrà realizzato dal metodo che segue:
Listato 8. Definisce il flusso di esecuzione della ricerca
private void doSearch(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
String keyword=request.getParameter("key");
String forceCache=request.getParameter("fc");
boolean fc=false;
//verifichiamo se l'utente ha deciso di forzare la cache
if (forceCache!=null) try{
fc=Boolean.parseBoolean(forceCache);
}catch(Exception e){
//il valore è già false, di default
}
long timeStart=System.currentTimeMillis();
//Effettuo la ricerca
Search toRet=db.search(keyword,fc);
long timeEnd=System.currentTimeMillis();
//Setto l'attributo di ritorno
request.setAttribute("search",toRet);
//Settiamo il tempo di caricamento
request.setAttribute("timeLoading",new Long(timeEnd-timeStart));
//effettuo l'operazione di forward
RequestDispatcher rd=this.getServletContext().getRequestDispatcher("/result.jsp");
rd.forward(request,response);
}
Per mostrare la reale funzionalità dell'esempio, utilizziamo anche un attributo che calcola il tempo di esecuzione reale. Nella view (result.jsp), quindi, ci aspettiamo due attributi:
Il caricamento è la visualizzazione del dettaglio ed è affidato al metodo doShowDetail (con l'ausilio della view detail.jsp).
L'interfaccia di ricerca, dovrà quindi avere un pannello di ricerca per l'inserimento dati e una lista che ne mostri i risultati (e il tempo di esecuzione).
Listato 9. Form di ricerca
<%@ page import="java.util.*,it.html.cache.items.*" %>
<html>
<head>
<title>Web Cache</title>
</head>
<body>
<p>
<form action="controller" method="post">
<input type="hidden" name="op" value="search" />
Cerca: <input type="text" name="key" /> <input type="submit" />
<input name="fc" type="checkbox" value="true" /> (forza la cache)
</form>
</p>
I parametri utilizzati dalla servlet saranno op (campo nascosto, utilizzato dal metodo dispatcher), key, il parametro di testo inserito dall'utente ed fc, il checkbox che forza la lettura del database (rinfrescando la cache).
L'operazione di visualizzazione dei risultati viene effettuata se l'attributo search della pagina è stato settato dalla servlet (con dentro una lista di risultati utili).
Listato 10. Aggiunge i risultati se la ricerca è stata effettuata
<%
Search search=(Search) request.getAttribute("search");
if(search!=null){
Long timeLoading=(Long) request.getAttribute("timeLoading");
%>
<hr>
<h2>Risultati ricerca: <%=search.getKeyphrase()%></h2>
<p>
<%
for (Searchable s : search.getCollection()){
%>
<div>
<a href="<%=s.getUrlDetail()%>">
<%=s.getTitle()%>
</a> -
<%=s.getDescription()%>
</div>
<%
}
%>
</p>
<p>Tempo di caricamento: <strong><%=timeLoading.longValue()%> millisecondi</strong></p>
<%
}
%>
</body>
</html>
Se l'attributo è presente mostriamo i risultati (con un ciclo stile java 1.5, grazie alla tipizzazione della Collection restituita) e il tempo di caricamento.
Il risultato di una ricerca è immediato visualizzarlo facendo diversi test con valori nella cache e non e misurandone le prestazioni (il tempo di caricamento).