
Spesso, nella progettazione e sviluppo di soluzioni informatiche, occorre trovare una soluzione facile e rapida per la gestione della persistenza. In passato abbiamo già affrontato il tema della persistenza e di come poterla utilizzare a livello applicativo in Java.
In questo articolo abbiamo creato un framework che automatizzasse le operazioni CRUD e abbiamo osservato che soluzioni del genere possono applicarsi a piccole applicazione o essere oggetto di discussioni accademiche.
In un altro articolo ci siamo occupati di Hibernate, esaminando il funzionamento di uno dei primi e più importanti middleware per la gestione della persistenza.
Anche nella guida J2EE abbiamo affrontato il tema della persistenza in ambiente enteprise, conoscendo quindi gli EJB, e le metodologie BMP e CMP.
In questo articolo ci occuperemo di quest'ultima tecnologia e di come la nuova specifica EJB 3.0 abbia sostituito la persistenza basata su EJB, CMP e BMP con la specifica JPA, Java Persistence API. JPA di fatto eredita le esperienze positive e negative delle diverse proposte che negli anni hanno fatto a gara nella corsa a diventare la soluzione standard per la persistenza in Java. In particolare prende molto da due progetti: Hibernate e TopLink.
TopLink era un middleware sviluppato da Oracle per gestire la persistenza delle applicazioni Java su piattaforma DB Oracle. Unendo questi due middleware, e le best practice di pattern di progetto come DAO, nasce il layer di persistenza di EJB 3.0.
ORM - Object Relational Mapping
Nella progettazione orientata agli oggetti, la parte più importante è la definizione del domain model (modello di dominio). È in questa fase che si stabiliscono le relazioni tra gli oggetti e quindi le modalita di gestione a livello applicativo.
Portare un modello a oggetti in un database relazionale è una cosa molto complessa in quanto, pur potendo avere dei punti di contatto, si tratta di due paradigmi differenti, in particolare quando ci riferiamo alle relazioni.
Tralasciamo il dettaglio logico della trasformazione ORM, che abbiamo affrontato meglio nella guida J2EE di cui sopra. A livello applicativo è molto importante capire come la presenza di uno strumento che faciliti (automatizzandole) le operazioni di collegamento tra le entità che compognono il modello di dominio sia di notevole aiuto alla manutenzione della logica di persistenza. Una volta definite le relazioni, infatti, attraverso la codifica delle regole che collegano le entità tra di loro, sarà facile mantenere allineati lo schema della base di dati e il relativo modello di dominio.
Tutto questo comporta uno sforzo iniziale in modo da progettare tutti i dettagli con attenzione, ma la gestione del livello applicativo ne avrà grossi benefici. Attraverso la definizione delle entità che compongono l'applicazione e di come tra di loro sono relazionate, in automatico avremo una rappresentazione relazionale e relativa persistenza.
In particolare attraverso le annotazioni di Java vedremo come possa essere configurato il servizio senza ricorrere alla presenza di file di configurazione XML che possono rendere confusa la gestione del layer di persistenza.
Per esaminare più da vicino il funzionamento di JPA e il concetto di ORM, ci serviremo di una applicazione di esempio, che realizzi un conto corrente bancario. Per semplicità esamineremo una singola entità e come mapparla su un database reale.
Mappare un'entità
La cosa più importante rispetto alla precedente versione di EJB è che le classi che scriviamo sono composte da semplici oggetti Java, i cosiddetti POJO. Questi oggetti sono dei Javabean che encapsulano le informazioni in unità ben distinte e facilmente identificabili dal punto di vista funzionale (alta coesione funzionale). Non implementano alcuna interfaccia né hanno bisogno di un application server per poter funzionare, non sono né più né meno che semplici classi Java con le regole seguite dai Javabean.
Chi ha già sviluppato soluzioni di persistenza con EJB 2 sa quanto tediosa e "bug prone" fosse la creazione di bean di entità, con la necessaria estensione di interfacce e il supporto di file di configurazione. Con JPA nulla di tutto ciò dovrà essere fatto. Questa particolare situazione porta vantaggi in termini di sviluppo: semplifica l'uso di test di unità sui singoli componenti e riduce drasticamente il tempo di sviluppo a livello di componente.
Inoltre, un'entità così fatta non ha il problema di poter essere serializzata ed utilizzata in remoto. Un EJB 2 usato per la persistenza aveva la problematica di essere un oggetto remoto e quindi la necessità di esportare non l'oggetto in sé, ma il proxy, che attraverso RMI avrebbe effettuato le operazioni di lettura/scrittura sul database (immaginiamo un'architettura dove Web server e application server sono distribuiti). In particolare, quest'ultima situazione ha visto moltiplicarsi l'uso di oggetti POJO incapsulati in un EJB in modo da poter essere facilmente rappresentati e serializzati in fase di visualizzazione.
Andiamo a vedere ora il POJO (quindi l'entità) che rappresenta un conto corrente bancario nel nostro dominio applicativo:
Listato 1. Definisce l'entità BankAccount usata per la persistenza di un conto corrente bancario
@Entity
public class BankAccount {
//Campo di indentificazione (deve essere univoco)
//Nome e bilancio
//Costruttore pubblico
/* noop */
//Metodi getter e setter per poter accedere alle proprietà persistenti
// ...
//Altri metodi di utilità
Come ogni javabean creiamo una classe che contiene le variabili di istanza rappresentanti la nostra entità, in questo caso un id, un nome e il valore del saldo. Segue la definizione dei costruttori (quello di default deve essere sempre definito) e dei metodi getter e setter. Eventualmente è possibile inserire altri metodi, come una normale classe Java.
Ovviamente è necessario annotare la classe in modo che chi ne gestirà le operazioni di persistenza sappia come gestirla. La classe dovrà essere annotata come @Entity e già di per sé sarebbe sufficiente in quanto, come default, tutte le variabili vengono considerate come persistenti e quindi gestite come tali. Tralasciamo ai prossimi articoli di approfondimento la definizione e l'uso delle altre annotazioni e citiamo solo l'annotazione qui usata per definire l'identificativo @Id, usato per marcare come chiave la variabile di istanza id.
Per poter compilare è necessario importare le librerie concrete per la JPA. Come implementazione tipica trovate il download su oracle.com.
Vediamo un primo semplice test per valutare il comportamento della classe:
Listato 2. Classe usata per effettuare un semplice test
public class SimpleTest {
public static void main(String[] args) {
System.out.println("Test di unità entity BankAccount (JPA)");
// Creo un po' di istanze
BankAccount ba=new BankAccount(1,"Zio Paperone",50000);
BankAccount ba2=new BankAccount(3,"Paperino",0);
BankAccount ba3=new BankAccount(11,"Braccio di Ferro",4500);
BankAccount ba4=new BankAccount(14,"Testa di Chiodo",100);
// Vediamole...
System.out.println(ba);
System.out.println(ba2);
System.out.println(ba3);
System.out.println(ba4);
}
}
Come vediamo ci comportiamo in maniera normale, senza preoccuparci di persistenza alcuna: tutto dovrà essere gestito dal layer di persistenza. In realtà, ancora la persistenza non è stata definita in alcun modo, né il database, né come mappare l'oggetto su una tabella. La classe che abbiamo creato è un ottimo strumento (seppure in questo contesto banale) per poter effettuare dei test sulla funzionalità della classe. Altri framework non consentono questa funzionalità, che è una peculiarità molto importante in quanto permette a diversi team di lavorare in maniera separata ed effettuare le proprie prove.
Definire la persistenza
La parte importante viene in realtà adesso: come definire la persistenza. Ovviamente abbiamo la possibilità di gestire configurazioni complesse, ma vediamo la configurazione minimale per poter far funzionare il sistema.
Listato 3. Configurazione minimale
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence
http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd">
<persistence-unit name="jpaTest" transaction-type="RESOURCE_LOCAL">
<provider>oracle.toplink.essentials.ejb.cmp3.EntityManagerFactoryProvider</provider>
<class>it.html.jpa.entity.BankAccount</class>
<properties>
<property name="toplink.jdbc.user" value="root"/>
<property name="toplink.jdbc.password" value="xxxxx"/>
<property name="toplink.jdbc.url" value="jdbc:mysql://localhost:3306/jpaTest"/>
<property name="toplink.jdbc.driver" value="org.gjt.mm.mysql.Driver"/>
<property name="toplink.ddl-generation" value="create-tables"/>
</properties>
</persistence-unit>
</persistence>
Il file persistence.xml dovrà essere presente a livello della cartella META-INF (anche se non si tratta di una Web application). Dopo aver definito la classe concreta provider (lasciamo quella fornita dall'implementazione di default) e le classi interessate (solo una in questo caso) inseriamo le proprietà JDBC necessarie: user, password, url (del database) e driver (il database e MySQL nel caso d'esempio). Inoltre abilitiamo la proprietà per effettuare le chiamate DDL e quindi la generazione della tabella se essa non esiste (utile in questo caso in modo da creare lo schema in automatico mappando le proprietà delle classi interessate).
Rendiamo ora persistente il primo esempio e vediamo il comportamento dinamico sul database.
Listato 4. Classe di test per verificare l'effettiva persistenza sul database
..//
public class PersistenceTest {
public static void main(String[] args) {
System.out.println("Unit test persistenza JPA");
//L'oggetto che ci permette di gestire la persistenza è l'entity manager
EntityManagerFactory factory = Persistence.createEntityManagerFactory("jpaTest");
EntityManager manager = factory.createEntityManager();
//Creo un pò di istanze
BankAccount ba=new BankAccount(1,"Zio Paperone",50000);
BankAccount ba2=new BankAccount(3,"Paperino",0);
BankAccount ba3=new BankAccount(11,"Braccio di Ferro",4500);
BankAccount ba4=new BankAccount(14,"Testa di Chiodo",100);
//e le rendo persistenti
manager.getTransaction().begin();
manager.persist(ba);
manager.persist(ba2);
manager.persist(ba3);
manager.persist(ba4);
//Commit dei dati
manager.getTransaction().commit();
}
..//
Il test, come vediamo, è effettuato da una classe java standalone, quindi eseguibile senza necessità di contesto alcuno. L'oggetto fondamentale che gestisce la persistenza è l'oggetto EntityManager, attraverso il quale effettueremo diverse operazioni (inserimento, ricerca, transazioni, ecc). Questo oggetto è creato dinamicamente dalla lettura della configurazione (persistence.xml) vista in precedenza (chiamata con l'alias jpaTest). Dopo averlo definito, creiamo le istanze e le rendiamo persistenti attraverso l'uso del metodo persist(). Per poter funzionare correttamente è importante definire una transazione e incapsulare il metodo persist() al suo interno.
L'idea è quella di effettuare il commit della transazione se tutto va a buon fine, altrimenti il rollback se viene sollevata un'eccezione. In questo caso tralasciamo l'aspetto del rollback ma lo vedremo avanti. Eseguire questo pezzo di codice significa ritrovarsi nel database una tabella chiamata BANKACCOUNT con tre proprietà ID, NAME e BALANCE e quattro righe contenenti i valori aggiunti. Questo accade perchè abbiamo definito come comportamento iniziale la creazione della tabella e abbiamo lasciato tutto come default.
Il comportamento di default è infatti quello di mappare i nomi e i tipi delle variabili presenti nell'entità con gli stessi nomi e tipi nel database. Attraverso l'uso delle annotazioni è altresì possibile ridefinire questo comportamento in maniera personalizzabile.
Operazioni
Andiamo avanti con l'esempio introducendo due operazioni tipiche: il prelievo e il deposito. Avremmo potuto codificare queste due operazioni all'interno della stessa classe dell'entità, ma avremmo perso quella che a mio avviso è la potenzialità di un POJO, cioè il fatto di non avere metodi di logica (per quanto semplici essi siano). In tal modo un'entità è un semplicissimo oggetto contenitore e può essere utilizzato come vista di un dato sul database.
A tal proposito introduciamo una classe che gestisce i due metodi di logica. In un ambiente enterprise è facile pensare ad una classe di logica di business come ad un Session Bean. Vediamo la classe che gestisce le operazioni:
Listato 5. Gestisce le operazioni di logica applicativa
//Accetta l'entità BankAccount e definisce i metodi di logica applicativa.
//In pratica è una unità di logica stateless...
public class BankAccountOperation {
//Operazione di prelievo (senza gestione di casi eccezionali e transazioni)
public void withdraw(BankAccount account, double howmuch){
double balance=account.getBalance();
balance-=howmuch;
account.setBalance(balance);
}
//Operazione di deposito (senza gestione di casi eccezionali e transazioni)
public void deposit(BankAccount account, double howmuch){
double balance=account.getBalance();
balance+=howmuch;
account.setBalance(balance);
}
}
La classe ha due metodi, deposit e withdraw, entrambi accettano un oggetto account e la quantità di denaro da depositare o prelevare. La logica è quella di effettuare l'operazione e settare il risultato sull'entità. Attenzione perché per semplicità non stiamo gestendo alcun caso eccezionale (saldo negativo o cose del genere).
Vediamo allora le operazioni in azione:
Listato 6. Operazioni messe in pratica
//... //1. Ricerca: //2. Versamento positivo (Zio Paperone fa un versamento a Paperino) //Qui gestiamo con attenzione la transazionalità, in modo da non aver //in nessun caso inconsistenza, quindi con rollback in caso di errore //Inizia la transazione //Prelevo la somma dal conto ba5 //e la aggiungo al conto ba7 //eccezione verificata, ritorniamo allo stato di partenza //Controlliamo nuovamente i conti dopo il versamento positivo //...
Come prima cosa utilizziamo l'operazione di ricerca che è molto facile da usare attraverso l'EntityManager visto in precedenza. Il metodo accetta la classe e l'identificativo. Nel caso un oggetto non venga trovato il valore restituito è null (come nel caso del BankAccount ba6).
Per quanto riguarda le operazioni sui conti, simuliamo un bonifico da parte del conto 5 sul conto 7. Apriamo una transazione e richiamiamo le operazioni withdraw() e deposit() della classe di logica vista in precedenza. A questo punto si potrebbe pensare ad un metodo che gestisca il bonifico a livello di logica di business, qui non lo abbiamo fatto per sfruttare la transazione a livello più alto (se una delle due operazioni fallisce, nulla viene salvato).
Alla fine delle due operazioni chiudiamo la transazione attraverso un commit. Nel caso qualcosa vada storto effettuiamo il rollback e mostriamo il risultato.
Vediamo a questo punto come viene gestita una situazione anomala attraverso l'operazione di rollback. Proviamo ad effettuare un'operazione di deposito su un conto nullo (il conto 6) e vediamo come la prima operazione di prelievo sia annullata automaticamente:
Listato 7. Gestione delle eccezioni
//... //3. Versamento con eccezione (Zio Paperone fa un versamento a NULL) //Qui gestiamo con attenzione la transazionalità, in modo da non aver //in nessun caso inconsistenza, quindi con rollback in caso di errore //Inizia la transazione //Prelevo la somma dal conto ba5 //e la aggiungo al conto ba6 //eccezione verificata, ritorniamo allo stato di partenza //Controlliamo nuovamente i conti dopo il versamento negativo
Passo dopo passo controllate la base di dati in modo da vedere come effettivamente il middleware stia lavorando. Eseguendo l'esempio avrete un risultato simile al seguente:
Figura 1. Procedimento di funzionamento
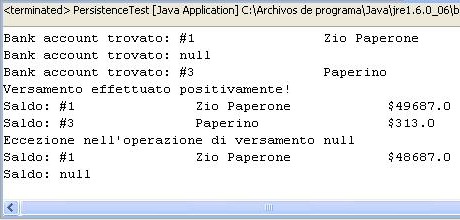
Conclusioni
Come già detto, il motivo principale dell'introduzione di questa tecnologia è stato il sostanziale fallimento della persistenza di EJB 2.0. A mio avviso una tecnologia molto avanzata e dalle ottime intenzioni ma oggettivamente troppo complessa per poter essere utilizzata in maniera massiva. Le principali pratiche d'uso utilizzate dagli sviluppatori hanno di fatto suggerito una svolta verso un middleware più facile da utilizzare e sicuramente più manutenibile. Anche dal punto di vista delle performance, se utilizzato con accortezza (e con l'appoggio degli EJB Session Bean per la logica applicativa) JPA diventa uno strumento Enterprise indiscutibilmente di alto livello.
Per quanto riguarda la comparazione con altri middleware di persistenza non c'è molto da dire. Hibernate e Ibatis sono i principali rivali ma, fondamentalmente, presentano le stesse caratteristiche e concetti di base. Ovviamente in un contesto enterprise è ideale accoppiare tutte le tecnologie già compliant in modo da avere un livello di compatibilità elevato. Di sicuro, la presenza delle annotazioni (presenti anche nelle recenti versioni di altri middleware di persistenza), permette di effettuare uno sviluppo più rapido.
Infine è da sottolineare l'importanza di avere uno strumento che possa essere testato al di fuori del contesto dell'application server. Questo è il vero punto di forza di JPA e viceversa la debolezza e il motivo del declino di EJB 2 (lato persistenza). Essere in grado di porre semplici test di unità e valutare l'effettiva persistenza diventa critico, soprattutto in situazioni molto più complesse dell'esempio che abbiamo visto nell'articolo. Attraverso il test standalone ora saremo in grado di valutare la bontà del codice scritto in maniera veloce e automatizzata e soprattutto, senza bisogno di alcun server su cui effettuare lunghe e tediose operazioni di deploy.

