
Il Full-Text Search è una funzionalità, introdotta a partire da SQL Server 2000, che consente di eseguire ricerche testuali sui campi di tipo CHAR, VARCHAR, NCHAR, NVARCHAR, TEXT, NTEXT, IMAGE, VARBINARY(MAX) e XML in maniera molto efficiente.
A differenza di quanto avviene con il predicato LIKE, che utilizza esclusivamente pattern di caratteri, le query di tipo Full-Text eseguono ricerche linguistiche sui dati, analizzando le parole e le frasi in base alle regole del linguaggio. I benefici maggiori del Full-Text Search si ottengono soprattutto eseguendo ricerche testuali su grandi quantità di dati di tipo non strutturato: in un caso del genere, la velocità di risposta è nettamente migliore rispetto a quella che si avrebbe utilizzando operatori come il LIKE .
Questa componente è disponibile in tutte le attuali versioni commerciali di SQL Server, ovvero Workgroup, Standard ed Enterprise; per utilizzarla con SQL Express Express Edition, invece, è necessario installare la release che comprende gli Advanced Services, scaricabile gratuitamente. Infine, SQL Compact Edition non supporta il Full-Text Search.
Come funziona
Per effettuare ricerche di tipo Full-Text, SQL Server utilizza un'apposita struttura dati chiamata Full-Text Index. Si tratta di un tipo particolare di indice che viene gestito dal servizio Microsoft Full-Text Engine for SQL Server (MSFTESQL). La sua struttura è diversa da quella degli indici tradizionali: mentre questi ultimi utilizzano il cosidetto B-tree, il Full-Text Index si basa su un indice a liste invertite contenente le singole parole del testo che si vuole indicizzare. Esso, inoltre, è memorizzato in un file su disco che viene poi gestito dal servizio sopra menzionato.
Per creare un indice Full-Text su un tabella, essa deve contenere una singola colonna con i vincoli UNIQUE e NOT NULL. Supponiamo di avere una tabella Libri così definita:
Creare una tabella "Libri"
CREATE TABLE Libri ( LibroID INT IDENTITY(1, 1) NOT NULL CONSTRAINT IX_LibroID PRIMARY KEY, Titolo NVARCHAR(255) NOT NULL, Autore NVARCHAR(50) NOT NULL, Riassunto VARCHAR(MAX) )
Supponiamo anche di avere un indice Full-Text definito sulla colonna Riassunto: al suo interno troviamo un'associazione che ci dice, ad esempio, che la parola "tecnologia" compare nella dodicesima e nella trentasettesima posizione della colonna Riassunto del record il cui campo LibroID vale 5. Quando elabora una query di tipo Full-Text, il servizio Full-Text Engine restituisce a SQL Server i riferimenti alle righe che corrispondono ai criteri di ricerca; a questo punto il DBMS utilizza tali riferimenti per recuperare i record veri e propri.
Per approfondire il discorso sull'architettura del sistema di Full-Text Search, si consiglia questa pagina di MSDN.
Configurare un database per l'utilizzo del Full-Text Search
SQL Server fornisce una serie di stored procedure per configurare il Full-Text Search. Le stesse operazioni, tuttavia, possono essere eseguite molto più facilmente utilizzando il Management Studio, grazie ad un wizard in grado di richiamare tutte le istruzioni necessarie alla configurazione. Vediamo, quindi, come impostare database e tabelle per l'utilizzo del Full-Text Search utilizzando gli strumenti grafici.
Creiamo un database di prova chiamato "Biblioteca" e verifichiamo che l'opzione Use full-text indexing sia attivata.
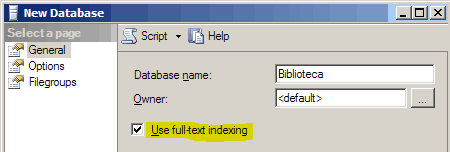
Il Full-Text indexing può essere attivato anche su un database già esistente, utilizzando la sezione "Files" della sua finestra "Proprieties".
A questo punto aggiungiamo al database la tabella Libri eseguendo il comando SQL come abbimo visto sopra, quindi popoliamola con lo script Insert.sql.
Ora possiamo creare l'indice Full-Text vero e proprio sulla colonna Riassunto della tabella. Clicchiamo con il tasto destro sulla tabella Libri e selezioniamo il comando "Full-Text index", quindi "Define Full-Text index" per avviare la procedura guidata "Full-Text Indexing Wizard".
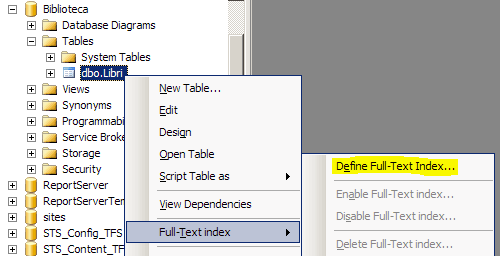
Anzitutto, è necessario selezionare l'indice della tabella che si desidera utilizzare; nel nostro caso, l'unico disponibile è IX_LibroID. Dobbiamo poi indicare quali colonne vogliamo inserire nell'indice Full-Text; nella stessa finestra è anche possibile indicare la lingua per la funzionalità di "Word Breaker" della colonna corrispondente. Selezioniamo la colonna Sommario e impostiamo "Italian" nella colonna "Language for Word Breaker".
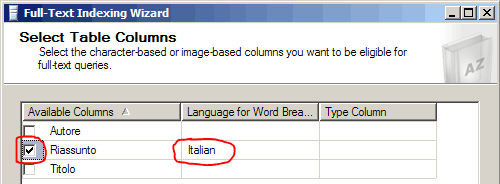
Il Word Breaker è un modulo utilizzato per suddividere il testo in token basandosi sulle regole lessicali della lingua specificata. In SQL Server 2005 sono presenti Word Breaker per 23 impostazioni internazionali; l'elenco completo è disponibile sul sito di Microsoft TechNet.
Oltre al Word Breaker, viene utilizzato anche uno stemmer per determinare la coniugazione dei verbi e la flessione delle parole. Per poter effettuare ricerche linguistiche, quindi, è fondamentale impostare correttamente la lingua utilizzata nelle colonne su cui verrà costruito l'indice.
La schermata successiva consente di specificare la modalità di aggiornamento dell'indice: è possibile selezionare una delle seguenti opzioni:
- Automatically
- Manually
- Do not track changes
Per il nostro esempio, lasciamo selezionata l'opzione Automatically. Dopo aver premuto il pulsante "Next" indichiamo il nome da attribuire all'indice (d'ora in avanti chiamato anche Catalogo), la sua posizione sul file system e se vogliamo che esso tenga conto degli accenti oppure no. Assegniamogli il nome FTS_Riassunto.
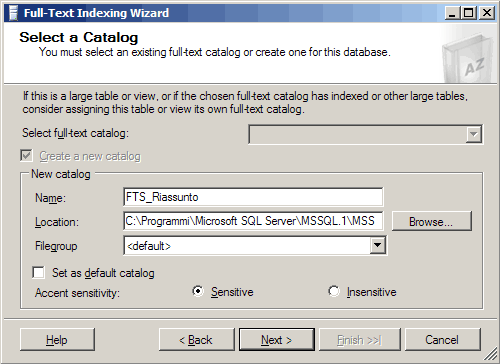
Per quanto riguarda la posizione dell'indice su file system, nel caso in cui sia possibile è consigliabile riservare uno o più dischi esclusivamente per il catalogo: le operazioni di gestione dell'indice, infatti, sono molto costose dal punto di vista delle operazioni in input/output, dal momento che è necessario leggere le informazioni dal database di SQL Server e utilizzarle per costruire il file su disco; per tale motivo, utilizzando un disco separato, si riduce la possibilità che il sottosistema di I/O diventi un collo di bottiglia per le prestazioni.
Con il passaggio seguente della procedura guidata è possibile creare o modificare la pianificazione di popolamento per l'indice Full-Text, utile quando non è stato selezionato l'aggiornamento automatico; nel nostro caso, quindi, possiamo lasciare vuota questa finestra. Per conoscere il significato delle opzioni disponibili in tale schermata, si consiglia di consultare la documentazione in linea.
A questo punto, un clic sul pulsante "Next" porta ad una schermata riepilogativa; la pressione del tasto "Finish" avvia la creazione dell'indice vero e proprio. Una volta definito, è possibile modificarne le proprietà facendo clic con il tasto destro del mouse sulla tabella relativa e selezionando i comandi che sono raggruppati sotto la voce Full-Text index.
Per creare e gestire l'indice è necessario disporre dell'autorizzazione REFERENCES sul catalogo Full-Text e di quella ALTER sulla tabella, oppure essere membri del ruolo predefinito del server sysadmin o dei ruoli predefiniti del database db_owner o db_ddladmin.
Nella seconda parte dell'articolo analizzeremo gli operatori che SQL Server mette a disposizione per eseguire ricerche di tipo linguistico sui dati e cercheremo di capire quando conviene utilizzare gli indici Full-Text.
Riprendiamo il database Biblioteca che abbiamo definito nella prima parte di questo articolo e mostriamo come eseguire ricerche di tipo Full-Text sulla colonna Riassunto della tabella Libri. A questo scopo, si devono utilizzare specifici operatori messi a disposizione da SQL Server, i più importanti dei quali sono CONTAINS e FREETEXT. Essi possono essere utilizzati esclusivamente nella clausola WHERE di un'istruzione SELECT , ma possono comparire anche all'interno di sottoquery.
CONTAINS
Il predicato CONTAINS consente di ricercare:
- Una parola, una frase o un prefisso
- Una parola "vicina" ad un'altra (la cosiddetta ricerca per prossimità)
- Una parola generata da un'altra per flessione (ad esempio, le parole giochi e giocare derivano dalla radice comune gioco)
- Un sinonimo di una parola
Sintassi di CONTAINS
CONTAINS
( { column_name | (column_list) | * }
, '< contains_search_condition >'
[ , LANGUAGE language_term ]
)
I primi due parametri, obbligatori, sono, rispettivamente, il nome della colonna o delle colonne su cui eseguire la query e le condizioni di ricerca di tipo Full-Text, che possono anche essere molto complesse. Nel caso in cui la condizione sia una frase, oppure si voglia cercare per il prefisso di una parola, è necessario racchiudere l'espressione tra virgolette doppie. Il terzo argomento, facoltativo, indica la lingua con cui si vuole eseguire l'interrogazione; nel caso in cui non sia presente, viene utilizzata la lingua specificata in fase di creazione dell'indice.
Se, come primo parametro, si usa un asterisco, la ricerca viene automaticamente estesa a tutte le colonne della tabella su cui è stato definito un indice Full-Text.
Per una spiegazione più dettagliata della sintassi supportata da questo comando, si consiglia di consultare la guida di riferimento di T-SQL.
È importante ricordare che le ricerche di tipo Full-Text sono case-insensitive, ovvero non fanno distinzione tra maiuscole e minuscole. Inoltre, la punteggiatura viene ignorata e le parole non significative (ad esempio "il", "con", "da") non sono archiviate nell'indice, quindi vengono escluse dai criteri di ricerca: esse, infatti, tipicamente sono molto frequenti nei documenti, quindi non hanno alcuna utilità nella ricerca di testo specifico.
Vediamo qualche esempio di ricerca sul nostro database di prova con l'utilizzo dell'operatore CONTAINS. La seguente interrogazione restituisce i libri il cui sommario contiene il nome Renzo oppure Michele:
SELECT Autore, Titolo FROM Libri WHERE CONTAINS(Riassunto, '"Renzo" OR "Michele"');
Notiamo che i nomi sono racchiusi tra virgolette doppie, ma, trattandosi di termini singoli, in questo caso era anche possibile non utilizzarle. La prossima query, invece, recupera i testi che parlano dell'innamoramento, attraverso una ricerca basata sul prefisso innamor:
SELECT Autore, Titolo FROM Libri WHERE CONTAINS(Riassunto, '"innamor*"');
L'asterisco corrisponde a zero, uno o più caratteri della parola. In questo caso le doppie virgolette sono obbligatorie, altrimenti sarebbe stata eseguita una ricerca esatta di innamor*, che non avrebbe restituito alcun risultato.
Utilizzando l'operatore CONTAINS, inoltre, è possibile eseguire ricerche per i diversi tempi e coniugazioni di un verbo oppure per la forma singolare e plurale di un nome. Supponiamo, ad esempio, di voler cercare il verbo morire indipendentemente dalla forma in cui appare nel testo:
SELECT Autore, Titolo FROM Libri WHERE CONTAINS(Riassunto, 'FORMSOF (INFLECTIONAL, morire)');
Con la parola chiave FORMSOF(INFLECTIONAL, ... si fa in modo che venga utilizzato lo stemmer per identificare il termine specificato, ovvero, in questo caso, si sta richiedendo a SQL Server di ricercare tutti i token che derivano dal verbo morire.
Il comportamento dello stemmer dipende dalle regole di analisi morfologica della lingua utilizzata. Questa interrogazione restituisce tutti i libri in cui compare il verbo morire, qualunque sia la sua forma e coniugazione: ad esempio, tra gli altri otteniamo "Il signore della mosche", dove è utilizzato muoiono.
Con FORMSOF, oltre ad INFLECTIONAL, si può utilizzare anche THESAURUS: specificando questo parametro, si indica a SQL Server di appoggiarsi ad un file XML contenente un elenco di sostituzioni per generare termini aggiuntivi con cui estendere la ricerca. Questi file sono contenuti nella directory SQL_Server_install_pathMicrosoft SQL ServerMSSQL.1MSSQLFTDATA ed hanno nome ts<abbreviazione_lingua>.xml. Ad esempio, il thesaurus per la lingua italiana si chiama tsITA.xml.
Tali archivi, tuttavia, inizialmente sono vuoti, quindi è compito dell'utente popolarli con le sostituzioni che vuole utilizzare per la ricerca. È possibile consultare la documentazione in linea per informazioni sulla creazione dei file del thesaurus.
FREETEXT
Il predicato FREETEXT, invece, è utilizzato per ricercare parole e frasi corrispondenti al significato e non all'esatta formulazione del testo nelle condizioni della query. Il suo funzionamento è il seguente:
- Separa la stringa cercata in token in base ai delimitatori di parola
- Genera le forme flesse di ogni parola
- Identifica una lista di espansioni o sostituzioni dei termini in base alle corrispondenze nel thesaurus (qualora sia presente)
Sintassi di FREETEXT
FREETEXT
( { column_name | (column_list) | * }
, 'freetext_string'
[ , LANGUAGE language_term ]
)
La sintassi è simile a quella già vista per CONTAINS. La differenza riguarda il modo in cui si esprime la condizione di ricerca.
La stringa specificata in freetext_string, infatti, viene sottoposta alla sillabazione, all'analisi morfologica e al thesaurus nel caso in cui non sia racchiusa tra virgolette; in caso contrario, viene ricercata la frase esatta, senza eseguire operazioni di sillabazione e sostituzione con sinonimi.
Con FREETEXT, inoltre, non è possibile utilizzare le parole chiave AND, OR e NOT, che in questo caso sono considerati termini non significativi e, pertanto, vengono ignorati. Infine, non sono ammessi i caratteri jolly e le altre espressioni previste da CONTAINS. Consideriamo la query seguente:
SELECT Autore, Titolo FROM Libri WHERE FREETEXT(Riassunto, 'sparare uccidere');
Essa restituisce i libri che contengono una qualsiasi forma flessa di dei verbi sparare o uccidere: in particolare, nel nostro caso otteniamo "Quo vadis?", in cui compare il termine uccisa, "Il signore delle mosche", al cui interno troviamo la parola ucciso, e "Gli indifferenti", dove è usato il verbo sparargli.
CONTAINTSTABLE e FREETEXTTABLE
Gli operatori CONTAINSTABLE e FREETEXTTABLE sono le controparti di CONTAINS e FREETEXT: mentre questi ultimi sono utilizzati nelle clausole WHERE, CONTAINTSTABLE e FREETEXTTABLE restituiscono risultati tabellari, quindi possono comparire in ogni punto di una query dove è prevista una tabella (tipicamente, la clausola FROM di un'interrogazione).
Le query basate su CONTAINSTABLE restituiscono l‘indice di pertinenza del risultato (RANK) e la UNIQUE KEY dei record che soddisfano i criteri specificati. Tale funzione utilizza le stesse condizioni di ricerca del predicato CONTAINS, come illustrato in precedenza.
Sintassi di CONTAINSTABLE
CONTAINSTABLE
( table , { column_name | (column_list ) | * }
, ' < contains_search_condition > '
[ , LANGUAGE language_term]
[ , top_n_by_rank ]
)
Anche la sintassi, quindi, è molto simile: table è il nome della tabella su cui eseguire la ricerca Full-Text, i successivi tre parametri hanno lo stesso significato già visto per l'operatore CONTAINS.
L'ultimo argomento specifica che devono essere restituiti solo gli n risultati con il più alto indice di pertinenza (RANK); ogni riga del risultato, infatti, contiene nella colonna RANK un valore compreso tra 0 e 1000 che indica il livello di corrispondenza con i criteri di selezione.
Un tipico utilizzo dell'operatore CONTAINSTABLE consiste nell'effettuare ricerche per prossimità o ricerche pesate, con la possibilità di filtrare e ordinare i dati in base all'indice di pertinenza di ogni record individuato. Ad esempio:
SELECT Autore, Titolo FROM Libri INNER JOIN CONTAINSTABLE(Libri, Riassunto, 'Michele') AS T ON Libri.LibroID = T.[KEY] ORDER BY T.[RANK] DESC;
Innanzi tutto, poiché CONTAINSTABLE restituisce solo il RANK e la chiave dei risultati, per ottenere i dati veri e propri è necessario effettuare una giunzione con la tabella Libri in base al valore dell'indice. I risultati sono ordinati in base alla pertinenza: osserviamo che il nome Michele compare sia ne "I Malavoglia" sia ne "Gli indifferenti", ma poiché è presente più volte nel riassunto di quest'ultimo romanzo, ha un RANK maggiore, quindi viene restituito per primo.
La seguente interrogazione, invece, utilizza la parole chiave ISABOUT per attribuire un peso diverso a ciascun termine ricercato:
SELECT Autore, Titolo
FROM Libri INNER JOIN
CONTAINSTABLE(Libri, Riassunto, 'ISABOUT(
matrimonio WEIGHT(.4),
FORMSOF(INFLECTIONAL, sposare) WEIGHT(.6)
)') AS T
ON Libri.LibroID = T.[KEY]
ORDER BY T.[RANK] DESC
In questo caso, al termine matrimonio e alle forme flesse del verbo sposare vengono assegnati pesi (WEIGHT) diversi. L'argomento di WEIGHT deve essere un numero compreso tra 0 e 1; tali pesi influenzano il valore dell'attributo RANK corrispondente.
L'operatore FREETEXTTABLE, infine, si comporta nello stesso modo di CONTAINSTABLE, quindi anch'esso restituisce una tabella con le colonne RANK e KEY; l'unica differenza sta nelle condizioni di ricerca, che in questo caso riprendono la formulazione di FREETEXT:
FREETEXTTABLE
( table , { column_name | (column_list) | * }
, 'freetext_string'
[ , LANGUAGE language_term ]
[ , top_n_by_rank ]
)
Osserviamo la query vista in precedenza con FREETEXT, riscritta utilizzando FREETEXTTABLE per ordinare i risultati in base all'indice di pertinenza:
SELECT Autore, Titolo FROM Libri INNER JOIN FREETEXTTABLE(Libri, Riassunto, 'sparare uccidere') AS T ON Libri.LibroID = T.[KEY] ORDER BY T.RANK DESC;
Per quanto riguarda i diritti per l'esecuzione di query Full-Text, gli operatori descritti possono essere utilizzati dagli utenti che dispongono dell'autorizzazione SELECT per le colonne della tabella o delle tabelle a cui si fa riferimento nelle interrogazioni.
Tutte le interrogazioni presentate sono nel file allegato all'articolo.
Quando conviene usare gli indici Full-Text
La tipica domanda che sorge a questo punto è la seguente: perché utilizzare gli indici Full-Text per una query che può essere risolta con un semplice operatore LIKE? Ad esempio, una delle interrogazioni che abbiamo mostrato in precedenza:
SELECT Autore, Titolo FROM Libri WHERE CONTAINS(Riassunto, '"innamor*"');
Può essere riscritta con l'operatore LIKE nel modo seguente:
SELECT Autore, Titolo FROM Libri WHERE Riassunto LIKE '%innamor%'
La differenza sta nel tempo di esecuzione: anche se nel nostro caso non è evidente, date le ridottissime dimensioni della tabella, la ricerca in un colonna di tipo VARCHAR con l'operatore LIKE può richiedere parecchio tempo. È più efficiente utilizzare le funzionalità di Full-Text Search di SQL Server, che si comportano decisamente meglio perché utilizzano un indice costruito proprio sui campi su cui si effettua la ricerca.
Il vantaggio in termini di prestazioni è visibile soprattutto quando si eseguono query su grandi quantità di dati non strutturati: una query che fa uso dell'operatore LIKE eseguita su milioni di righe può richiedere alcuni minuti, mentre per un'interrogazione Full-Text sugli stessi dati possono essere necessari solo pochi secondi.
Bisogna comunque evidenziare che la manutenzione del catalogo ha un costo non trascurabile, soprattutto se si modificano spesso i dati contenuti nelle colonne indicizzate. Nel caso in cui le informazioni siano prevalentemente statiche (come i riassunti di libri del nostro esempio), l'utilizzo di indici Full-Text sui campi testuali è sicuramente consigliabile.
