
Per implementare il BOLT che abbiamo chiamato WordNormalizer, creiamo una classe nel package BOLTS e la chiamiamo WordNormalizer. Durante la creazione della classe, dobbiamo avere cura di ereditare la classe BaseRichBOLT. Per fare ciò, possiamo parametrizzare la maschera di creazione di una classe come nella figura sottostante:
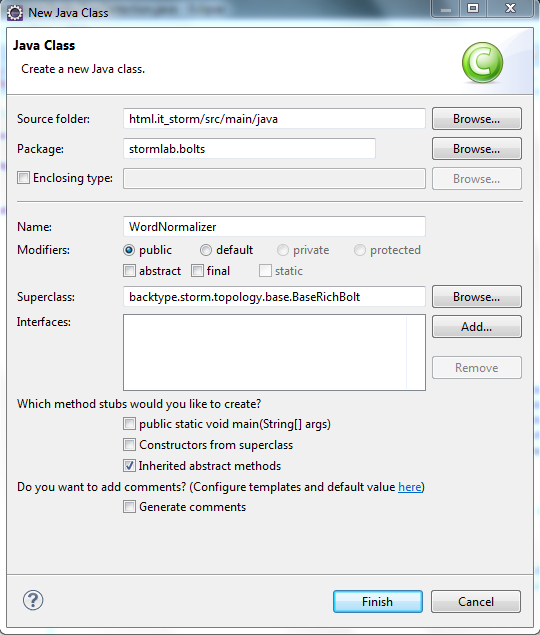
La classe che viene creata ha la struttura come quella proposta di seguito:
public class WordNormalizer extends BaseRichBOLT {
public void prepare(Map stormConf, TOPOLOGYContext context,
OutputCollector collector) {
}
public void execute(Tuple input) {
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}Analogalmente al metodo open() di uno SPOUT, il metodo prepare() viene utilizzato per inizializzare la configurazione del BOLT, infatti i parametri di ingresso sono gli stessi. Possiamo utilizzare il metodo prepare per configurare il collector. Sulla base di tutte queste informazioni quindi, possiamo implementare il metodo come segue:
public void prepare(Map stormConf, TOPOLOGYContext context, OutputCollector collector) {
this.collector = collector;
}Il metodo execute() permette di eseguire l'elaborazione per cui viene creato il BOLT. Dunque nel nostro caso, dovrà effettuare una normalizzazione delle parole lette nel file. Come anticipato, le stringhe vengono incapsulate in tuple; una tupla arriva ad un BOLT attraverso l'oggetto Tuple (in ingresso al metodo execute). Dunque per effettuare l'elaborazione sulla stringa, dobbiamo estrarre dalla tupla le stringhe lette nel file.
public void execute(Tuple input) {
String sentence = input.getStringByField("line");
String[] words = sentence.split(" ");
for(String word : words){
word = word.trim();
if(!word.isEmpty()){
word = word.toLowerCase();
collector.emit(new Values(word));
}
}
}Come è facile intuire, l'estrazione descritta avviene tramite il metodo getStringByField() dell'oggetto input, al quale passiamo come parametro l'etichetta assegnata nel metodo declare dello SPOUT.
Successicamente effettuiamo l'elaborazione definita. Dato che le stringhe devono essere elaborate ulteriormente, provvediamo ad emetterle al BOLT successivo della catena con il metodo emit(). Come fatto nello SPOUT, associamo un'etichetta alla tupla implementando il metodo seguente:
public void declareOutputFields(OutputFieldsDeclarer declarer) {
declarer.declare(new Fields("word"));
}Se vuoi aggiornamenti su Development inserisci la tua email nel box qui sotto:

