
JPA 2.0 (Java Persistence API) è una specifica Java per l'accesso, la persistenza e la gestione dei dati tra oggetti Java e database relazionali. JPA fornisce un modello di persistenza per POJO, sviluppato dagli esperti che hanno sviluppato l'EJB 3.0 ma non limitato a componenti EJB, è infatti utilizzabile da applicazioni Web o client, o anche all'esterno della piattaforma Java EE, come applicazione Java SE.
Entity beans ed enterprise beans avevano la fama di essere troppo pesanti e complicati per poter risultare utili, pertanto molte funzioni dei framework di persistenza sono state raccolte e incorporate in JPA.
Alcuni progetti come Hibernate, TopLink ed EclipseLink hanno fornito l'implementazione della specifica, fornendo spesso ulteriori elementi.
L'obiettivo di questo articolo, il primo di una serie con cui approfondiremo l'argomento, è quello di introdurre JPA nel quadro generale della persistenza in Java, descrivendone lo stato dell'arte, le caratteristiche essenziali, i vantaggi rispetto agli altri framework open-source.
Verranno quindi descritti i meccanismi alla base di JPA, dal mapping agli stati in cui transitano gli oggetti resi persistenti. Infine si mostreranno esempi di operazioni CRUD, riferiti a una delle principali implementazioni della specifica, Hibernate, dedicando particolare attenzione all'influenza che hanno sullo stato degli oggetti.
L'articolo è costituito dalle seguenti sezioni:
- Precondizioni
- L'evoluzione verso JPA
- ORM e JPA: i vantaggi- JPA versus JDO
- Meccanismi di base
- Un primo esempio, predisposizione del progetto
- Annotazioni JPA e operazioni CRUD in Hibernate
- Esecuzione passo-passo di un main
Per seguire l'articolo e sperimentare direttamente quanto affronteremo, bisogna sssicurarsi di avere installato sul computer il Java Development Kit (JDK 6, Update 24 o successiva). Si assume che sia stata correttamente impostata la variabile d'ambiente JAVA_HOME
Inoltre, per rendere persistenti i dati, JPA richiede un database relazionale che può essere messo a disposizione da un RDBMS o in modo indiretto, ad esempio da un application server (che può fornire un embedded database Guida al Linguaggio SQL Introduzione a HyperSQL
Il processo di trasformazione da oggetto istanza di una classe a dato di un database prende il nome di ORM
JPA non è un prodotto, ma una specifica Java POJO
Il vantaggio offerto da JPA consiste nell'abilitare un mapping oggetti-relazioni attraverso annotazioni o XML standard, definendo come avviene il mapping tra classi Java e tabelle di un database relazionale. JPA definisce inoltre le API di un EntityManager
JPA è la più recente tra le specifiche Java volte a fornire la persistenza. Le prime o non hanno avuto seguito o hanno registrato problemi, in particolare per quanto riguardava la complessità e il degrado delle prestazioni come nel caso di EJB CMP
Ciò ha portato alla creazione di un'altra specifica Java, lo standard JDO
Nel mezzo del confronto tra gli standard, continuarono a prosperare soluzioni basate su set di API proprietarie. Tra le principali ricordiamo Hibernate TopLink
In buona parte la diffidenza verso CMP era dovuta alla diffidenza verso Java EE, vista come troppo complicata e troppo rivolta a soluzioni specifiche (e proprietarie). Tutto ciò ha portato a una nuova specifica, EJB 3.0, con l'obiettivo principale di ridurre la complessità e unificare quanto di buono avevano da offrire le soluzioni offerte dai prodotti non conformi agli standard.
Ne è scaturita la specifica JPA
Ma non è tutto. JPA stesso si è evoluto passando alla specifica 2.0, approvata nel 2009, il cui scopo è offrire caratteristiche già presenti negli ORM più popolari. Le principali caratteristiche aggiunte riguardano:
- l'estensione delle funzionalità di mapping (ad esempio il supporto alla collezione di oggetti embedded
- il supporto alla validazione,
- Query Criteria API.
- è prevista la necessità di cambiare il tipo di database?
- è prevista la necessità di utilizzare in contemporanea diversi tipi di database?
- con il (EntityTransaction.)commit()
- quando è chiamato il (EntityManagaer.)flush()
- informazioni riguardanti una classe da mantenere in un file esterno;
- al crescere del numero di classi da rendere persistenti il file XML tende a divenire massivo e poco manutenibile;
Attualmente JPA sta evolvendo verso JPA 2.1.
Tutto ciò non ha portato al termine della proliferazione delle soluzioni alternative. Un esempio ne è l'EJP (Easy Java Persistence), un set di API per la persistenza che non richiede annotazioni o file di configurazione XML.
Il vantaggio dell'ORM sta essenzialmente nel riuso JDBC
Le soluzioni offerte risultano indipendenti da schemi e database e si appoggiano su di una cache utile a migliorare le performance. Non ultimo vantaggio il supporto alla concorrenza
Ai vantaggi offerti dall'ORM si aggiungono quelli di JPA. In primo luogo è uno standard vendor lock-in
JPA versus JDO
Nella sezione precedente abbiamo visto che JPA non è l'unico standard per abilitare la persistenza in Java. Una valida alternativa è costituita da JDO, occorre pertanto scegliere tra le due specifiche. L'argomento è stato a lungo dibattuto e non vi è una risposta insindacabile, ma una volta che si sono identificati i requisiti e il contesto di utilizzo non sarà difficile prendere una decisione.
I principali elementi di decisione si basano sulle specifiche e sulle caratteristiche desiderabili, integrabili da un'analisi dei trends di utilizzo.
Confrontare le specifiche
Per un confronto esaustivo anche se datato è possibile partire dalla tabella compararativa disponibile presso il sito Apache JDO.
Alla tabella segue un commento: JPA è di fatto un sottoinsieme di JDO, per cui tanto varebbe utilizzare JDO. Dopo una prima lettura della tabella l'osservazione sembrerebbe avere conferma. Consideriamo però quali sarebbero le caratteristiche a favore di JDO.
JDO non è rivolto esclusivamente ai database relazionali, al contrario di JPA. Ciò non è del tutto vero in quanto alcuni database ad oggetti, come ObjectDB, forniscono supporto a JPA.
Altri punti a favore di JDO riguardano un minore carico di vincoli per i POJO da rendere persistenti, nessun obbligo di indicare un campo identità, un supporto maggiore per la generazione automatica di chiavi primarie, gestione avanzata della fase di fetch (verrà descritta nella sezione successiva) e infine un numero maggiore di strutture dati supportate.
In definitiva le specifiche offerte da JDO coprono uno spettro maggiore. In compenso JPA è in espansione e nuove caratteristiche sono state aggiunte con la versione 2.0 e ancora con la 2.1, nell'ottica di colmare questo gap.
Caratteristiche desiderabili
Tra gli aspetti da confrontare ce ne sono alcuni fondamentali anche se qualitativi, quali manutenibilità, portabilità, usabilità e così via. Occorre pertanto porsi delle domande, una delle prime riguarda il tipo di DBMS utilizzato:
Se la risposta è negativa ed è ragionevole pensare di dover utilizzare solo database relazionali, JDO perde uno dei principali punti di forza ed è probabile che JPA sarà sufficiente a soddisfare le esigenze.
Altra domanda riguarda la diversificazione dell'offerta riguardante l'implementazione delle specifiche vendor lock-in
JPA ha ricevuto l'appoggio da parte dei principali attori del mercato, sia con prodotti a pagamento che open source, pertanto nell'ottica di una scelta di lungo termine JPA appare avvantaggiato promettendo una maggiore portabilità.
Direttamente connesso con il punto precedente, c'è l'aspetto dell'evoluzione della specifica
JPA o JDO, quale è il più utilizzato?
Dedichiamo uno spazio a parte alla diffusione d'utilizzo. Abbiamo visto che, a meno di esigenze particolari, JPA catalizza una maggiore attenzione da parte dei fornitori, attenzione accompagnata da una maggiore utilizzo. Senza scomodare i dati forniti dai rispettivi produttori e utilizzatori, osserviamo i risultati riguardanti il volume di ricerche su google (sezione Google Trends):
Google trends, JPA (in blu) versus JDO (in rosso)
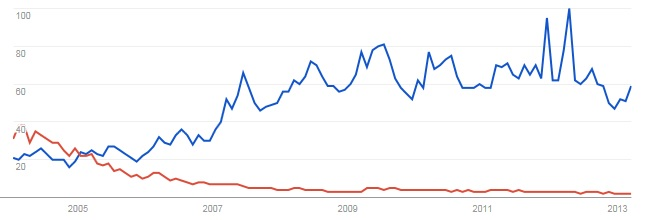
In blu il volume di ricerche riguardante JPA, in rosso JDO. Il grafico fotografa bene la situazione. JDO è stato bene accolto, ma ha visto perdere quote significative fino a diventare marginale, lasciando spazio ad altri attori, tra tutti JPA. Certamente non sono dati scientifici, ma la popolarità di JPA è innegabile.
È utile osservare anche il seguente grafico nel quale si aggiunge JDBC:
Google trends, JPA (in blu) versus JDO (in rosso) versus JDBC (in ocra)
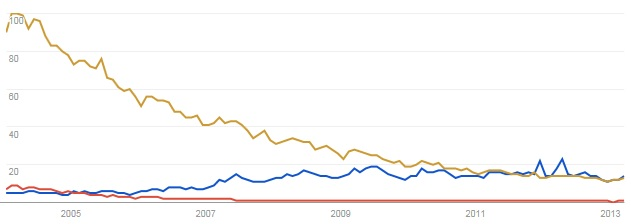
Come si vede, JDBC ha perso il grosso dell'attenzione di cui godeva in precedenza, ma mano che si affermavano gli altri strumenti che hanno reso JDBC un semplice intermediario tra il database e il livello della persistenza.
L'impatto di una maggiore popolarità della specifica non è di poco conto. Scegliere la specifica più popolare porta infatti ad avere una maggiore disponibilità di forum, esperienza (e codice d'esempio) di sviluppatori che ci lavorano costantemente, tool di supporto specifici da parte degli IDE, libri, tutorials.
Mapping
Per potere rendere persistente un oggetto occorre specificare come farlo, questo processo si chiama mapping. Il mapping ha subito un'evoluzione: alcuni database ad oggetti, ad esempio, non richiedono nessun processo di mapping; i prodotti basati su ORM spesso prevedevano tool per per il mapping da oggetti a data model già esistenti, memorizzando il mapping in meta-files, tabelle di database, XML e infine annotazioni.
Il mapping in JPA può avvenire o tramite annotazioni o file XML. Quello che consente JPA è ridurre la quantità di informazioni da fornire, in quanto è richiesto alle implementazioni di prevedere valori di default per quasi tutti gli aspetti del mapping.
Alla base, l'informazione da fornire consiste nello specificare quali oggetti rendere persistenti, attraverso l'annotazione @Entity o utilizzando il tag <entity> in un file XML che descrive l'unità di persistenza.
Le altre informazioni saranno mappate di default, incluse il nome della tabella, i nomi delle colonne, cardinalità e relazioni, logica di persistenza e di accesso agli oggetti.
La maggior parte delle implementazioni inoltre forniscono la possibilità di generare le tabelle del database a runtime, minimizzando così il lavoro richiesto per sviluppare rapidamente aplicazioni persistenti.
L'entità è dunque un oggetto del dominio della persistenza tipicamente associato a una tabella di un database relazionale e le istanze dell'entità solitamente corrispondono alle tuple della tabella.
Cache, EntityManager, PersistenceContext
Tra i programmi in esecuzione e il database si trova la cache. Nella cache vi si trovano copie dei dati e il flush consiste nel propagare al database le modifiche effettuate sui dati.
Un PersistenceContext è in pratica una cache con la propria connessione (non condivisa) al database.
Un EntityManager rappresenta un PersistenceContext (e quindi una cache) e compito dell'EntityManagerFactory è creare un EntityManager (in definitiva una cache).
Vi sono due tipi di PersistenceContext (dichiarati nel file persistence.xml):
| Tipo di PersistenceContext | Descrizione |
|---|---|
| Resource_Local | In questo caso l'utente è responsabile della creazione e gestione dell'EntityManager |
| JTA | Si fa affidamento su un container per la generazione e la gestione dell'EntityManager |
Quindi nel primo caso è cura dello sviluppatore generare e usare un EntityManagerFactory per ricavare un EntityManager. Avere attiva più di una istanza di EntityManager non è molto consigliabile, meglio evitare infatti di creare inconsistenze dovute all'assenza di sincronizzazione tra le diverse cache.
Nel secondo caso invece il container fornisce un riferimento all'EntityManager associato ad una Transazione JTA. Se non vi sono transazioni JTA in atto l'EntityManager non è usabile in quanto non vi è nessuna cache a disposizione.
Entity Lifecycle Management
Abbiamo già accennato all'EntityManager, le azioni che lo riguardano hanno effetto sul ciclo di vita delle istanze d'entità.
Quando una nuova istanza d'entità viene creata nella memoria Java, nulla cambia dal punto di vista degli oggetti persistenti. L'oggetto è detto in stato New o Transient.
Invocando il metodo persist() dell'EnityManager l'oggetto è reso persistente (tipicamente immagazzinandolo nella cache) e l'oggetto entra nello stato Managed. Per un oggetto entrato nello stato Managed le modifiche sono sincronizzate con il database, anche se non immediatamente ma nel flush time, un apposito metodo permette di forzare questa azione.
Il momento d'esecuzione del flush varia da implementazione ad implementazione, in Hibernate avviene:
Gli oggetti che sono stati resi persistenti, in seguito alla chiusura dell'EntityManagar, alla serializzazione o a una richiesta esplicita (detached(), JPA 2.0) entrano in uno stato denominato Detached, nel quale le modifiche effettuate non verranno propagate al database.
È possibile risincronizzare questi oggetti con il database, per far ciò occorre riportarli nello stato Managed. Ciò avviene invocando il metodo merge().
Lo stato Detached può essere utile ad esempio nel caso in cui occorra effettuare diverse modifiche sull'oggetto, senza che queste debbano comportare l'aggiornamento della cache e del database.
Infine vi è un altro stato, detto Removed, riservato agli oggetti rimossi dal database (remove()). Gli oggetti vengono rimossi dal database ma restano a disposizione nella memoria Java.
Il grafico seguente riassume gli stati e i metodi da invocare per modificare lo stato di un oggetto. In verde i metodi che riguardano l'interazione con il database:
Stati di JPA 2
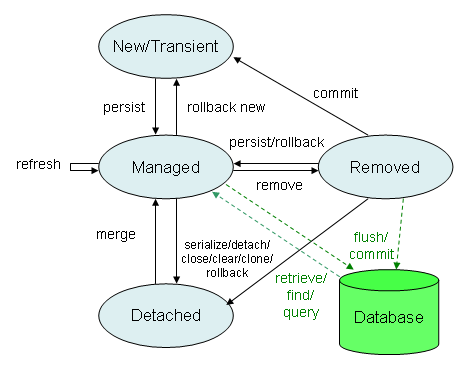
Nella seconda parte dell'articolo esamineremo un esempio pratico.
In questa parte dell'articolo iniziamo a lavorare ad un progetto d'esempio nel quale utilizzeremo le API messe a disposizione da JPA 2.0 per rendere persistente una classe. Andranno fatte alcune scelte, tra tutte andrà deciso se utilizzare le annotazioni o un file XML, quale database e quale implementazione della specifica utilizzare e così via.
Iniziamo esaminando come organizzare il progetto, poi ci occuperemo della classe da rendere persistente e di una classe deputata all'interazione con il database. Infine vedremo un main utilizzato come banco di prova per sperimentare gli effetti dei metodi sul database e sugli oggetti istanziati.
Il tutto sarà farcito di osservazioni utili a stimolare la curiosità sull'argomento e introdurre possibili comportamenti alternativi a quelli mostrati nell'esempio.
Non è necessario supporto particolare da parte dell'eventuale IDE. È sufficiente un normale IDE come ad esempio l'Eclipse IDE for Java Developers, avviando un normale progetto Java.
XML vs Annotazioni
Tra le scelte da compiere quando si lavora con JPA c'è quella di decidere se basarsi su file XML o sulle annotazioni per effettuare il mapping. Nessuno dei due metodi è giusto o sbagliato, ma l'XML tende a presentare diversi inconvenienti:
Le annotazioni invece non richiedono file esterni (da aggiornare) né di scrivere molto. Questo può avere ripercussioni favorevoli sulla manutenibilità del codice. Gli esempi che seguiranno prevedono l'uso delle annotazioni.
Scelta dell'RDBMS, dell'ORM e set di librerie minimali
Abbiamo visto che JPA richiede un database relazionale e un framework che implementi la specifica. Strumenti avanzati come gli application server mettono a disposizione le librerie necessarie, ad esempio JBoss AS mette a disposizione Hibernate per implementare la specifica JPA e un embedded database, Hypersonic DB, per memorizzare i dati.
Negli esempi che seguiranno vedremo come realizzare applicazioni standalone utilizzando come database l'HSQLDB (HyperSQL DataBase), scelto in considerazione dei tempi minimi richiesti per la messa in esercizio (per i primi passi fare riferimento all'articolo citato nella sezione Precondizioni), e sull'ORM Hibernate.
Nell'articolo si utilizzano le versioni 2.2.9 di HSQLDB e 4.2.0 di Hibernate. Se non lo abbiamo ancora fatto, è possibile effettuare il download di Hibernate (versione 4.2.0 o successiva stabile).
Nel progetto (un semplice progetto Java, possiamo chiamarlo EsempioJPA) occorrerà importare i driver JDBC di HSQLDB e le librerie dell'ORM che contengono le annotazioni e quelle che contengono il set di classi necessarie per il mapping a runtime. I driver JDBC, hsqldb.jar, si trovano nella cartella hsqldb/lib.
Da Hibernate occorrerà invece importare le seguenti librerie:
dist/lib/optional/hibernate-entitymanager-4.1.9.Final.jar
dist/lib/provided/jta-1.1.jar
dist/lib/provided/hibernate-jpa-2.0-api-1.0.1.Final.jar
dist/lib/required/jboss-logging-3.1.0.GA.jar
dist/lib/required/javassist-3.12.1.GA.jar
dist/lib/required/antlr-2.7.7.jar
dist/lib/required/hibernate-core-4.1.9.Final.jar
dist/lib/required/hibernate-commons-annotations-4.0.1.Final.jar
dist/lib/required/dom4j-1.6.1.jarQueste sono le librerie da importare nel Java Build Path. La notizia cattiva è che al cambiare della versione niente ci assicura che le librerie da importare resteranno le stesse, anzi è probabile che cambieranno. Come comportarsi allora nel caso si disponga di un'altra versione di Hibernate? Fondamentalmente vi sono tre approcci:
- consultare Internet per trovare una lista (corretta) delle librerie da importare per la propria versione;
- importare tutti i jar nel progetto
- ci si arma di pazienza e si aggiungono le librerie risalendovi dai mesaggi di errore ed eventualmente controllando su Internet quali sono le librerie contenenti le classi necessarie. È un procedimento sicuramento più lento del secondo, ma permette di contenere le dimensioni del progetto.
Un approccio utile per non dover importare ogni singolo jar ogni volta che si inizia un nuovo progetto è quello di costituire una collezione di librerie. Nell'Ide Eclipse è possibile dal menu
Window/Preferences Java/Build Path/User Libraries: New
Inserire un nome e successivamente aggiungere (Add JARs...
Più in generale, è sufficiente realizzare una cartella dove copiare i jar individuati, per poi importarla nel progetto e aggiungere i jar facendo riferimento direttamente alla cartella nel progetto.
Il file persistence.xml
Il file persistence.xml va inserito in una cartella denominata META-INF, posta nella cartella src. Questo file è un file di configurazione standard. Il suo scopo è fornire all'EntityManager le informazioni necessarie a salvare/aggiornare/interrogare il database e configurare lo strato di mapping.
Il file definisce le persistence-units, raggruppamenti di classi persistenti con le relative impostazioni, fornendo loro un identificativo univoco utilizzabile dall'applicazione. Si parla al plurale in quanto è possibile utilizzare diverse persistence-units per una singola applicazione.
Parametri del file sono le properties necessarie per la connessione al database (username, password e url), i driver utilizzati, il tipo di transazione (come abbiamo già visto "RESOURCE_LOCAL" o "JTA").
Il file che segue è quello che utilizzeremo per la connessione a HSQLDB. Assumeremo che il database sia avviato esternamente in modalità server. L'alias del database con il quale avviene la connessione è testdb1.
persistence.xml
<persistence xmlns="http://java.sun.com/xml/ns/persistence"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence" version="2.0">
<persistence-unit name="testhsqldb" transaction-type="RESOURCE_LOCAL">
<properties>
<property name="hibernate.dialect" value="org.hibernate.dialect.HSQLDialect"/>
<property name="hibernate.hbm2ddl.auto" value="update"/>
<property name="hibernate.connection.driver_class" value="org.hsqldb.jdbcDriver"/>
<property name="hibernate.connection.username" value="sa"/>
<property name="hibernate.connection.password" value=" "/>
<property name="hibernate.connection.url" value="jdbc:hsqldb:hsql://localhost/testdb1"/>
</properties>
</persistence-unit>
</persistence>Come si vede non viene specificata nessuna classe da rendere persistente. Alcune implementazioni della specifica come Hibernate effettuano di default la registrazione automatica delle classi nel file persistence.xml. La caratteristica non è JPA compliant (e pertanto non portabile tra implementazioni diverse di JPA), ma anche in Java SE è possibile utilizzare l'auto-detection, con la proprietà hibernate.archive.autodetection
Come esempi verranno portate le classiche operazioni di persistenza CRUD (create, read, update, delete), e un'entità da utilizzare come banco di prova. Il POJO di partenza è la classe Auto
Auto Autopackage Test;
import java.util.ArrayList;
import javax.persistence.Entity;
import javax.persistence.Id;
@Entity
public class Auto
{
@Id
private String matricola;
private String modello;
private String marca;
private int annoImmatricolazione;
private ArrayList<String> accessori;
public Auto(){}
public String getMatricola() { return matricola; }
public void setMatricola(String matricola) { this.matricola = matricola; }
public String getModello() { return modello; }
public void setModello(String modello) { this.modello = modello; }
public String getMarca() { return marca; }
public void setMarca(String marca) { this.marca = marca; }
public int getAnnoImmatricolazione() { return annoImmatricolazione; }
public void setAnnoImmatricolazione(int annoImmatricolazione) { this.annoImmatricolazione = annoImmatricolazione; }
public ArrayList<String> getAccessori() { return accessori; }
public void setAccessori(ArrayList<String> accessori) { this.accessori = accessori; }
public String toString(){
return "* Matricola: "+ getMatricola() +
" - Modello: " + getModello() +
" - Marca: " + getMarca() +
" - Anno di immatricolazione: " +
getAnnoImmatricolazione() +
"nAccessori: " + getAccessori();
}
}La tabella corrispondente, AUTO
accessori
Auto
Segue la classe destinata a realizzare le operazioni CRUD, LogicaJPA
package Test;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
import javax.persistence.Query;
public class LogicaJPA
{
private EntityManagerFactory emf;
private EntityManager em;
public LogicaJPA(String persistenceUnitName) {
emf = Persistence.createEntityManagerFactory(persistenceUnitName);
em = emf.createEntityManager();
}
public void jpaCreate(Object obj) {
em.getTransaction().begin();
em.persist(obj);
em.getTransaction().commit();
em.detach(obj);
}
public Query jpaRead(String query) {
Query q = em.createQuery(query);
return q;
}
public void jpaUpdate(Object obj) {
em.getTransaction().begin();
em.merge(obj);
em.getTransaction().commit();
em.detach(obj);
}
public void jpaDelete(Object obj) {
em.getTransaction().begin();
Object managed = em.merge(obj);
em.remove(managed);
em.getTransaction().commit();
}
public void closeLogicaJPA() {
em.close();
emf.close();
}
}Da notare che la classe contenente le operazioni CRUD è agnostica rispetto al tipo degli oggetti passati, così da agevolarne la riusabilità. Al costruttore viene passato il nome dell'unità di persistenza contenente le informazioni necessarie alla connessione con il database.
Per ognuna delle operazioni CRUD è presente un metodo generico. Osservare che, posponendo il metodo detach()
Managed
Annotazioni
Nella classe Auto è presente un set minimale di annotazioni, altre annotazioni permettono di modificare il comportamento standard. In questo paragrafo se ne descrivono alcune.
Per mappare l'entità su una tabella dal nome differente rispetto all'entità è possibile far seguire all'annotazione @Entity l'annotazione @Table(name="TableName")
È possibile impostare una strategia automatica di creazione della chiave facendo seguire all'annotazione @Id l'annotazione @GeneratedValue(strategy = GenerationType.AUTO)
Se la chiave primaria è composita, sarà sufficiente preporre l'annotazione @Id a ogni attributo che compone la chiave.
Così come è possibile customizzare il nome della tabella, è possibile farlo per ogni singolo campo. Inoltre sarà possibile specificare altre informazioni. Segue un esempio in cui si indica il nome, la lunghezza (si ipotizza l'attributo sia una stringa) e infine si indica che il corrispondente valore nella tupla non può essere nullo:
@Column(name="ColumnName", length=512, nullable = false)Un'altra annotazione utile è @Transient che consente di evitare che un attributo diventi persistente (non comparirà come campo della tabella).
Field-based access e Property-based access
La specifica JPA prevede per il persistence provider due modalità di accesso allo stato di un'entità:
- quando viene utilizzato l'accesso field-based
- viceversa usando l'accesso property-based
L'approccio field-based presenta alcuni vantaggi:
- solo i campi di interesse vengono esposti;
- lo stato è ben incapsulato;
- è possibile dichiarare metodi di get e set nelle interfacce o in classi astratte per poi effettuare l'override nelle classi concrete.
Lo svantaggio si presenta in fase di debugging in quanto non può avvenire tramite direct field injection
In questa parte dell'articolo realizziamo un main in cui poter testare le operazioni CRUD e verificare l'effetto che hanno sul database e sugli oggetti nella memoria Java. In particolare vedremo cosa succede allo stato degli oggetti.
Per tenere tutto sotto controllo lanciamo il Database Manager per le visualizzare le modifiche al database durante l'esecuzione del programma. Per avere il tempo di interrogare il Database Manager, aggiungiamo al codice seguente alcune "pause".
package Test;
import java.util.ArrayList;
import java.util.List;
import java.util.Scanner;
public class Main
{
public static void main(String[] args) {
LogicaJPA logJPA = new LogicaJPA("testhsqldb");
Auto auto1 = new Auto();
auto1.setMatricola("111");
auto1.setModello("Polo");
auto1.setMarca("Golia");
auto1.setAnnoImmatricolazione(1914);
ArrayList<Auto> acc1 = new ArrayList<Auto>();
acc1.add("cambio");
acc1.add("volante");
acc1.add("freno");
auto1.setAccessori(acc1);
logJPA.jpaCreate(auto1);
Auto auto2 = new Auto();
auto2.setMatricola("313");
auto2.setModello("Smile");
auto2.setMarca("Golia");
auto2.setAnnoImmatricolazione(1864);
ArrayList<Auto> acc2 = new ArrayList<Auto>();
acc2.add("fari");
acc2.add("radiatore");
auto2.setAccessori(acc2);
logJPA.jpaCreate(auto2);
List<Auto> listaAuto1 = logJPA.jpaRead("select t from Auto " + "t").getResultList();
System.out.println("nnInizializzaione, elenco auto " + "nel database:");
for(int i=0;i<listaAuto1.size();i++){
System.out.println(listaAuto1.get(i).toString());
}
...Nella prima parte del main creiamo un EntityManager
read
listaAuto1
...
auto1.setAnnoImmatricolazione(9999);
auto2.setAnnoImmatricolazione(1813);
auto2.getAccessori().add("targa");
List<Auto> listaAuto2 = logJPA.jpaRead("select t from Auto t").getResultList();
System.out.println("nnModifiche senza update, elenco auto nel database:");
for(int i=0;i<listaAuto2.size();i++){
System.out.println(listaAuto2.get(i).toString());
}
...Il passo successivo consistite nell'effettuare modifiche agli oggetti e verificare tramite una read
Detached
...
Auto auto3 = new Auto();
auto3.setMatricola("120");
auto3.setModello("ActivePlus");
auto3.setMarca("Golia");
auto3.setAnnoImmatricolazione(1980);
ArrayList acc3 = new ArrayList<String>();
acc3.add("tettuccio");
acc3.add("specchietto");
auto3.setAccessori(acc3);
logJPA.jpaCreate(auto3);
List<Auto> listaAuto3 = logJPA.jpaRead("select t from Auto t").getResultList();
System.out.println("nnNuovo ingresso, elenco auto nel database:");
for(int i=0;i<listaAuto3.size();i++){
System.out.println(listaAuto3.get(i).toString());
}
System.out.println("nnElenco vecchio auto nel database:");
for(int i=0;i<listaAuto1.size();i++){
System.out.println(listaAuto1.get(i).toString());
}
...Un nuovo oggetto viene istanziato e reso persistente. L'operazione implica un commit
commit
Detached
Viene anche effettuata una stampa a video della prima lista realizzata (listaAuto1
listaAuto3
...
auto2.setAnnoImmatricolazione(313);
auto2.getAccessori().add("tettuccio");
logJPA.jpaUpdate(auto2);
List<Auto> listaAuto4 = logJPA.jpaRead("select t from Auto t").getResultList();
System.out.println("nnModifiche con update, elenco auto nel database:");
for(int i=0;i<listaAuto4.size();i++){
System.out.println(listaAuto4.get(i).toString());
}
System.out.println("nnElenco vecchio auto nel database:");
for(int i=0;i<listaAuto1.size();i++){
System.out.println(listaAuto1.get(i).toString());
}
...Vengono nuovamente effettuate delle modifiche su un oggetto Detached
update
read
listaAuto4
...
auto2.setAnnoImmatricolazione(1999);
auto2.getAccessori().add("Paperino");
logJPA.jpaDelete(auto3);
List<Auto> listaAuto5 = logJPA.jpaRead("select t from Auto t").getResultList();
System.out.println("nnModifiche senza update e delete, " + "elenco auto nel database:");
for(int i=0;i<listaAuto5.size();i++){
System.out.println(listaAuto5.get(i).toString());
}
System.out.println("nnElenco vecchio auto nel database:");
for(int i=0;i<listaAuto1.size();i++){
System.out.println(listaAuto1.get(i).toString());
}
logJPA.closeLogicaJPA();
}
}Le ultime operazioni prevedono nuovamente una modifica di un oggetto Detached
update
Segue l'operazione delete
delete
listaAuto1
listaAuto5
delete
Removed
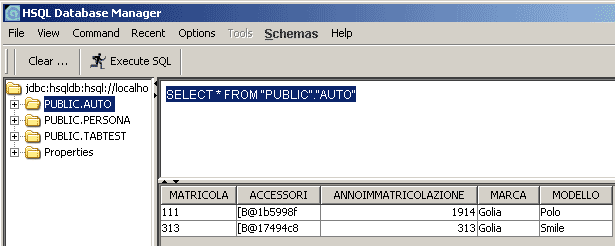
Accedendo al Database Manager sarà possibile confrontare il risultato atteso con quanto reso effettivamente persistente. Come è possibile vedere nella seguente immagine, al termine del programma di test avremo memorizzato nel database le due tuple riferite agli oggetti presenti nelle ultime liste stampate a video, memorizzate in una tabella creata automaticamente. Osservare che il campo “ACCESSORI” è trattato come un valore binario.
Una vista del database al termine del main
Prima di eseguire nuovamente il main di questo esempio occorrerà rimuovere dal database gli oggetti resi persistenti, in quanto si utilizzerebbe la stessa chiave primaria (Matricola). In alternativa, è possibile cambiare la matricola fornita con il metodo setMatricola.
Ulteriori prove
La classe realizzata, LogicaJPA, è stata pensata per rendere gli oggetti Detached subito dopo che vengono resi persistenti o aggiornati. In alternativa è possibile realizzare una classe LogicaJPAManaged che non preveda il metodo detach. In questo caso il risultato è quello di mantenere gli oggetti resi persistenti nello stato Managed, conseguentemente l'EntityManager terrà traccia nella cache di ogni modifica e la propagherà automaticamente al database alla prima invocazione del commit o alla sua chiusura.
Merge
Analogamente, altro aspetto da approfondire riguarda il metodo di merge. Abbiamo detto che questo metodo porta un oggetto allo stato Managed. Ciò però non implica in automatico la sincronizzazione con il database.
È possibile infatti fare un test in cui alla classe LogicaJPA vengono rimossi i metodi di start e begin transaction dal metodo di update. Ciò avrà un effetto singolare. All'operazione di read la query restituirà l'oggetto come se fosse stato effettivamente aggiornato. Se successivamente chiudiamo/svuotiamo l'EntityManager o invochiamo un commit per altre ragioni (ad esempio un'operazione di delete), e apriamo il Database Manager per interrogarlo circa lo stato degli oggetti, ci sarà restituita una tupla correttamente aggiornata.
Dov'è allora il problema? Il problema sorge nel momento in cui si effettua un accesso al database esternamente all'EntityManager, ad esempio dal Database Manager, prima che su di esso venga invocato un commit o venga chiuso o svuotato. È possibile ricreare questa situazione invocando un aggiornamento (senza commit) e mettendo il programma in pausa, per poi interrogare il Database Manager effettuando una query sulla tabella "AUTO".
In questo caso si vedrà che il Database Manager restituisce risultati non aggiornati. Al contempo però un'operazione di read sull'EntityManager restituisce i risultati aggiornati.
Ciò che accade è che l'EntityManager restituisce i risultati prelevandoli dalla cache, non direttamente dal database. E, poiché il merge da solo non sincronizza cache e database, interrogando il Database Manager questo restituirà invece i dati effettivi del database, database che non è stato ancora aggiornato e che non conosce il contenuto intermedio della cache. Da cui il disallineamento.
Conclusioni
Abbiamo esaminato alcune caratteristiche della specifica JPA 2.0 per l'accesso, la persistenza e la gestione dei dati tra oggetti Java e database relazionali.
Ci siamo limitati a descrivere i meccanismi di base come entità, cache e il meccanismo degli stati. Infine abbiamo esaminato esempio di progetto reale per comprendere meglio il rapporto tra stato dell'oggetto, cache e database.
Abbiamo posto le basi per approfondire altri aspetti come le relazioni tra entità, classi Embeddable, tool a supporto dello sviluppo di applicazioni che utilizzano JPA e così via.

