
L'esempio che proponiamo riguarda la realizzazione di un piccolo database stile social network: abbiamo degli utenti che possono seguirsi l'un l'altro nelle loro attività (per semplicità non ci preoccuparemo della pubblicazione dei contenuti) e delle tematiche cui essi si interessano. Come detto nella lezione precedente, faremo riferimento al DBMS OrientDB.
Entità e classi
Decidiamo innanzitutto quali entità considerare nel nostro progetto. Ne prendiamo quattro, due per i vertici e due per gli archi:
- i nodi nel grafo saranno di due tipologie: gli utenti per i quali immagazzineremo semplicemente nome, cognome e data di nascita e gli interessi per i quali ci premerà ricordare solo la tematica che riguardano;
- gli archi definiranno relazioni di due tipi: la relazione che chiameremo "Segue" che collegherà un utente ai suoi follower, e la relazione "Studia" che collegherà gli utenti al nodo tematica cui sono interessati. Come si immagina, ognuno potrà essere appassionato di più argomenti e seguire più utenti; inoltre, chi è seguito da un altro non è obbligato a ricambiare tale attenzione.
Dopo la creazione del database in OrientDB, creiamo le quattro classi necessarie ad implementare le entità appena individuate, operazione che - come detto nella lezione precedente - si può svolgere comodamente con OrientDB Studio. È importante ricordare che, per un corretto uso nel grafo, le classi rappresenteranno i vertici (nel nostro caso, Utente e Interesse) dovranno essere discendenti di V, mentre quelle che rappresentano gli archi (nell'esempio, Segue e Studia) dovranno essere discendenti di E.
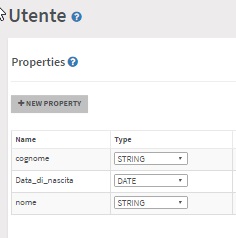
Una volta definite le classi, potremo iniziare a creare i record. Anche per questa operazione potremo seguire varie vie: visuale con Studio, utilizzando una serie di istruzioni INSERT via console, o tramite API offerte dai linguaggi di programmazione. In Studio troviamo, ad esempio, la sezione "Graph" che permette di lavorare esplicitamente sui grafi in maniera totalmente visuale:

Cliccando su un singolo vertice viene visualizzato un menu circolare che permette di modificare i dati, stabilire relazioni e svolgere ogni altra operazione utile.
Analisi di un grafo
Una volta definite le tipologie di oggetti che saranno coinvolti, dovremo analizzare via via il grafo in base ai nostri interessi. Nella guida a OrientDB, abbiamo parlato dei comandi che possono essere impartiti sui grafi: qui ne riepiloghiamo i tratti principali.
Per prima cosa, potremo utilizzare una sintassi SQL come la seguente per effettuare selezioni sulle classi:
SELECT nome, cognome FROM Utenteuna selezione del genere mostrerà tutti i nodi della classe Utente che abbiamo definito appositamente per il nostro esempio. Potremo svolgere la medesima operazione con la classe Interesse, ma ciò che è più importante notare è che il linguaggio SQL di OrientDB supporta anche l'ereditarietà. Pertanto, il comando seguente:
SELECT * FROM Vmostrerà tutti gli oggetti di classe derivata da V, quindi sia quelli di classe Utente sia qualli di classe Interesse.
Vediamo ora come studiare le connessioni tra i nodi. La seguente query, ad esempio, mostrerà gli archi uscenti dai nodi distinguendoli tra quelli di tipo Segue e quelli di classe Studia:
SELECT @RID,out_Segue, out_Studia FROM UtenteIl risultato sarà analogo al seguente:
|RID |out_Segue |out_Studia |
+-----+-----+-------------+--------
|#12:0|[#14:0,#14:5]|[#15:0,#15:1] |Possiamo notare che sono presenti diversi id di oggetti (li riconosciamo perchè iniziano con il simbolo #), tra cui il RID che identifica un nodo e gli altri che si riferiscono agli archi che da questo si dipartono. Notare che in caso di più archi uscenti, la loro sequenza sarà racchiusa tra parentesi quadre (indicando un array). Utilizzando invece la funzione out() i collegamenti verranno derefenziati e saranno mostrati direttamente i nodi raggiunti tramite gli archi. Osserviamo il seguente esempio:
SELECT out("Segue") FROM Utente WHERE @RID='#12:6'Verranno mostrate le destinazioni degli archi uscenti, di tipo Segue, a partire dal nodo con RID #12:6. Nel nostro esempio, verrà recuperato solamente un nodo, quello con RID #12:3 (i dati delle altre proprietà si potranno ottenere con il metodo expand()):
+----+-------+
|# |out |
+----+-------+
|0 |[#12:3]|
+----+-------+Una problematica importante riguarda l'attraversamento del grafo. Il seguente comando:
TRAVERSE * FROM #12:3percorre il grafo, visitandolo in profondità (almeno che non specifichiamo diversamente), a partire dal nodo #12:3. Vedremo scorrere tutti i nodi e archi incontrati durante il percorso, completi dei dati delle proprietà che li caratterizzano. La documentazione spiega subito che tale comando è stato creato appositamente per svolgere principalmente operazione sui grafi in una maniera molto più veloce rispetto a qualsiasi JOIN su tabelle relazionali. Per evitare la restituzione di troppi dati, TRAVERSE ha un limite di 20 oggetti da mostrare ma questo, all'occorrenza, può facilmente essere superato applicando la clausola LIMIT:
TRAVERSE * FROM #12:3 LIMIT 30Il comando TRAVERSE può essere combinato con SELECT per poterne estrapolare con chiarezza i dati. L'istruzione:
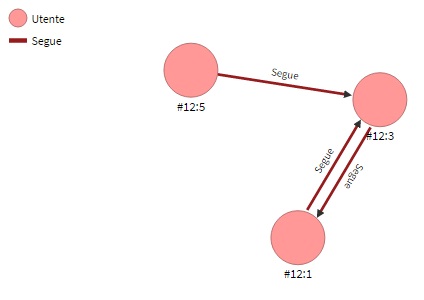
SELECT @RID, nome, cognome FROM (TRAVERSE out("Segue") from #12:5)analizza i collegamenti out di tipo Segue a partire dal nodo #12:5, per vedere a quali nodi portano. Questo il risultato:
+----+-----+--------+-------+
|# |RID |nome |cognome|
+----+-----+--------+-------+
|0 |#12:5|Enzo |Neri |
|1 |#12:3|Vittorio|Verdi |
|2 |#12:1|Roberto |Bianchi|
+----+-----+--------+-------+Il primo nodo rilevato è lo stesso #12:5 e gli altri sono, correttamente, quelli raggiungibili a partire da esso. Infatti, dal #12:5 si può arrivare al #12:3 e da questo al #12:1.
Per affinare la ricerca si possono richiedere nodi di profondità superiore a 1 in modo da escludere non solo il nodo di partenza, ma anche i discendenti diretti:
SELECT @RID, nome, cognome FROM (TRAVERSE out("Segue") from #12:5) WHERE $depth>1In questo modo, si potrebbe applicare un abbozzo di meccanismo per trovare gli "amici degli amici" in una rete social: in pratica, Enzo Neri segue Vittorio Verdi che a sua volta è seguito da Roberto Bianchi; quindi, anche i contenuti pubblicati da quest'ultimo potrebbero essere di interesse di Enzo Neri. Un'altra applicazione di questo meccanismo può essere quella di suggerire agli utenti ulteriori possibili follower.
Conclusioni
In conclusione, i database a grafo offrono possibilità di analisi per giunta superiori alle altre tecnologie NoSQL, non tanto per capacità loro quanto per il modo che hanno di stabilire collegamenti: risultati simili non sarebbero impossibili altrimenti, ma il loro trattamento avrebbe indubbiamente costi superiori in termini di prestazioni. Un database a grafo è molto performante soprattutto nei casi in cui vengono a formarsi grovigli di relazioni non associabili ad altre strutture dati, ed un DBMS come OrientDB può fare leva sulla sua essenza multi-model per poter gestire a grafo solo ciò che lo richiede, utilizzando ad esempio il modello a documenti per il resto dei contenuti.
