
Qualsiasi uso si voglia fare di OrientDB - a documenti o a grafo - esistono dei concetti di base sulla memorizzazione dei dati che risultando in ogni caso fondamentali: classi, record e cluster. In questa lezione, verranno introdotte da un punto di vista teorico queste nozioni, in modo che sia chiaro il meccanismo di gestione dei dati attuato in OrientDB. Tutto ciò anche in preparazione alle operazioni su database che svolgeremo in linguaggio SQL, e che affronteremo successivamente nella guida.
Record e classi
Nella progettazione di un database relazione procederemmo nella maniera seguente. Per prima cosa, creeremmo una serie di tabelle definendone la struttura. Indicheremmo ogni campo in esse contenuto specificando tipi di dato e range di valori utilizzabili. Successivamente inizieremmo ad inserire al loro interno dei record. Ogni nuova riga della tabella dovrà quindi aderire alla sua struttura, mantenendo un certo numero e tipologia di campi, codifica e valori dei dati nonchè eventuali vincoli da rispettare.
In OrientDB, l'elemento base di memorizzazione è il record. Esso è costituito dall'aggregazione di più informazioni, ognuna appartenente ad un campo. Più record possono essere raggruppati in un cluster, che potremmo considerare il corrispondente della tabella del mondo relazionale. Ogni record è contraddistinto da un identificativo, detto record ID, espresso nel formato cluster-id:cluster-position: la prima parte indica il cluster di appartenenza, mentre la seconda rappresenta la posizione che il record assume all'interno di esso. Il record ID è obbligatorio, e viene pertanto assegnato in automatico.
Nei record, notiamo una delle più rilevanti differenze rispetto al modello relazionale: la non obbligatorietà della strutturazione dei dati. Ogni record deve appartenere ad una certa classe, ognuna delle quali non deve necessariamente avere una struttura interna. Qualora l'avesse inoltre, questa potrebbe essere più o meno flessibile in base alle necessità di ogni record.
Esistono infatti tre approcci alla strutturazione dei dati utilizzando le classi:
- schema-less: viene dichiarata una classe ma non la sua struttura interna. I record che le apparterranno potranno avere una struttura del tutto personalizzata;
- schema-full: viene definita la classe specificando le proprietà che le appartengono, i tipi di dato ed i range di valori di ognuno di essi. Tutti i record della classe dovranno avere la medesima struttura e non sarà possibile apportarle alcuna personalizzazione. Affinchè la classe operi in questa maniera è necessario abilitare lo strict-mode, che ne congelerà la struttura così come definita;
- schema-hybrid o schema-mixed: si basa su una definizione di proprietà interne della classe che ne
stabiliscono i tratti fondamentali, ma lascia libero il record di subire una personalizzazione idonea alla circostanza con l'introduzione di ulteriori proprietà. Per seguire questo funzionamento, non viene abilitato lo strict-mode. È l'approccio più comunemente utilizzato.
Le proprietà definite in una classe possono essere descritte opportunamente con degli attributi a partire dal tipo di dato cui devono attenersi.
Tipi di dato in OrientDB
OrientDB ha un gran numero di tipi di dato previsti, ad ognuno dei quali corrisponde una classe Java con i relativi range di valori consentiti ed eventuali classi verso la quali si può realizzare una conversione automatica. Tipi esistenti possono descrivere qualsiasi genere di informazione, e quello che segue è un elenco delle categorie più comuni:
- numeri interi: Byte, Short, Integer, Long. Rappresentano numeri interi con segno, rispettivamente, di uno, due, quattro e otto byte;
- numeri in virgola mobile: Float e Double, rispettivamente, a precisione singola e doppia;
- il tipo String per le stringhe;
- Boolean per i valori logici booleani;
- date e tempo: si utilizzano i tipi Date e Datetime, entrambi mappati sulla classe
java.util.Date; - strutture dati annidate: Embedded List, Embedded Set, Embedded Map;
- collegamenti ai nodi: Link List, Link Set, Link Map.
Un elenco completo dei tipi di dato supportati da OrientDB può essere reperito sulla documentazione ufficiale.
I cluster
Abbiamo visto che le classi hanno un valore per lo più concettuale, descrittivo del significato delle informazioni raccolte. Il luogo dove fisicamente vengono immagazzinati i dati sono i cluster, le vere e proprie "tabelle" fisiche. Affinchè possano essere raccolti record attinenti ad una certa classe, essa deve essere collegata almeno ad un cluster.
Alla stessa classe, possono corrispondere più cluster sui quali verranno distribuiti i record:
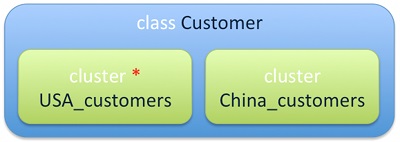
Nella figura, viene definita una classe, Customer, per contenere i dati dei clienti. I record ad essa appartenenti vengono disposti su due diversi cluster.
Nel primo, vengono inseriti i clienti residenti negli USA, nel secondo quelli provenienti dalla Cina. L'asterisco rosso posto vicino USA_customers serve a ricordare che quello è il cluster di default: tale ruolo viene sempre assegnato ad un cluster.
Quando effettueremo inserimenti, modifiche o interrogazioni sui record potremo specificare la classe di appartenenza in generale o il singolo cluster di riferimento. Infatti, un nuovo record creato viene sempre inserito nel cluster di default a meno di indicazioni contrarie da parte del programmatore. Quando viene invece effettuata una ricerca di record, se non si indica un cluster specifico, essa farà riferimento all'intero dominio della classe.
Partizionare i record su cluster si traduce in prestazioni migliori sotto vari punti di vista. Innanzitutto, se si conosce il cluster in cui può essere contenuto un record, la query potrà essere indirizzata solo a quel cluster, ottimizzando notevolmente le prestazioni. Ciò comporta tempi di esecuzione minori producendo una forma di ottimizzazione naturale e riducendo l'impiego di indici. Inoltre, dati divisi su più cluster agevolano lo sharding, la distribuzione di dati su più nodi di rete, favorendo la sicurezza dei dati e la parallelizzazione delle ricerche.
I cluster possono essere di due tipi: fisici (Physical cluster) o in memoria (Memory cluster). I primi sono la tipologia di default e vengono salvati in maniera persistente su file system. I secondi risiedono in memoria e pertanto sono di natura volatile: alla fine del processo in cui sono stati creati verranno cancellati.
