
Nella prima parte di questa guida, abbiamo parlato principalmente di HDFS e di come esso fornisce le funzionalità di accesso ai dati, ma le elaborazioni degli stessi avvengono attraverso la componente MapReduce che viene definito come il cuore del sistema di calcolo distribuito di Hadoop.
MapReduce è un framework per la creazione di applicazioni in grado di elaborare grandi quantità di dati in parallelo basandosi sul concetto di functional programming. A differenza della programmazione multithreading, in cui i thread condividono i dati oggetto delle elaborazioni presentando così una certa complessità proprio nel coordinare l'accesso alle risorse condivise, nel functional programming, invece, la condivisione dei dati è eliminata, e questi sono passati tra le funzioni come parametri o valori di ritorno.
MapReduce lavora secondo il principio del divide et impera, suddividendo l'operazione di calcolo in diverse parti processate in modo autonomo. Una volta che ciascuna parte del problema è stata calcolata, i vari risultati parziali sono "ridotti" (cioè ricomposti) a un unico risultato finale. È MapReduce stesso che si occupa dell'esecuzione dei vari task di calcolo, del loro monitoraggio e della ripetizione dell'esecuzione in caso si verifichino problemi.
Il framework lavora attraverso i compute node cioè dei nodi di calcolo che si trovano assieme ai DataNode di HDFS: infatti, lavorando in congiunzione con HDFS, MapReduce può eseguire i task di calcolo sui nodi dove i dati sono già presenti, aumentando così l'efficienza di calcolo.
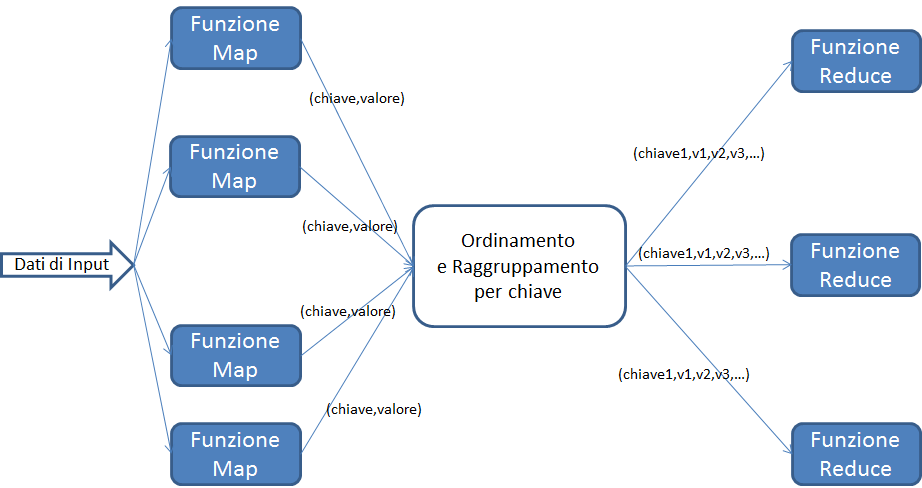
Fondamentalmente, un job MapReduce è costituito da 4 componenti:
- i dati di input, su HDFS;
- una funzione map, che trasforma i dati di input in una serie di coppie chiave/valore;
- una funzione reduce che, per ogni chiave, elabora i valori ad essa associati e crea, come output, una o più coppie chiave valore. L'esecuzione della funzione reduce è preceduta da una fase di raccolta delle coppie chiave/valore prodotte dalla funzione map. Le coppie sono ordinate per chiave e i valori con la stessa chiave sono raggruppati;
- l'output, scritto su un file HDFS.
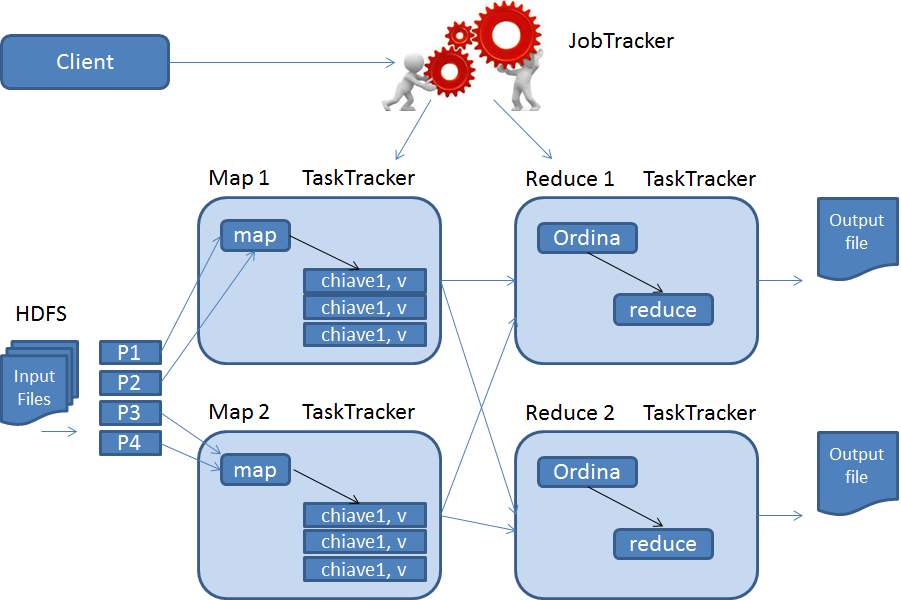
La prima versione di MapReduce (attualmente MapReduce è arrivato alla numero 2), a livello architetturale, presenta due componenti:
| Componente | Descrizione |
|---|---|
| Job Tracker | E la componente che si occupa della gestione delle risorse (CPU e memoria) e del ciclo di vita del job MapReduce. Il JobTracker distribuisce il lavoro utilizzando una politica concettualmente semplice: privilegia i nodi più vicini che contengono i dati da elaborare; nel caso in cui un nodo non possa ospitare il task, JobTracker si fa poi carico della schedulazione del job nonché della ripetizione dell'esecuzione dei singoli task di MapReduce che si trovano in uno stato di errore. |
| Task Tracker | Sono le componenti che girano sui singoli nodi e che eseguono effettivamente i task sotto la direzione del JobTracker. |
Le applicazioni che sfruttano il framework MapReduce devono specificare gli input, i file di output, le funzioni map e reduce come implementazioni di interfacce o classi astratte Java. Il client Hadoop fornisce il job (sottoforma di archivio .jar) e le configurazioni al JobTracker il quale si occupa di distribuirli ai vari nodi per l'esecuzione. Il JobTracker determina il numero di parti in cui l'input deve essere distribuito e attiva alcuni TaskTracker in base alla loro vicinanza ai nodi che contengono i dati di interesse.
I TaskTracker estraggono poi i dati dalla parte di loro competenza e attivano la funzione map che produce coppie chiave/valore. Una volta terminata la fase di map, i TaskTracker notificano al JobTracker il completamento del loro lavoro. Il JobTracker può cosi attivare la fase di reduce, nella quale i TaskTracker ordinano i risultati dei mapper per chiave, li aggregano ed eseguono la funzione reduce al fine di produrre l'output, salvato in un file diverso per ciascun TaskTracker.
Scenari di utilizzo di Map-Reduce
È ormai chiaro che MapReduce si presta bene all'esecuzione di numerose operazioni sui dati. Data la varietà di operazioni che MapReduce può effettuare in modo efficiente, i potenziali utilizzi del framework sono moltissimi:
- Creazione di liste di parole da documenti di testo, indicizzazione e ricerca. Appartengono a questa categoria i seguenti esempi applicativi: conteggi, somme, estrazione di liste univoche di valori (ad esempio analisi dei log dei Web server) e applicazioni di filtri ai dati;
- analisi di strutture dati complesse, come grafi (ad esempio per applicazioni di social network analysis);
- data mining e machine learning;
- esecuzione di task distribuiti (come calcoli matematici complessi e analisi numeriche);
- correlazioni, operazioni di unione, intersezione, aggregazione e join (ad esempio analisi di mercato, analisi predittive e previsione dei trend).
Queste numerose applicazioni confermano la potenza informativa che è possibile estrarre con la Big Data analytics, grazie alla quale non ci si limita più ad una business intelligence orientata all'analisi dati strutturati per trarre conclusioni a posteriori. Grazie alla varietà dei dati che è possibile analizzare, all'enorme quantità che è possibile immagazzinare con le moderne tecnologie e allo stesso tempo alla velocità che non è più un limite nell'analisi di enormi moli di informazioni, si possono elaborare modelli di analisi che possono fornire predizioni e non limitarsi ad analisi descrittive.
Dopo aver introdotto il Map-Reduce, il prossimo capitolo sarà dedicato ad un approfondimento delle componenti più importanti per Hadoop.
