
Tutti i moderni RDBMS (Relational Database Management System) prevedono la creazione di indici su tabelle (e talvolta anche su viste di tabelle) per velocizzare le interrogazioni. In questo articolo analizzeremo l'architettura degli indici adottati da MS-SQL Server 2005 passandone in rassegna i diversi tipi. L'articolo non intende suggerire linee guida per l'ottimizzazione degli indici, ma fornisce, altresì, le conoscenze basilari per comprendere alcune delle più comuni e diffuse best practices in tema ottimizzazione.
SQL Server 2005 implementa gli indici con la struttura B+Tree, standard de facto nel panorama dei database relazionali. Quando si parla di indici, il pensiero va naturalmente all'indice dei libri, grazie ai quali siamo in grado di "saltare" a una determinata pagina da cui inizia un certo capitolo o paragrafo, oppure ai glossari spesso presenti alla fine dei libri, con i quali si è in grado di "saltare" a tutte le pagine che contengono una determinata parola.
Va subito precisato che un indice B+Tree non ha nulla a che vedere con questi indici a noi tanto comuni, se non il fatto che velocizzano la ricerca della parola cercata. Essi, infatti, rappresentano indici a un solo livello (al più ordinati come nel caso del glossario), condizione per cui permettono una ricerca di tipo sequenziale dalla prima all'ultima voce, o di tipo binario secondo il noto algoritmo omonimo che ripartisce in due, di volta in volta, l'elenco ordinato di voci da confrontare con la voce cercata.
Gli indici B+Tree sono, invece, multi-livello e sono basati sulla struttura dati nota col nome di "albero binario di ricerca bilanciato", rappresentato come un insieme di nodi, dove da ognuno di essi partono sempre due "frecce" che giungono ognuna ad un altro nodo, mentre una sola freccia giunge al singolo nodo. Fanno eccezione il nodo radice, a cui non giunge alcuna freccia, e i nodi foglia dell'albero da cui non partone frecce. Una freccia rappresenta un puntatore e quindi un legame tra un nodo e l'altro, che di fatto permette la navigazione dell'indice riducendo drasticamente il numero massimo di confronti per giungere alla voce cercata in elenco.
In un indice B+Tree, ogni nodo che non sia foglia, rappresenta un blocco (o pagina) di dati (ovvero l'allocazione minima di memoria su disco) contenente alcune voci indicizzate in ordine alfabetico, dove a ciascuna voce è associato un puntatore a un nodo di livello inferiore. Al livello foglia troviamo, invece, tutte le voci indicizzate in ordine alfabetico, con associato un puntatore al blocco di disco che contiene l'intera riga di tabella.
Gli indici e la Heap memory di MS-SQL Server 2005
Per gestire gli indici di MS-SQL Server 2005 è possibile utilizzare sia l'interfaccia grafica "SQL Server Management Studio", che il linguaggio DDL (Data Definition Language) del Transact-SQL. Per ovvi motivi legati alla migliore comprensibilità dell'articolo e maggiore riusabilità, ho optato per il T-SQL.
In SQL Server è possibile avere due tipi di indici molto diversi tra loro: Clustered e Non-Clustered. Poi, indipendentemente dal tipo, un indice può essere alternativamente Unique oppure Non-Unique. Una tabella può avere fino a 249 indici Non-Clustered, ma un solo indice Clustered. Il perché di questo sarà evidente quando ne analizzeremo le struttura.
Iniziamo col considerare che non è detto che una tabella sia per forza provvista di indici. In questo caso, le righe della tabella sono allocate in una cosiddetta Heap memory, costituita da pagine di dati, ciascuna di dimensione paria a 8 Kb. La Heap di una tabella, contiene le righe della tabella senza alcun particolare ordine (da cui la parola Heap = confusa/disordinata) e SQL Server si limiterà ad effettuare una Table Scan, ovvero una ricerca sequenziale mediante scansione di tutte le pagine della tabella, ogni qual volta venisse lanciata una query di selezione piuttosto che di modifica o cancellazione sulla tabella.
Indici Non-Clustered
Per creare un indice su una o più colonne di tabella insieme, si può lanciare l'istruzione T-SQL:
CREATE INDEX NomeIndice
ON NomeTabella (NomeColonna1, ..., NomeColonnaN)
Questa istruzione costruirà un indice di tipo Non-Clustered basato su un insieme di colonne di tabella in ordine crescente, che si tradurrà nell'allocazione di un certo numero di pagine di dati nei file di dati del database. SQL Server popolerà queste pagine di dati dell'indice con i valori delle colonne indicizzate costruendo una struttura B+Tree come quella introdotta all'inizio dell'articolo. In particolare, le pagine del livello foglia conterranno i valori ordinati con associato un puntatore (PAGE:ROWID) alla Heap, con il quale il motore di database potrà saltare alla specifica riga della specifica pagina di dati contenente l'intera riga di tabella cercata.

Per l'esattezza, la natura del puntatore dipende dalla presenza o meno dell'indice Clustered della tabella. In assenza di esso, il puntatore sarà quello presentato poc'anzi, in caso contrario sarà il valore delle colonne dell'indice Clustered.
Indici Clustered
Un indice Clustered differisce da uno Non-Clustered nella struttura delle pagine del livello foglia, in quanto in esse presenta i dati dell'intera riga.
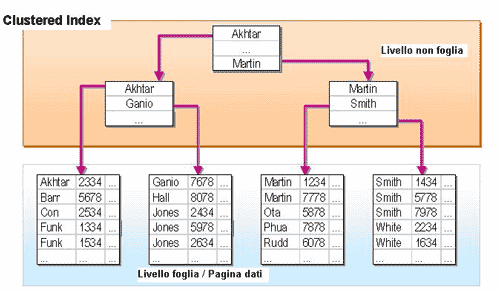
In altre parole, il livello foglia di un indice Clustered tiene ordinate le righe di una tabella in base alle colonne indicizzate. Inoltre, nel momento in cui viene creato l'indice Clustered della tabella, SQL Server provvede a eliminare la Heap, di fatto adesso ridondante e sostituita proprio dalle pagine ordinate del livello foglia dell'indice Clustered. Ecco l'istruzione T-SQL per creare un indice Clustered:
CREATE CLUSTERED INDEX NomeIndice
ON NomeTabella (NomeColonna1, ..., NomeColonnaN)
Unique
L'attributo Unique serve a rafforzare il vincolo di univocità delle colonne che fanno parte dell'indice. Da notare che il vincolo di Primary Key viene implementato proprio attraverso un indice Unique di tipo Clustered, sempre che non sia già presente, altrimenti sarà Non-Clustered. Se Non-Clustered l'istruzione è:
CREATE UNIQUE NONCLUSTERED INDEX NomeIndice
ON NomeTabella (NomeColonna1, .... NomeColonnaN])
Se Clustered:
CREATE UNIQUE CLUSTERED INDEX NomeIndice
ON NomeTabella (NomeColonna1, .... NomeColonnaN])
Covering Indexes
Vediamo adesso in che modo SQL Server va alla ricerca di una riga navigando un indice Non-Clustered in presenza anche dell'indice Clustered. Supponiamo di creare una tabella
[Contatti]
così strutturata:
CREATE TABLE [dbo].[Contatti]
(
[Id] int IDENTITY (1, 1) PRIMARY KEY NOT NULL,
[Cognome] VARCHAR(50) NOT NULL,
[Nome] VARCHAR(50) NOT NULL,
[Telefono] VARCHAR(20) NULL,
[Email] VARCHAR(50) NULL
)
La definizione del vincolo Primary Key avrà generato implicitamente un indice Unique di tipo Clustered sulla colonna [Id]. Inoltre, per aiutare le query di selezione che ricercano per numero di telefono, decidiamo di creare un altro indice sulla colonna [Telefono]:
CREATE NONCLUSTERED INDEX [IX_Telefono]
ON [dbo].[Contatti] ([Telefono])
Una query di selezione come la seguente
SELECT [Cognome], [Nome]
FROM [dbo].[Contatti]
WHERE [Telefono] = @Telefono
potrebbe far scegliere a SQL Server di utilizzare l'indice Non-Clustered. In tal caso, l'indice [IX_Telefono] sarà navigato fino al suo livello foglia, finché raggiungerà la voce del numero di telefono cercato. A questo punto, poiché la SELECT intende estrarre valori di [Nome] e [Cognome] corrispondenti al numero di telefono trovato nell'indice, SQL Server inizierà a navigare l'indice Clustered alla ricerca del valore [Id] reperito nel livello foglia dell'indice Non-Clustered.
In definitiva, la nostra
SELECT
avrà prodotto due attraversamenti di indice, prima il Non-Clustered e poi il Clustered. Quando il motore di database riesce ad evitare il secondo attraversamento limitandosi a quello dell'indice Non-Clustered si è in presenza di un Covering Index. Questo accade in virtù del fatto che le colonne indicizzate, o meglio le colonne contenute nel livello foglia dell'indice Non-Clustered, riescono a coprire interamente la query.
Nel nostro caso una query coperta interamente dall'indice [IX_Telefono] è la seguente:
SELECT [Id]
FROM [dbo].[Contatti]
WHERE [Telefono] = @Telefono
Dunque, se volessi "coprire" con un indice la query
SELECT [Cognome], [Nome]
FROM [dbo].[Contatti]
WHERE [Telefono] = @Telefono
dovrei creare l'indice:
CREATE NONCLUSTERED INDEX [IX_Telefono_Cognome_Nome]
ON [dbo].[Contatti] ([Telefono], [Cognome], [Nome])
oppure, per non appesantire molto l'indice, potrei usare (ma questo vale solo con la versione 2005) l'opzione INCLUDE che determina l'introduzione nel solo livello foglia dell'indice, di ulteriori colonne. Nel nostro caso:
CREATE NONCLUSTERED INDEX [IX_Telefono_Include_Cognome_Nome]
ON [dbo].[Contatti] ([Telefono]) INCLUDE ([Cognome], [Nome])
Frammentazione
Passiamo ora a dare uno sguardo più da vicino alle pagine dati di un indice. Come già detto, un indice è costituito da pagine di 8Kb organizzate in una strutturata B+Tree. Nel corso della vita di una tabella, i suoi indici subiranno le sorti dei dati della tabella, quindi SQL Server provvederò a tenere aggiornati gli indici della tabella ad ogni modifica intervenuta sui dati. Di conseguenza potrà generarsi una frammentazione dell'indice.
In particolare, per un indice si parla di due tipi di frammentazione: esterna e interna. Quella esterna si ha in presenza di bassa contiguità delle pagine dell'indice, mentre quella interna si riferisce a un basso tasso di riempimento delle singole pagine. Entrambe sono causa di degrado delle prestazioni dell'indice. Si po' intervenire con la deframmentazione di un indice in due modi diversi.
Per la deframmentazione interna, mediante le istruzioni alternative:
-- ipotesi 1
ALTER INDEX NomeIndice ON NomeTabella REORGANIZE (valida solo con la versione 2005)
-- ipotesi 2
DBCC INDEXDEFRAG ('NomeDatabase', 'NomeTabella', 'NomeIndice')
Per la deframmentazione esterna, si può scegliere tra:
-- ipotesi 1
ALTER INDEX NomeIndice ON NomeTabella REBUILD (valida solo con la versione 2005)
-- ipotesi 2
DBCC DBREINDEX ('NomeTabella', 'NomeIndice')
-- ipotesi 3
CREATE INDEX NomeIndice ON NomeTabella (NomeColonna1, ..., NomeColonnaN)
WITH DROP_EXISTING
Conclusioni
Per rispondere a una interrogazione, l'Engine di SQL Server valuta la presenza e l'efficacia degli indici presenti sulle tabelle coinvolte nella query, quindi decide di operare una scansione di tabella (mediante l'operazione interna di TABLE SCAN o INDEX SCAN) oppure una ricerca mediante indice (INDEX SEARCH). Conoscere la natura e i tipi di indici a disposizione è fondamentale per progettare indici efficaci.
