
Tra le applicazioni più difficili da realizzare, in ambito Flash, possiamo annoverare quelle basate su fonti di dati XML: Flash, anche nella versione 8, non presenta un parser di alto livello e, per quanto offra dei metodi e classi per analizzare i file in formato xml, non è certamente semplice ricavare correttamente i dati da fonti complesse, dovendosi districare tra nodi, attributi e tag.
In ActionScript 3 le cose sono cambiate notevolmente: è stato introdotto infatti il sistema di gestione XML E4X, che ci permetterà di analizzare i file in maniera molto più rapida e soprattutto più versatile.
Le specifiche ufficiali e dettagliate di questo sistema sono disponibili sul sito dell'Ecma international.
Chi fosse ormai abituato al "vecchio" sistema e non volesse cambiare radicalmente le sue abitudini, almeno nell'immediato, può comunque stare tranquillo: è stata mantenuta la retro-compatibilità con la vecchia classe XML.
In questo articolo creeremo un file XML e vedremo come E4X permetta di trovare, in maniera precisa e con poco codice, le informazioni di cui necessitiamo.
Creazione del file XML
Uno degli aspetti più importanti, di un file XML, è la corretta formattazione: esistono moltissimi XML che non hanno un nodo principale, o che sono creati con dei tag assolutamente poco intuitivi. Una delle maggiori comodità di XML è proprio la possibilità di utilizzare i propri tag in modo da identificare le informazioni in maniera dettagliata.
Se con la "vecchia" classe XML anche i file senza un nodo principale (o con un tag non chiuso) venivano comunque processati dal player, il nuovo sistema è molto più "severo" e ci informa; se la fonte di dati che stiamo tentando di analizzare è un documento ben formato oppure no.
Simuliamo un errore
Proviamo ad utilizzare un file con il tag principale non chiuso: creiamo un file prova_errore.xml, con questo contenuto:
Listato 1. Documento XML con tag principale non chiuso
<canale>
<tag>Html.it</tag>
<tag2>Flash</tag2>
Abbiamo volutamente omesso la chiusura del tag <canale>. Cerchiamo di leggere questo contenuto in un filmato creato con la Public Alpha di Flash 9 (l'unica versione di Flash dove sia attualmente utilizzabile ActionScript 3).
Listato 2. Leggere l'XML con AS3
import flash.net.URLLoader
import flash.net.URLRequest
import flash.xml.XML
import flash.event.*
import flash.error.*
var fileXML:XML;
var carica_file:URLLoader = new URLLoader();
carica_file.addEventListener(Event.COMPLETE, analizza);
carica_file.load(new URLRequest("esempio_errore.xml"));
function analizza(evt:Event)
{
try
{
fileXML = new XML(carica_file.data);
}
catch(errore:Error)
{
trace("Si è verificato un errore: " + errore.message);
return;
}
}
Questo codice importa le classi necessarie per caricare un file XML (URLLoader, URLRequest e XML) e per la gestione degli eventi (event.*) ed errori (error.*), quindi, imposta il caricamento del file, esempio_errore.xml, associando all'evento COMPLETE la funzione analizza (quando il file sarà stato caricato completamente verrà avviata la funzione analizza). Questa funzione tenta di caricare i dati del file, ma in caso di errore, mostra nel pannello output la dicitura "Si è verificato un errore", seguita dalle informazioni fornite dal player riguardo l'errore stesso.
Se testiamo il filmato vediamo che il player ci informa della mancanza del tag di chiusura </canale> all'interno del file che stiamo analizzando.
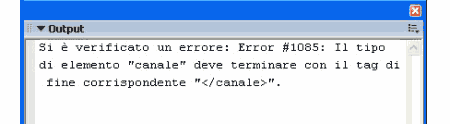
Grazie a questi controlli eseguiti dal player, siamo certi che il file che stiamo caricando è conforme allo standard XML e nel caso contenga errori, avremo indicazioni precise che ci aiuteranno a correggere i problemi riscontrati.
Creazione di un file XML valido
Il file esempio_errore.xml: contiene tag e tag2, che non descrivono in alcun modo il loro contenuto. Un buon file XML deve permetterci di avere, già dalla struttura, un'idea del contenuto e deve essere ben diviso per essere poi facilmente analizzabile. L'esempio tipico a riguardo sono i feed RSS, che offrono informazioni divise in gruppi di tag che poi i vari parser analizzano: se questi file non seguissero determinate regole e non fossero facilmente comprensibili, sarebbero praticamente inutilizzabili.
Prendiamo un feed RSS ben formattato, quello del forum Flash di HTML.it (se non visualizzate il codice guardate il sorgente della pagina); esaminandolo possiamo notare che è diviso in elementi (tag <item>) che contengono a loro volta informazioni quali: titolo, link al thread, autore e data di pubblicazione. Vi sono poi anche i tag "generici" di descrizione del feed, ad esempio: il titolo (Forum Flash di Html.it), la descrizione, il linguaggio, il copyright ed altre note.
Chiaramente, a seconda dell'utilizzo del file XML, decideremo che tipo di tag utilizzare e quali informazioni inserire.
Per esaminare le potenzialità di E4X creeremo un file piuttosto semplice, che conterrà diverse risorse per poter sperimentare come sia facile trovare quello che si cerca, anche in file dove sono presenti diversi tag con lo stesso nome.
Listato 3. Struttura del file XML utilizzato nell'esempio
<?xml version="1.0" encoding="iso-8859-1"?>
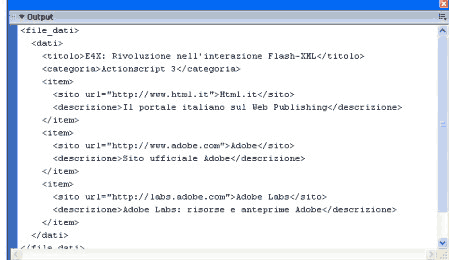
<file_dati>
<dati>
<titolo>E4X: Rivoluzione nell'interazione Flash-XML</titolo>
<categoria>ActionScript 3</categoria>
<item>
<sito url="http://www.html.it">Html.it</sito>
<descrizione>Il portale italiano sul Web Publishing</descrizione>
</item>
<item>
<sito url="http://www.adobe.com">Adobe</sito>
<descrizione>Sito ufficiale Adobe</descrizione>
</item>
<item>
<sito url="http://labs.adobe.com">Adobe Labs</sito>
<descrizione>Adobe Labs: risorse e anteprime Adobe</descrizione>
</item>
</dati>
</file_dati>
Il file contiene delle informazioni generiche (titolo e categoria) e poi tre diversi item, ognuno contenente sito (con attributo url) e descrizione.
E4X in azione
Per prima cosa inseriamo il codice necessario a caricare il file: possiamo riutilizzare quello già visto nella simulazione dell'errore all'interno del file XML.
Con questo codice importiamo tutti i dati all'interno dell'oggetto fileXML: questo conterrà tutta la struttura del file XML, infatti se utilizziamo il codice trace(fileXML), all'interno della funzione, otteniamo l'esatta struttura del documento.
Ora possiamo analizzare il file direttamente in ActionScript, utilizzando i tag come se fossero dei veri e propri "oggetti". Ad esempio, per accedere al testo contenuto nel tag <titolo>, possiamo utilizzare il codice fileXML.dati.titolo.text(), mentre per il tag categoria possiamo usare fileXML.dati.categoria.text(). Questi però sono tag univoci all'interno del nostro file XML: cosa succede se tentiamo di accedere ad un tag non unico? Proviamo a scrivere:
fileXML.dati.item.sito.text();
Otterremo come risultato Html.itAdobeAdobe Labs, questo perchè i tag <sito> all'interno dei tag <item> sono 3, per cui con il codice scritto sopra accediamo a tutti e non ad uno specifico. Per accedere ad un tag specifico dobbiamo utilizzare una dicitura di questo tipo:
fileXML.dati.item[0].sito.text();
Notiamo l'utilizzo di [0], che indica al codice di cercare solamente il primo tag <item>, il risultato in questo caso sarà Html.it, che è appunto il testo del tag <sito> del primo <item>; analogamente utilizzando le diciture item[1] e item[2] otterremo rispettivamente "Adobe" e "Adobe Labs" come risultati.
Utilizzare gli attributi
Nel nostro XML abbiamo inserito per ogni tag <sito> un attributo url. Gli attributi possono venire usati principalmente in due modi:
- Per ricavare un'informazione
- Per identificare un tag
Per esempio, potremmo voler conoscere il valore dell'attributo url del primo tag <sito>, ma potremmo anche voler conoscere il testo contenuto nel tag che abbia come url "http://www.html.it".
Ricavare il valore di un attributo
La sintassi per ricavare il valore di un attributo è simile a quella usata per i tag; ad esempio, per ottenere il valore dell'attributo url del tag <sito> contenuto nel primo tag <item>, basta utilizzare il codice:
fileXML.dati.item[0].sito.attributes()
Possiamo anche ottenere il nome dell'attributo, così:
fileXML.dati.item[0].sito.attributes().name()
Anche in questo caso vale il discorso fatto per i tag <item>, ovvero nel caso in cui ci trovassimo degli elementi con più di un attributo dovremmo identificarli numericamente, per esempio con fileXML.dati.item[0].sito.attributes()[0].name() analizzeremmo il nome del primo attributo del tag <sito> contenuto nel primo tag <item>.
Qualora conoscessimo il nome dell'attributo e ne volessimo ricavare direttamente il valore possiamo utilizzare anche questa sintassi:
fileXML..item[0].sito.@url
Utilizzare gli attributi per identificare un tag
L'altro uso più diffuso degli attributi è quello di "identificatori", in pratica vengono usati al posto della notazione numerica in modo da rendere più intuitiva la ricerca di una risorsa. Nel nostro esempio gli attributi url non sono particolarmente indicati, solitamente come identificatore viene utilizzato un attributo con valore numerico, in questo modo:
Listato 4. Esempio di xml con identificatori
<?xml version="1.0" encoding="iso-8859-1"?>
<file_dati>
<dati>
<titolo>E4X: Rivoluzione nell'interazione Flash-XML</titolo>
<categoria>ActionScript 3</categoria>
<item id="1" >
<sito url="http://www.html.it">Html.it</sito>
<descrizione>Il portale italiano sul Web Publishing</descrizione>
</item>
<item id="2" >
<sito url="http://www.adobe.com">Adobe</sito>
<descrizione>Sito ufficiale Adobe</descrizione>
</item>
<item id="3" >
<sito url="http://labs.adobe.com">Adobe Labs</sito>
<descrizione>Adobe Labs: risorse e anteprime Adobe</descrizione>
</item>
</dati>
</file_dati>
Qualora avessimo una fonte di dati di questo tipo, potremmo accedere ad esempio al tag item con attributo id uguale ad 1 semplicemente con il codice:
fileXML.dati.item(@id=="1")
Possiamo comunque basarci anche sugli attributi dei tag interni, per esempio se vogliamo ricavare il contenuto del tag <item> il cui tag interno <sito> abbia come valore "http://www.adobe.com" possiamo utilizzare:
fileXML.dati.item.(sito.@url == "http://www.adobe.com")
Una comoda scorciatoia
Abbiamo visto come accedere a tag ed attributi partendo dal nodo principale; come comportarci però se volessimo ad esempio ottenere tutti i tag descrizione presenti nel file, senza passare per i tag <dati> ed <item>? Per questo scopo è disponibile una dicitura che utilizza due punti invece che uno, utilizzabile così:
fileXML..descrizione
Possiamo tradurre i due punti con un "tutti i tag di nome...."; anche in questo caso possiamo identificare un tag preciso usando i numeri (es. fileXML..descrizione[0]) o eventualmente tramite un attributo.
Qualora invece volessimo conoscere il numero di tag <descrizione> presenti nel file XML, possiamo abbinare a tale dicitura la proprietà lenght(), in questo modo:
fileXML..descrizione.length()
Mettendo insieme quanto visto finora, possiamo creare un ciclo che permetta di ricavare tutte le informazioni di tutti i tag <item> del file con poche righe di codice:
dati = new Array()
for(n=0; n<numero_item; n++){
dati["sito"+n] = fileXML..item[n].sito.text()
dati["descr"+n] = fileXML..item[n].descrizione.text()
dati["url"+n] = fileXML..item[n].sito.attributes()
}
Sostituire i dati
Avendo a disposizione tutta la struttura del file XML e potendolo trattare come un oggetto ActionScript, possiamo non solamente leggere i valori dei diversi elementi, ma anche scriverli; chiaramente le variazioni saranno valide solo nel nostro oggetto, a meno che non salviamo poi fisicamente un file XML con la struttura modificata (processo realizzabile con un linguaggio server-side). Per cambiare il valore di un dato tag o attributo il percorso è ovviamente uguale a quello utilizzato per leggerlo; qualora volessimo ad esempio modificare il tag <sito> del primo tag <item>, potremmo usare:
fileXML..item[0].sito = "Modifica del tag"
Analogamente potremmo variare l'attributo url con:
fileXML..item[0].sito.@url = "Modifica attributo url"
Conclusioni
E4X rappresenta una vera e propria rivoluzione nel modo di gestire XML in ActionScript: la possibilità di avere tutta la struttura del file in un oggetto e poter "navigare" tra i tags, senza essere costretti all'uso di più comandi annidati, rappresenta un grosso passo avanti nel caricamento di feed RSS e di qualsiasi risorsa formattata in XML.
Particolarmente interessante la possibilità di manipolare rapidamente i contenuti dei tag, così da rendere molto facile un aggiornamento di un file esterno (combinando la cosa con un linguaggio server-side, per la scrittura del file).
Aggiungiamo a questo una miglior gestione degli errori e della loro "intercettazione", che permette di essere sicuri che il file che carichiamo sia ben formato.
Quanto trattato in questo articolo, è valido anche per Flex, poichè anch'esso sfrutta AS3, per cui chi volesse già utilizzare E4X può iniziare a sperimentare con Flex 2 le capacità di questo sistema. Per tutti i dettagli su E4X e sui relativi comandi, è consigliabile leggere il PDF, già segnalato a inizio articolo.

