
Il nome per esteso è Microsoft Azure SQL Database, già noto come "SQL Azure" e più semplicemente chiamato in italiano anche database SQL. Si parla sempre però del DBMS (Database Managment System) relazionale fornito come servizio Cloud per l'archiviazione e l'interazione con i dati su piattaforma Microsoft Azure.
Parlare di Cloud, nell'ambito dei servizi, significa parlare di scalabilità, ed è proprio questo uno dei punti di forza più significativi di SQL Azure. Grazie ai "pool elastici", il servizio è in grado di sostenere incrementi repentini di accessi (passando per esempio da poche decine a migliaia di device connessi).
SQL Azure: DB e Cloud per tutti
Gli sviluppatori hanno la possibilità di realizzare soluzioni basate su tecnologie e linguaggi differenti (.NET, Java, NodeJS, PHP, Python, Ruby) utilizzando le librerie più diffuse per la connessione ai database come ADO.NET, JDBC, pymssql Python Driver, Tedious Node.js Drive e TinyTDS Ruby Driver per SQL Server.
Grazie all'Azure SQL Database Firewall è inoltre possibile garantire la sicurezza delle connessioni tra applicazioni e basi di dati attraverso delle regole di firewall che possono essere definite tramite API REST, PowerShell o più semplicemente utilizzando gli strumenti per la gestione del firewalling del portale di gestione di Azure; tali regole vengono utilizzate dal server e dal database per rifiutare i tentativi di connessione provenienti da indirizzi IP non autorizzati.
La cifratura SSL/TLS delle connessioni garantisce la protezione dei dati in transito da e verso il database contro possibili attacchi, mentre un sistema completo e automatizzato di backup ne permette il ripristino immediato.
Creazione di un database SQL in Azure
Per creare un database su SQL Azure è necessario accedere al portale Microsoft Azure e selezionare la voce "Database SQL" presente sulla sidebar dell'interfaccia di gestione; fatto questo si può cliccare su "Aggiungi" e procedere specificando prima un nome da associare alla base di dati, ad esempio "DbApp" e poi il tipo di sottoscrizione da utilizzare per il pagamento del servizio.
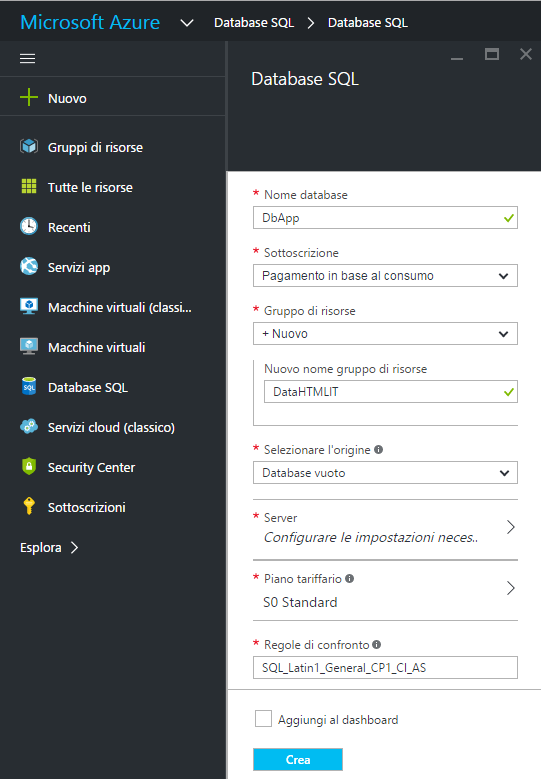
Se non si dispone di un gruppo di risorse a cui destinare il database, o se ne vuole generare uno appositamente dedicato, se ne dovrà indicare il nome, "DataHTMLIT" nel nostro esempio.
Nel passaggio successivo si sceglie l'origine per la base di dati. La scelta è tra:
- un database vuoto, quindi popolabile da zero tramite tabelle, campi e dati sulla base del progetto che si intende realizzare;
- un database di esempio, eventualmente personalizzabile;
- il backup di un database precedentemente realizzato.
Per rendere operativo il database occorre disporre di un server. Dopo aver selezionato l'origine della base di dati scegliendo, ad a esempio, "Database vuoto", si dovrà quindi cliccare su "Server" e decidere se creare un nuovo server o se adottarne uno già disponibile.
Per crearne uno è sufficiente dargli un nome, ad esempio "serverhtmlit", e inserire username e password dell'amministratore, "admhtml" nel nostro esempio.
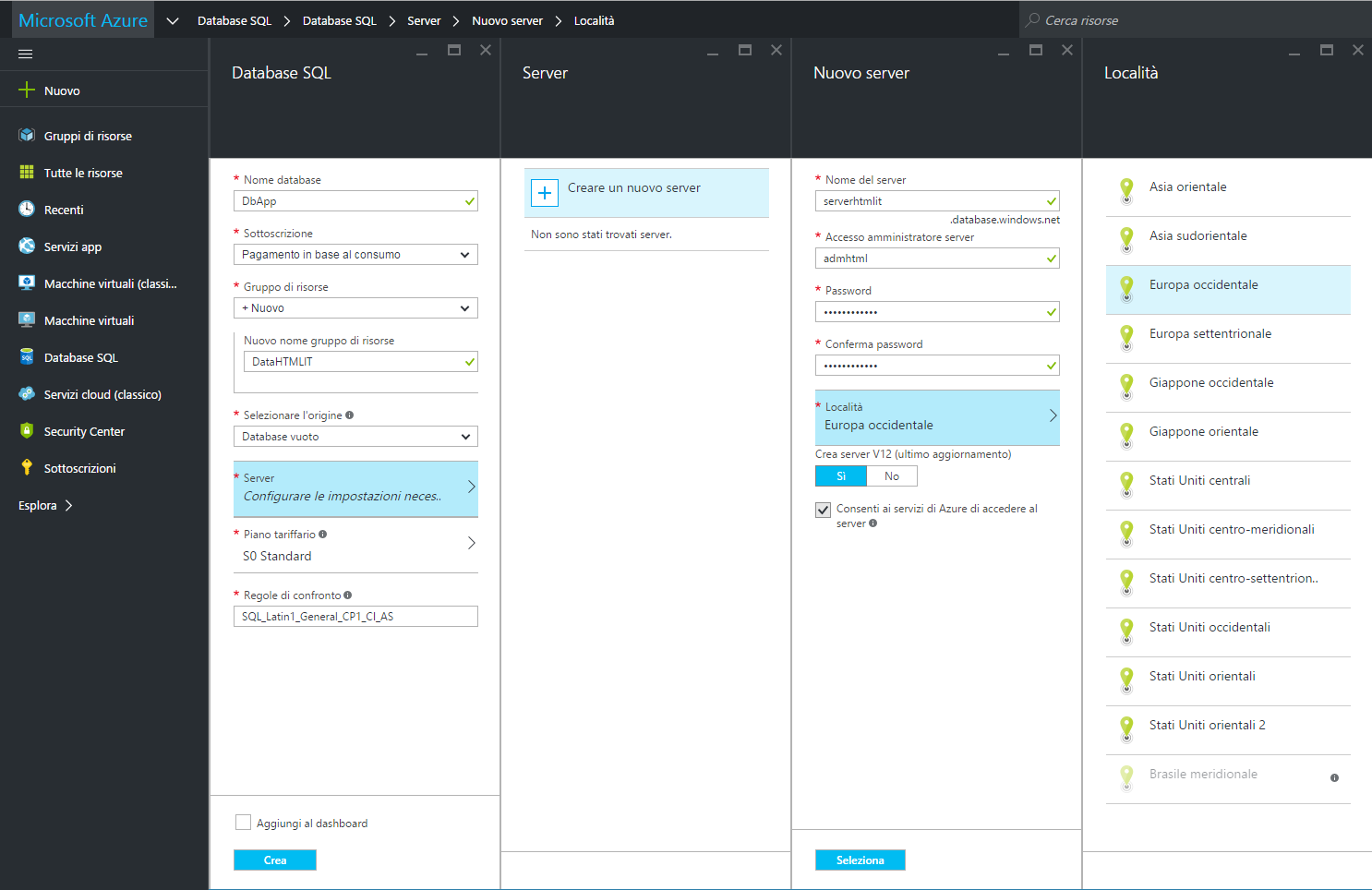
Infine bisogna indicare la località di riferimento del server, per esempio quella più vicina al proprio ambiente di produzione ("Europa Occidentale" nell'immagine), e specificare se si desidera consentire o meno ai servizi di Azure di accedere al server. Se questa autorizzazione (abilitata di default) non viene concessa da subito, avremo comunque la possibilità di modificare successivamente le regole firewall di SQL Server per il database creato.
Una volta indicato e selezionato il server da utilizzare, l'ultimo passaggio consiste nella selezione del piano tariffario da associare al database, che potrà essere scelto sulla base delle esigenze legate allo storage e alla quantità di DTU (Database Throughput Units) da impiegare.
DTU e le eDTU
Le DTU sono una metrica che viene utilizzata da Azure per misurare il carico su CPU, memoria RAM e prestazioni offerte dalle risorse disponibili nelle fasi di lettura e scrittura. Si può partire da una configurazione di base con il minimo di spazio di archiviazione e un numero ridotto di DTU per poi incrementare la propria dotazione con l'evolversi del progetto.
Nel caso dei pool elastici la quantità di risorse e performance che stiamo impiegando viene misurata in eDTU (Elastic DTU). In pratica ad un pool viene assegnato un numero predefinito di eDTU per un prezzo prestabilito: quando il carico di lavoro diventa rilevante, un database può utilizzare più eDTU, se il carico è più leggero i database utilizzano meno eDTU, in assenza di carico non ne utilizzano affatto.
Si possono inoltre aggiungere eDTU ad un pool senza causare inattività del database, nello stesso modo quando gli eDTU aggiuntivi non sono più necessari è possibile rimuoverli da un pool esistente.
Si possono infine aggiungere o rimuovere database da un pool così come rimuovere un database che sottoutilizza le proprie risorse.
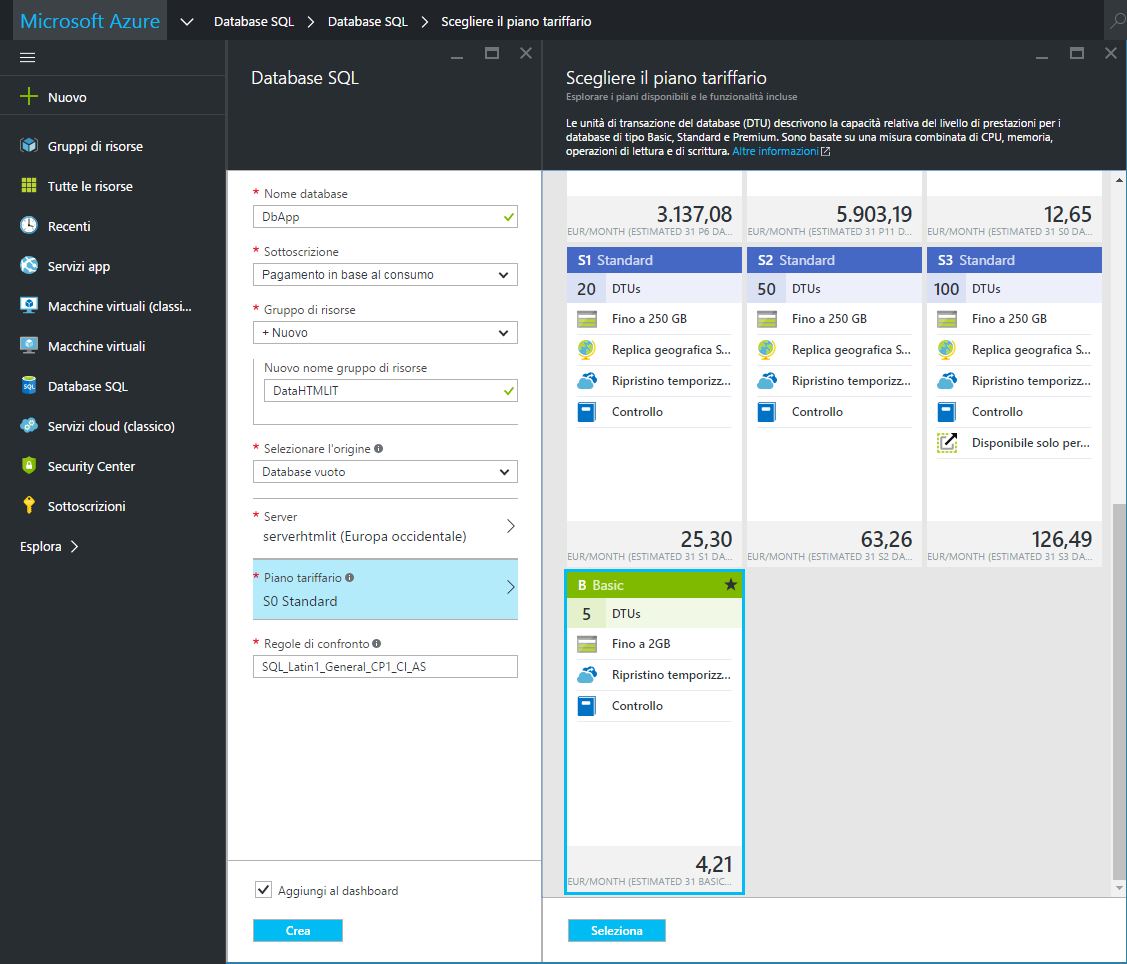
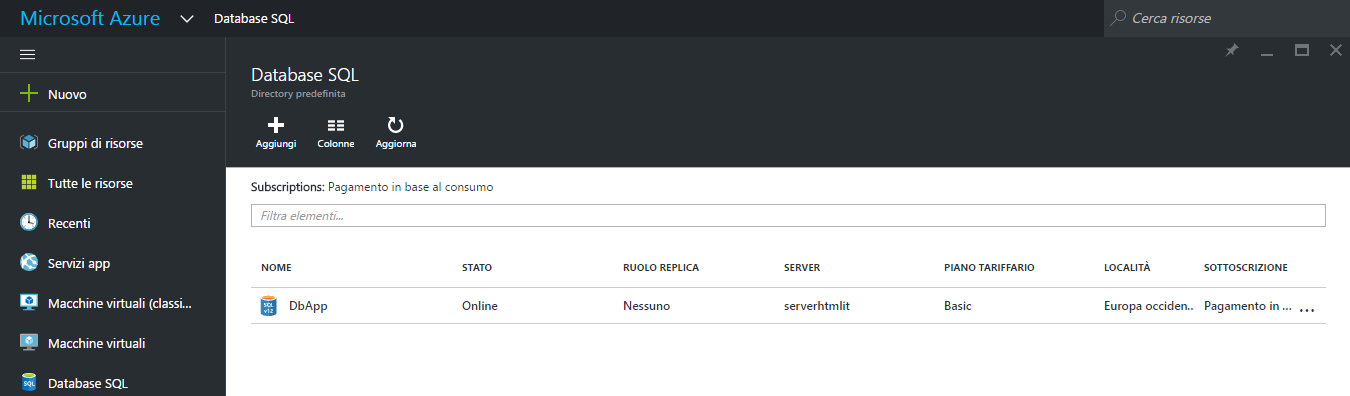
Terminata questa fase possiamo cliccare su "Crea" e generare il database, il gruppo di risorse e il server. La nuova base di dati risulterà ora disponibile nella sezione "Database SQL".
Operare sul database di Azure con Visual Studio
E' possibile manipolare le nostre basi di dati create su Azure SQL Database sfruttando Visual Studio e connetterci al nostro db dall'ambiente di sviluppo. Per fare questo accediamo al portale Azure e dalla sezione "Database SQL", clicchiamo su "Strumenti", quindi su "Apri in Visual Studio".
Azure provvede autonomamente all'avvio di Visual Studio e, una volta lanciato l'ambiente di sviluppo, ci viene richiesto di indicare i dati necessari per la connessione al server che ospita il database.
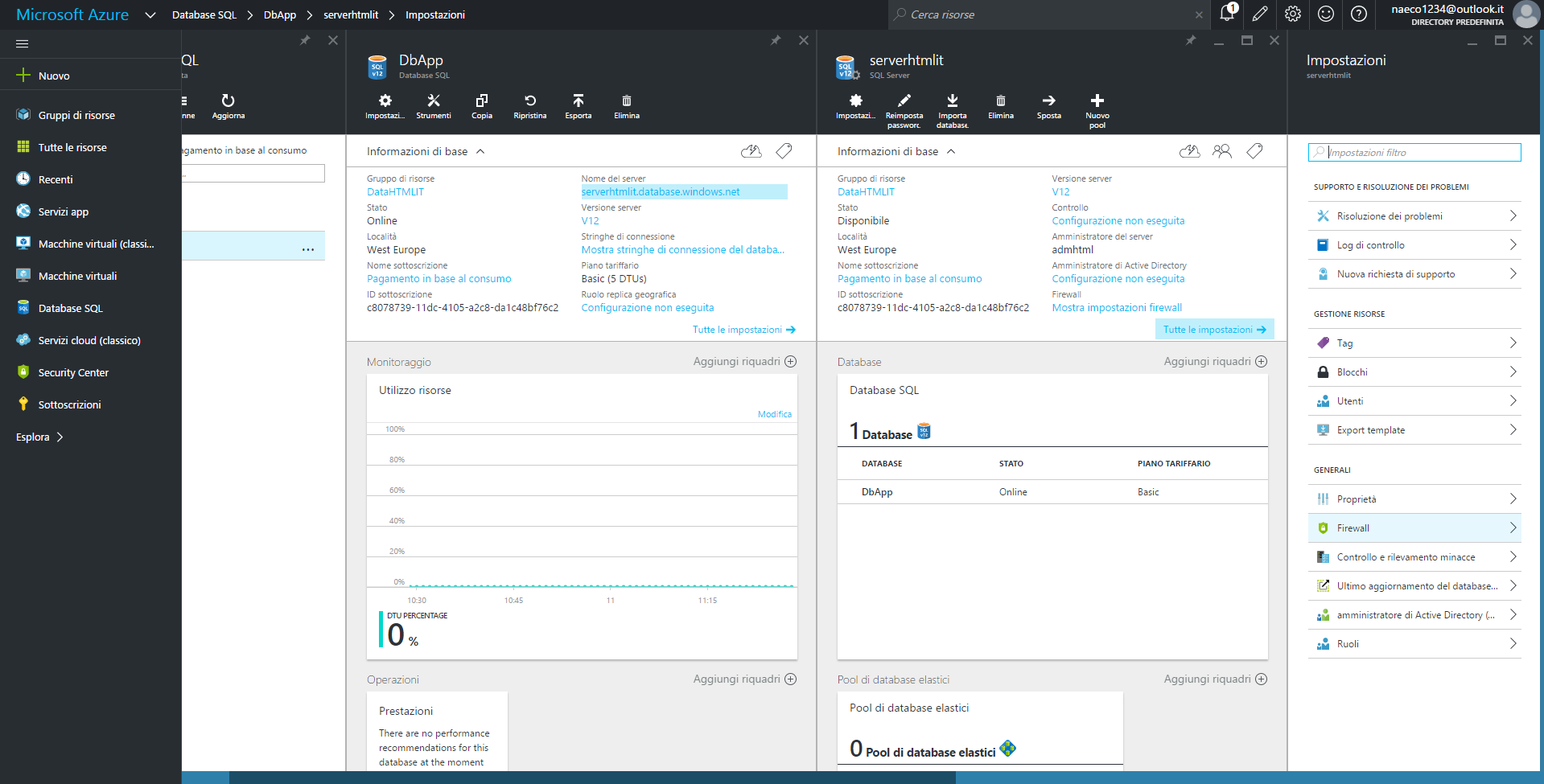
Poiché il client locale deve essere autorizzato ad operare su server e database remoti, è necessario creare una regola di Firewall (in Azure) che sblocchi il nostro indirizzo IP.
Per farlo clicchiamo sul link corrispondente al nome del server, "serverhtmlit.database.windows.net" nel nostro esempio, e poi sulla voce "Firewall", nelle impostazioni.
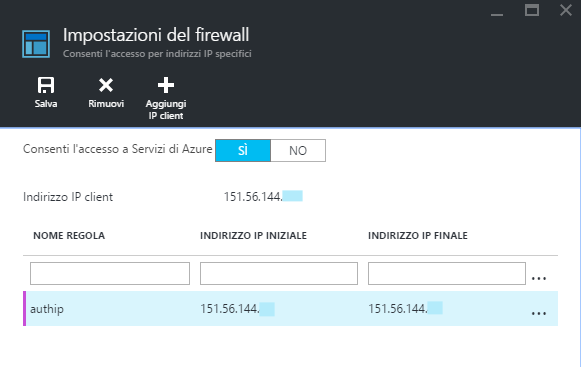
Fatto questo definiamo un intervallo (range) di IP che dovranno essere accettati dal servizio associando un nome alla nuova regola di Firewall, chiamata ad esempio "authip", che diventerà definitiva una volta salvata.
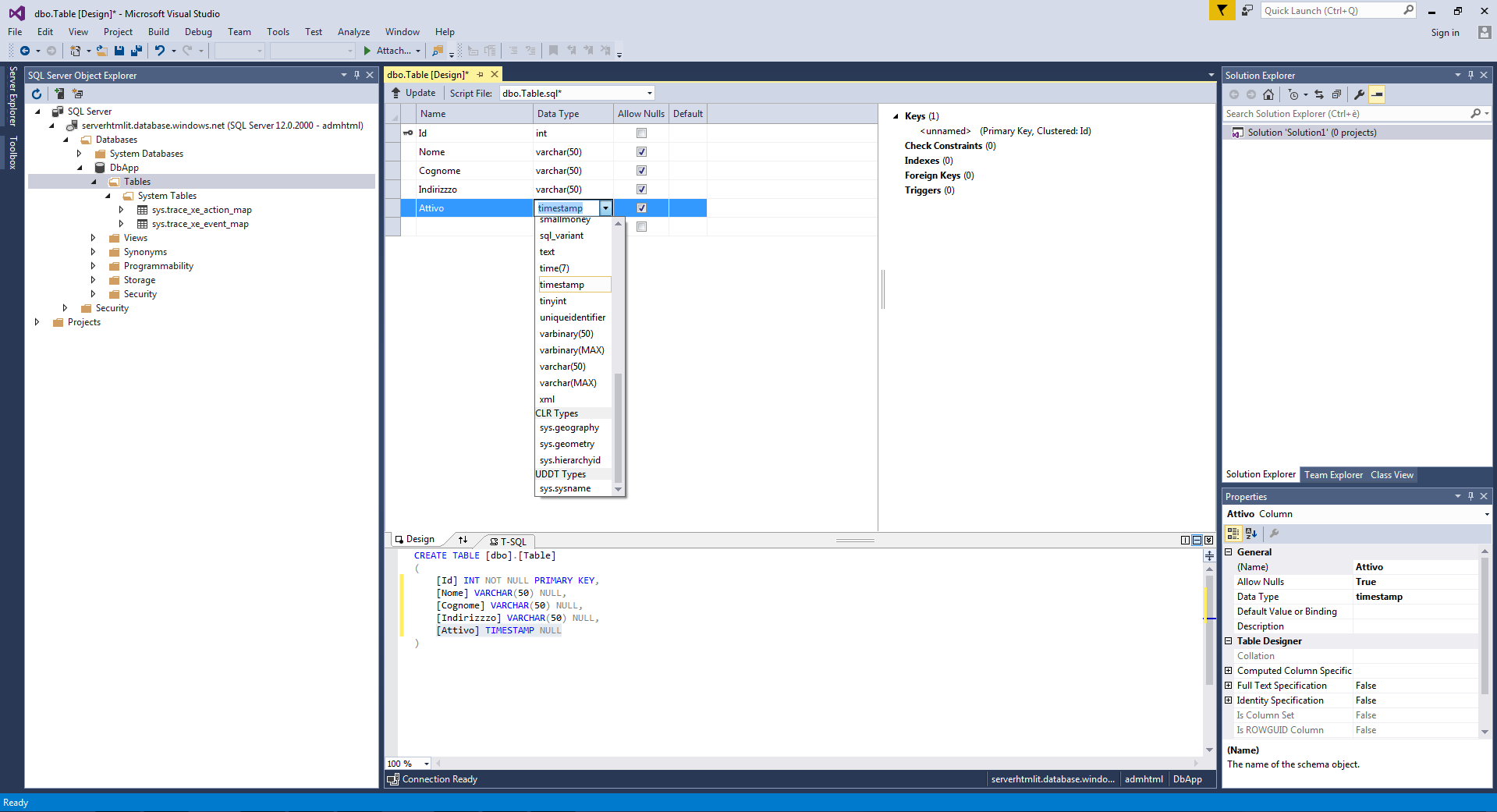
Autorizzato il nostro client possiamo cliccare su "Connect" dalla finestra di connessione aperta in Visual Studio e procedere con la gestione del database. Ad esempio possiamo aggiungere delle tabelle all'archivio.
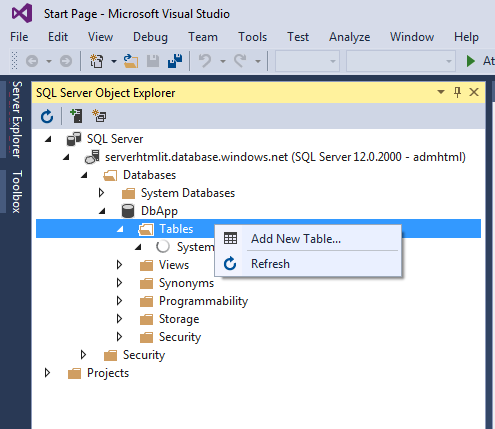
Nella figura seguente utilizziamo gli strumenti visuali di Visual Studio per aggiungere campi alla tabella di un database creato e funzionante su Azure, l'IDE produrrà automaticamente il codice SQL corrispondente alle istruzioni inviate.
Data Lake per l'analisi dei dati
Azure Data Lake è un servizio che fornisce una interfaccia centralizzata per archiviare e analizzare dati provenienti da fonti differenti; tutte le informazioni necessarie per il lavoro degli sviluppatori e degli analisti diventano accessibili da un unica posizione, caratteristica che si rivela particolarmente vantaggiosa nell'elaborazione di grandi volumi di dati (Big Data).
Si tratta di una piattaforma in grado minimizzare le complessità derivanti dalla gestione dei dati. Senza Azure Data Lake i flussi di informazione dovrebbero essere estratti manualmente da sorgenti differenti e poi combinati allungando eccessivamente i tempi di operatività, senza contare il necessario dispendio in termini di risorse.
Con Azure Data Lake, invece, tutti i dati risultano immediatamente disponibili, aggregati e combinati indipendentemente dalla loro fonte, si potranno quindi effettuare analisi e generare report senza overhaed. L'integrazione di Azure Active Directory permette inoltre di gestire accessi e ruoli con il proprio sistema locale per la gestione delle identità, l'utilizzatore può quindi proteggere i dati tramite applicativi a lui familiari.
Azure Data Lake è stato realizzato sulla base dell'esperienza maturata nel gestire alcuni dei servizi business-critical del network di Microsoft come Office 365, Xbox Live, Windows, Bing e Skype. Il servizio si basa su Apache YARN, una tecnologia aperta per il cluster management grazie alla quale ci si può concentrare sulla scrittura delle query per la trasformazione dei dati e non sulla configurazione dell'hardware.
Con il servizio è poi incluso il linguaggio U-SQL il cui runtime permette di analizzare i dati disponibili su istanze SQL Server in Azure, SQL database e Azure SQL Data Warehouse; a questi si aggiunge Archivio Data Lake, un singolo repository per acquisire dati di qualsiasi dimensione e tipo.
U-SQL, Apache Hive e Apache Storm consentono di monitorare l'esecuzione del codice e di identificare i colli di bottiglia a danno di prestazioni e costi, facilitando l'ottimizzazione delle query. Sviluppatori e DBA possono utilizzare soluzioni conosciute come SQL, Hadoop, Apache Spark e .NET per essere produttivi sin da da subito. Gli analisti possono sfruttare le proprie competenze su Spark o strumenti di visualizzazione come ad esempio Power BI.
Gli strumenti per l'analisi di Azure Data Lake permettono di gestire qualsiasi processo semplicemente definendo la potenza desiderata, si pagheranno soltanto le risorse utilizzate in fase di esecuzione.
SQL Data Warehouse
Fortemente integrato con Azure Data Lake tramite la tecnologia Cortana Intelligence Suite, Azure SQL Data Warehouse è un soluzione completa per archiviare i dati della propria organizzazione, informazioni fondamentali per il supporto ai processi decisionali.
Questa piattaforma si basa sul medesimo motore di storage del database relazionale di SQL Server fornendo funzionalità avanzate come le stored procedure, la possibilità di utilizzare funzioni definite dall'utente, il partizionamento delle tabelle, gli indici e le regole di confronto per i dati.
Azure SQL Data Warehouse è un servizio che permette di spostare facilmente i dati e i processi di estrazione, trasformazione e caricamento tra i sistemi locali e il Cloud. A differenza di altri data warehouse che operano sul Cloud e che richiedono diverso tempo per le attività di ridimensionamento, questa soluzione consente di aumentare o ridurre rapidamente la potenza di calcolo in base al mutare delle proprie esigenze in termini di performance.
Grazie al supporto per la tecnologia PolyBase si può utilizzare Transact-SQL per le query a database relazionali e non relazionali in formato Hadoop; si possono quindi eseguire operazioni per il data mining, effetturare analisi, creare reportistica utilizzando le proprie competenze su T-SQL.
Per quanto riguarda la sicurezza e l'integrità dei dati, Azure SQL Data Warehouse genera backup predefiniti dei database con i quali operare rapidi ripristini in autonomia. La piattaforma crea automaticamente le copie di sicurezza archiviandole sul Cloud di Azure e delle istantanee (snapshot) dei punti di ripristino delle basi di dati.
SQL Data Warehouse utilizza l'architettura MPP (Massively Parallel Processing) di Microsoft per garantire un rapporto qualitativamente elevato tra prezzo e prestazioni per l'elaborazione delle query; grazie agli indici columnstore di SQL Server residenti in memoria e alla componente Query Optimizer l'utilizzatore pagherà unicamente per il tempo necessario ad eseguire le analisi e non per la configurazione dell'hardware.
La tariffazione è commisurata alle performance necessarie per eseguire le principali operazioni di data warehousing, come la scansione, il caricamento e l'elaborazione delle query. Durante la sospensione delle attività di calcolo si pagherà unicamente per l'archiviazione dei dati.
