
In un altro articolo ho affrontato l'argomento della separazione tra XHTML, CSS e JavaScript. L'articolo si concentrava sulle tecnologie client-side ed affermavo che sul lato server le cose erano un po' più complicate. Eppure, proprio l'elaborazione server-side avrebbe più che mai bisogno di una netta separazione tra le varie tecnologie Web.
Nello sviluppo e nella manutenzione di un'applicazione Web, infatti, convergono le attività di diverse professionalità: dal grafico al redattore dei contenuti, dal programmatore all'amministratore di database, per non parlare dell'amministratore di sistema. Tra l'altro, non è detto che il programmatore che deve sviluppare l'interfacciamento dell'applicazione Web con un database abbia anche conoscenza di JavaScript per gestire al meglio l'interazione con l'utente nell'interfaccia Web.
Ragionando su queste problematiche mi sono chiesto: cosa manca all'elaborazione server-side per realizzare una separazione tra le diverse tecnologie così come può avvenire sul client?
Approcci server-side
Esistono diverse tecnologie per l'elaborazione server-side. Tralasciando l'uso diretto dell'interfaccia CGI o di tecnologie come ISAPI, le tecnologie più diffuse hanno un modello comune: un interprete che produce pagine HTML elaborando le istruzioni che trova all'interno di un template. Su questo modello si basano tecnologie come ASP, PHP, JSP e CFML.
Il problema principale di questo approccio consiste nel fatto di avere dei template che mettono insieme codice HTML o pseudo HTML ed istruzioni in un dato linguaggio di programmazione o di scripting.
In queste condizioni, come può essere separato il compito del grafico da quello del programmatore? Avete mai provato a dare ad un grafico una pagina ASP o PHP per una revisione estetica? Spesso i risultati sono di due tipi:
- il grafico modifica accidentalmente le istruzioni inserite dal programmatore, con ovvie conseguenze sul funzionamento della pagina
- il grafico non mette le mani in certe porzioni di codice ed il programmatore è costretto a fare il grafico...
In alcuni casi si ricorre a convenzioni, meta-template o strumenti creati di proposito per aggirare l'ostacolo, ma in ogni caso si tratta sempre di espedienti che cercano di superare le limitazioni imposte da questo modello di elaborazione.
Un piccolo passo in avanti può essere considerato l'approccio del code behind di ASP.NET. Purtroppo, però, il codice XHTML generato automaticamente da ASP.NET non sempre è valido e quasi sempre viene generato codice JavaScript inserito all'interno del markup. Inoltre, chi si occupa della revisione grafica, potrebbe non trovarsi a suo agio con elementi non HTML, come i controlli Web.
Un approccio molto ben fatto e basato sul pattern Model-View-Controller è quello di Ruby on Rails e di MonoRail. Purtroppo anche questi approcci prevedono la possibilità dell'uso di template che mettono insieme HTML ed istruzioni di programmazione.
Un possibile approccio alternativo?
È possibile impostare un modello di elaborazione che consenta di separare effettivamente codice XHTML, CSS, JavaScript e codice server-side? Se è possibile realizzare questa separazione sul client, perchè non è possibile farlo sul server?
In effetti credo che la cosa potrebbe essere realizzata anche sul server, utilizzando esattamente lo stesso approccio con cui è possibile separare il codice JavaScript dall'XHTML. Basterebbe mettere a disposizione del codice server-side proprio lo stesso Document Object Model a cui accede JavaScript. L'idea è riassunta sinteticamente nella seguente figura.
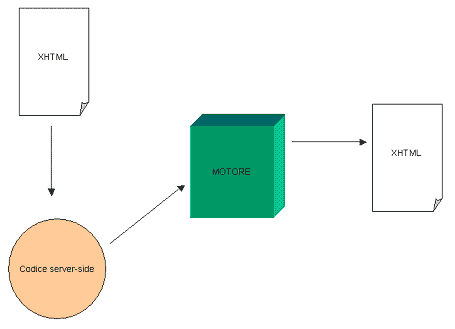
In pratica, ad ogni pagina XHTML è associato un oggetto (nel senso della programmazione ad oggetti) i cui metodi rappresentano le possibili elaborazioni server-side. Ad ogni richiesta di una pagina Web, il motore di questo ipotetico framework metterebbe a disposizione del codice server-side il DOM della pagina.
Tramite l'esecuzione delle istruzioni associate ai metodi dell'oggetto sarebbe possibile accedere ai diversi elementi della pagina e pre-elaborarli in maniera analoga a come avviene per le varie tecologie server-side, senza però alcuna commistione di XHTML e codice. Ad esempio, avendo una pagina XHTML come la seguente:
Listato 1. Documento XHMTL da elaborare
<html>
<head>
</head>
<body>
<div id="myDiv">
</div>
</body>
</html>
sarebbe possibile pre-elaborarla con un'istruzione analoga alla seguente:
Listato 2. Esempio di elaborazione
document.getElementById("myDiv").innerText = "Questa è una prova!";
proprio come avviene con JavaScript sul client. Naturalmente sul server sarebbe possibile utilizzare il linguaggio di programmazione preferito, dal momento che non si hanno problematiche di compatibilità. Anche se utilizzare JavaScript anche sul server porterebbe alcuni interessanti vantaggi, come ad esempio il riuso di codice client-side.
Conclusioni
L'approccio illustrato in questo articolo è soltanto un'idea di un possibile modello di elaborazione server-side speculare al modello client-side. Al momento sto facendo qualche esperimento per valutare se l'approccio può risultare valido sul piano pratico.
Se così fosse si avrebbero, a mio avviso, degli indubbi e concreti vantaggi:
- separazione effettiva tra le tecnologie Web e conseguente distribuzione delle competenze
- possibile indipendenza dal linguaggio di programmazione utilizzato per il codice server-side
- approccio uniforme sul client e sul server per l'accesso al DOM
Vi terrò aggiornati sulle evoluzioni.

